适合面向ChatGPT编程的架构示例详解
目录
- 新的需求
- 领域知识
- 架构设计
- 管道架构
- 分层架构
- 类分层神经网络的架构
- 总结一下
新的需求
我们前面爬虫的需求呢,有些平台说因为引起争议,所以不让发,好吧,那我们换个需求,本来那个例子也不好扩展了。最近AI画图也是比较火的,那么我们来试试做个程序帮我们生成AI画图的prompt。
首先讲一下AI话题的prompt的关键要素,大部分的AI画图都是有一个个由逗号分割的关键字,也叫subject,类似下面这样:
a cute cat, smile, running, look_at_viewer, full_body, side_view,
然后还有negative prompt,就是你不想出现的关键字,跟上面的写法一样,只是写下来表示不希望它画出来的,比如我们想画一堆猫的图片,不想出现狗,不想出现人,我们可以这么写:
dog, human,
这样大概率就不会出现狗和人了(当然也不一定,懂得都懂)。
这些prompt扔给AI,我们可能得到下面这么一张图:

但也可能会得到下面这么一张图:

后面这张让人san值狂减啊有没有,所以说关键字的使用上还是有些学问的,我得好好研究研究。一研究我才发现,这玩意生成速度太慢了,我做一个试验几秒钟过去了,然后才能做下一个。这就把我锁在这电脑前面了,走也不是,等也不是。我大好的人生怎么能浪费在这些事情上?啊不高~兴!
这时我想到,我是个程序员啊。那假如,我有一个可以排列组合各种关键字帮我生成prompt的程序,让它一个个去试验,最后我只要看看哪个图片比较靠谱,反过来看看哪些关键字组合更好用,岂不是美滋滋?
领域知识
那么说干就干,开始之前要了解一下领域知识。
首先是关键字,在这个需求里只是基础知识,没有什么难的,大概有下面几条规则:
- 内容,这些关键字呢,说是关键字,其实你写一句话也没人管你。简化处理,我们这里就只用词和短语。另外,空格可以用下划线代替,这样可能会避免被分词,具体我也不确定,没有深入研究。但是这个不重要,可以完全看成两种关键字去排列组合好了。
- 关键字是可以有权重的,通常的表达方式是:
(a cute cat:1.5)
这个很重要,通常我们想尝试好的方式,需要给每个关键字设置权重。
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术,在我们这个场景下就是我们多了一种关键字,这种关键字大概是这么写:
<lora:wanostyle_2_offset:1>, monkey d luffy,
- 它多了一些尖括号,也有权重,同时他会被其他关键字触发,比如上面这个就可以画个海贼王风格的路飞出来。
- 但总的来说,对关键字本身的建模影响不大
接着我们来了解一下排列组合的逻辑,这个将是我们的关键难点。
- 在这个领域,影响生成的因素主要有几个:
- 模型
- sample
- step
- 宽高
- seed
- negative prompt
- prompt
- 在prompt中我们的关键字还可以根据使用目的分类,比如于生成画面风格的、用于生成背景的、用于生成人物的、用于成表情的等等
- 在prompt中,关键字的摆放顺序有时候还会造成点不同。
- 还有更复杂的Control Net,这个例子里我们先不考虑。
- 生成的时候,某些关键字要获得最好的效果,可能自己对模型、sample以及其他关键字的存在和权重都有自己的要求,比某关键字在某模型下权重为0.3,而在另一个模型下权重需要0.7。比如路飞会带草帽,那么这个人物出现的时候,必须配上帽的关键字才对味,而其他的人物就不要跟草帽组合了,又浪时间又没有意义。所以组合上要考虑各种因素之间的互斥和强依赖等场景。
架构设计
好,这大概是一个比较复杂的需求了。回到上篇文章遗留的问题,聊聊当我们面对一个比较复杂的需求,而且我们接下来要用ChatGPT把它实现的时候,我们应该怎么设计架构。
管道架构
在这个需求里,我们首先要知道,这类AI都是有REST API的,比如说stable diffusion WebUI,就有一个自己的API,他们的API接受一个固定格式的JSON,其结构大概是这个样子:
{
"prompt": "",
"negative_prompt": "",
"controlnet_input_image": [],
"controlnet_mask": [],
"controlnet_module": "",
"controlnet_model": "",
"controlnet_weight": 1,
"controlnet_resize_mode": "Scale to Fit (Inner Fit)",
"controlnet_lowvram": true,
"controlnet_processor_res": 512,
"controlnet_threshold_a": 64,
"controlnet_threshold_b": 64,
"controlnet_guidance": 1,
"controlnet_guessmode": true,
"enable_hr": false,
"denoising_strength": 0.5,
"hr_scale": 1.5,
"hr_upscale": "Latent",
"seed": -1,
"subseed": -1,
"subseed_strength": -1,
"sampler_index": "",
"batch_size": 1,
"n_iter": 1,
"steps": 20,
"cfg_scale": 7,
"width": 512,
"height": 512,
"restore_faces": true,
"override_settings": {},
"override_settings_restore_afterwards": true
}
那么这就是类似他们的意图描述,可以把它看成一种DSL。
而在我们这个领域里,我们要做的是排列组合,那么对于排列组合,我们要设计我们排列组合的意图描述,这可以看成另一种DSL,这种DSL只作简单排列组合,不做复杂的互斥和强依赖逻辑的计算,其结构可能是这个样子:
- base_share_composite_intentions:
base:
steps: 10
batch_size: 1
width: 512
height: 512
cfg_scale: 7
sampler: "Euler a"
seed: -1
restore_faces: true
output_folder: output/txt2img
file_full_name_strategy: date_seed_name_strategy
sd_host: http://localhost:7860
negative_prompt: a dog
poly:
- template_prompt:
template: >
a cat,
${ view_angle }
${ portrait }
${ facial_expressions }
${ pose }
meta:
- view_angle:
- side_view,
- front_view,
portrait:
- full body,
facial_expressions:
- (smile:1.5),
- (smile:1.2),
- smile,
pose: ""
- view_angle:
- front_view,
portrait:
- ""
facial_expressions:
- smile,
pose:
- run,
- jump,
- rolling,
steps: 20
然后在这个DSL之上,我们可以再做一个DSL,这个DSL用于处理复杂的互斥和强依赖逻辑的计算,前面说了那么多,真正这个地方到底有多复杂我也想不清楚。那干脆,搞个模板引擎来吧,这就什么都能干了,慢慢搞明白了再封装。最终其结构可能是这个样子:
<%
const randomNum = Math.floor(Math.random() * 900000000) + 100000000;
var intention = {
is_override_settings: true,
seed: randomNum,
}
%>
<% var status = {
charas:{
values_of_chara_$ref: [
"cats.yml#Abyssinian",
"cats.yml#cats_in_boots",
],
current_chara_index: 0,
next_chara(){
this.current_chara_index++;
}
},
themes:{
values_of_theme: [
{
$ref: "outdoor"
},
],
current_theme_index: 0,
next_theme(){
this.current_theme_index++;
},
reset_theme(){
this.current_theme_index = 0;
}
}
}
%>
<%
common_theme_file = "common/chara_based_themes.yml"
%>
<% while (status.charas.current_chara_index < status.charas.values_of_chara_$ref.length) { %>
- base_share_composite_intentions:
common:
theme:
base:
steps: 20
batch_size: 1
width: 512
height: 512
cfg_scale: 7
sampler: "DPM++ 2M Karras"
seed: <%- intention.seed %>
restore_faces: false
output_folder: output/txt2img
file_full_name_strategy: date_seed_name_strategy
sd_host: http://localhost:7860
<% if(intention.is_override_settings){ %>
override_settings:
CLIP_stop_at_last_layers: 2
eta_noise_seed_delta: 31337
<%}%>
negative_prompt: >
dog, human, bad anatomy, EasyNegative,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality,
poly:
<% while (status.themes.current_theme_index < status.themes.values_of_theme.length) { %>
- $p_ref:
$ref: "<%-common_theme_file%>#<%- status.themes.values_of_theme[status.themes.current_theme_index].$ref%>"
params:
base_prompt_features:
$p_ref:
$ref: <%- status.charas.values_of_chara_$ref[status.charas.current_chara_index] %>
params:
is_full_chara: true
chara_weight: 0.2
pose:
sit
facial_expressions:
(smile:1.1),(open mouth),
- $p_ref:
$ref: "<%-common_theme_file%>#<%- status.themes.values_of_theme[status.themes.current_theme_index].$ref%>"
params:
base_prompt_features:
$p_ref:
$ref: <%- status.charas.values_of_chara_$ref[status.charas.current_chara_index] %>
params:
is_full_chara: true
chara_weight: 0.6
pose:
run
facial_expressions:
(smile:1.2),(closed mouth),
<% status.themes.next_theme(); %>
<% } %>
<% status.themes.reset_theme(); %>
<% status.charas.next_chara(); %>
<% } %>
于是我们有了三个DSL,他们层层转换,最终驱动AI画图。那么我们的程序可能就会是下面这个样子:

可以看出,这样我们就得到了大名鼎鼎的管道架构,经常使用Linux/Unix命令行的人,可能已经体会过管道架构恐怖的扩展能力,这次我们只能说,是Linux/Unix哲学再一次展现出威力。
我们之前讲了,ChatGPT可以快速写出一些小程序,但是长一点的总是会出错,那么其实除了从规模上进行分解将任务复杂度降低之外,通过抽象建立分层的DSL也是一种降低复杂度的方案。
分层架构
说到分层,其实从另一个角度看,我们这个架构也是一个分层架构。

可以看到,我们可以轻易地替换调用不同REST API的代码以做到对于不同AI的适配,实现了隔离。
同理,不但意图执行可以切换,意图描述也可以跟着切换:

既可以有技术维度上的扩展,也可以有业务维度上的扩展:

所以从这个角度来说,每一个管段,都是可以看作是一层。
类分层神经网络的架构
而到这还不算完,具体在执行的时候,可能受环境的影响,可能受上层意图影响等等,总之是需要进行每一层的路径选择的。这种选择,可能是由另一个引擎来完成的。那么最终我们的架构的完整形态他可能是这个样子的:
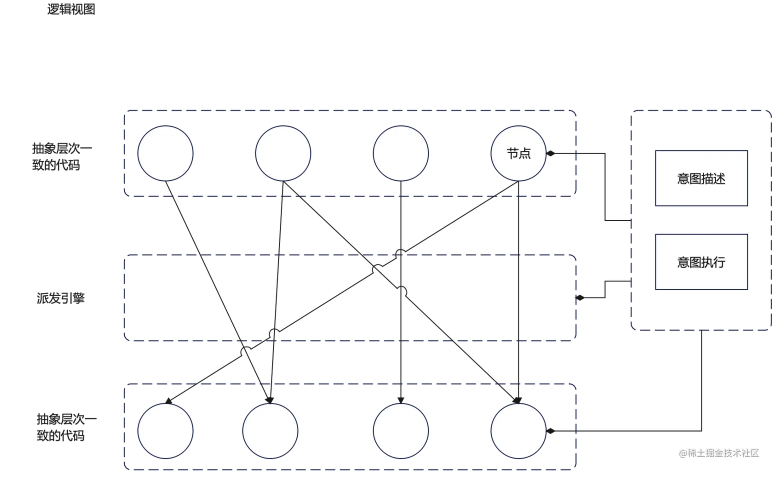
当然其运行视图可能是这样的:
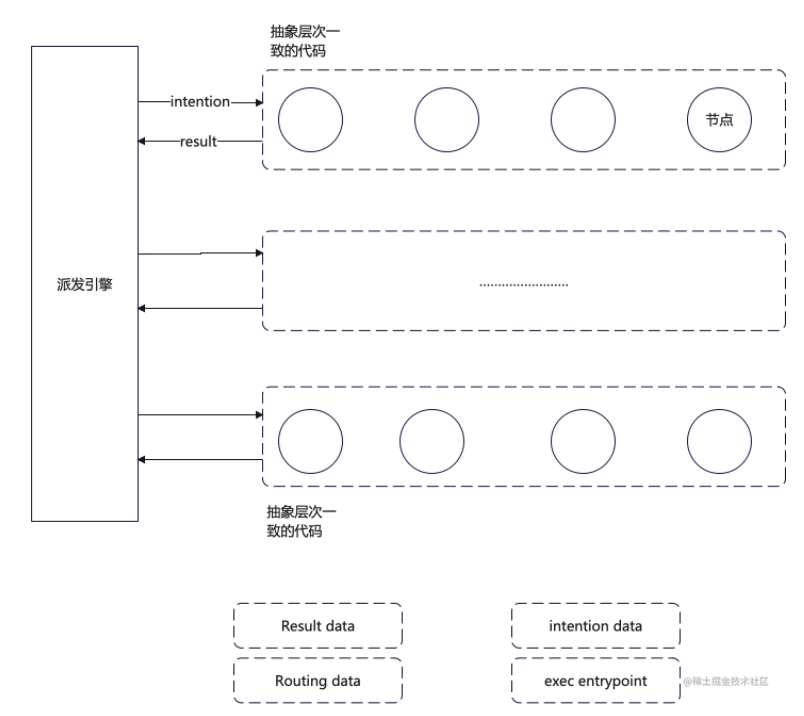
到此,我们得到了我们架构比较完整的形态,他是一个集成了管道架构和分层架构,在一个派发引擎的支撑下的一个类分层神经网络的结构。(还别说,这个结果还挺有点分形的味道)
总结一下
跟上一篇文章比起来,我们这篇文章的代码写的更少了(难道这就是ChatGPT时代的宿命吗^_^)。
我们引入了一个新需求,这个新需求有更多的排列组合逻辑在其中,其测试也更容易在本地完成。基于这个复杂的排列组合逻辑的问题域,我们在开始之前做了一个架构设计。因为我们这篇文章是用ChatGPT写程序,这个架构设计自然是为了能用ChatGPT把这个复杂的程序给写出来,所以我们整篇文章只讲了应该设计一个怎样的架构。
之所以这么设计架构,是因为ChatGPT只能做简单程序的代码编写,但是我们不能因此放弃使用它。毕竟人类社会也没有因为蒸汽机车不如马耐颠所以放弃蒸汽机车继续用马车,我们为了使用它的优势为他修了路。那么放到软件领域,就是要为它设计适合它的架构,以最大限度的发挥它的优势,规避它的劣势。
所以我们采用了分层架构+管道架构两种架构模式的组合搭建了一个类分层神经网络的架构。尽管这个架构要达到最完美的形态,我们需要把那个派发引擎做出来,但是即便没有那个派发引擎,剩下的两个模式的组合也足以使得我们可以在横向上按照代码规模进行分解,在纵向上按照抽象层次进行分解,从而把需求的复杂度分解为一个个可以由ChatGPT完成的任务了。
那么接下来,我们就可以动手工作了,我们下一篇文章讲讲开发这其中的每一个节点有什么套路。
以上就是适合面向ChatGPT编程的架构示例详解的详细内容,更多关于面向ChatGPT编程架构的资料请关注我们其它相关文章!
相关推荐
-
ChatGPT如何写好Prompt编程示例详解
目录 引言 好的 prompt 具有的设计原则 编写良好prompt的四种基础模式 编写一个合格的prompt的要点 让AI扮演角色 明确提供要执行的任务 给出完成任务的步骤 围绕任务提供上下文 陈述具体目标,给出具体要求 要求格式化输出 明确指定语言风格 让AI站在人物的角度,而非上帝视角 马上给出具体的样例 小结 引言 现在已经产生了一种新职业:Prompt Engineer(提示指令工程师),可见 Prompt 是多么重要,且编写不易. ChatGPT的产出,一半决定于它的实力,一半决定于
-
ChatGPT编程秀之最小元素的设计示例详解
目录 膨胀的野心与现实的窘境 新时代,新思路 总结一下 膨胀的野心与现实的窘境 上一节随着我能抓openai的列表之后,我的野心开始膨胀,既然我们写了一个框架,可以开始写面向各网站的爬虫了,为什么只面向ChatGPT呢?几乎所有的平台都是这么个模式,一个列表,然后逐个抓取.那我能不能把这个能力泛化呢?可不可以设计一套机制,让所有的抓取功能都变得很简单呢?我抽取一系列的基础能力,而不管抓哪个网站只需要复用这些能力就可以快速的开发出爬虫.公司内的各种平台都是这么想的对吧? 那么我们就需要进行设计建模
-
ChatGPT编程秀之跨越认知边界
目录 作者说 碰到了认知边界 跨越认知边界 总结一下 作者说 最近要忙了,日更的日子要到头了.后面每一篇讲的点就小一点吧,大的点等后面有空了再写.大家见谅. 碰到了认知边界 我的有的朋友跟我说,用ChatGPT编程需要你至少要跟他对等水平,因为现阶段我们还不能做到完全不需要关心它写出来的代码,当你要读懂它写的代码的时候,就必须能力对等.还有的朋友跟我说,ChatGPT的不能超过你的认知水平,你的认知水平的上限决定了它的表现,比如你认知水平不行,导致自己不能分解任务的时候,那么你用ChatGPT也
-
ChatGPT前端编程秀之别拿编程语言不当语言
目录 TDD第一步就卡住了 破门而入,针对性反馈 总结一下 TDD第一步就卡住了 写完小工具,这一篇回来我们接着写我们的程序.再看一眼我们的程序运行视图: 带着TDD思路,我进入了 ejs_and_yaml_dsl_loader 这个模块,这块因为我切的不是很好,所以这代码有点难写,不过没关系,正好我们实际工作大部分的场景都是这样的.看看我们在这里能玩出点什么来. 那么这次的需求呢是这个样子的,我们需要把ejs模版引擎渲染出的yaml转换为json,那么我们这个功能会非常复杂,所以我们没有以上来
-
从一个爬虫开始ChatGPT的编程秀
目录 思考问题域 用ChatGPT写一个爬虫 1. 先写一个框架 2. 在这个框架上,开发爬虫 3. 回到任务1的问题域 4. 最后回到具体的爬虫代码 回顾一下,我们做了什么,得到了什么? 思考问题域 我要写一个爬虫,把ChatGPT上我的数据都爬下来,首先想想我们的问题域,我想到几个问题: 不能用HTTP请求去爬,如果我直接 用HTTP请求去抓的话,一个我要花太多精力在登录上了,而我的数据又不多,另一个,现在都是单页引用,你HTTP爬下来的根本就不对啊. 所以最好是自动化测试的那种方式,启动浏
-
适合面向ChatGPT编程的架构示例详解
目录 新的需求 领域知识 架构设计 管道架构 分层架构 类分层神经网络的架构 总结一下 新的需求 我们前面爬虫的需求呢,有些平台说因为引起争议,所以不让发,好吧,那我们换个需求,本来那个例子也不好扩展了.最近AI画图也是比较火的,那么我们来试试做个程序帮我们生成AI画图的prompt. 首先讲一下AI话题的prompt的关键要素,大部分的AI画图都是有一个个由逗号分割的关键字,也叫subject,类似下面这样: a cute cat, smile, running, look_at_viewer
-
Python面向对象编程repr方法示例详解
目录 为什么要讲 __repr__ 重写 __repr__ 方法 str() 和 repr() 的区别 为什么要讲 __repr__ 在 Python 中,直接 print 一个实例对象,默认是输出这个对象由哪个类创建的对象,以及在内存中的地址(十六进制表示) 假设在开发调试过程中,希望使用 print 实例对象时,输出自定义内容,就可以用 __repr__ 方法了 或者通过 repr() 调用对象也会返回 __repr__ 方法返回的值 是不是似曾相识....没错..和 __str__ 一样的
-

Kotlin编程条件控制示例详解
目录 本文总览 1. When 表达式 2. If 表达式 总结 本文总览 本篇来看看 Kotlin的条件控制,这一节知识点 建议与Java中的条件结构类比,会很好理解并记住. 1. When 表达式 在 Kotlin 用 when 来定义多个分支的条件表达式.Kotlin中这个语法与 java 中的 switch 语句非常类似.代码块的执行就是将参数与所有的分⽀条件顺序⽐较,直到满⾜某个分⽀条件:(示例 ) when (x) { 1 -> print("x == 1") 2 -
-
Kotlin编程基础数据类型示例详解
目录 本文总览 1.数值类型 2.布尔型 3.字符串 3.1 字符串字面值 3.2 字符串模板 4.数组 4.1 普通数组 4.2 原⽣类型数组 5.类型检测和类型转换 5.1 智能转换 5.2 is 与 !is 操作符 5.3 转换操作符: as 与 as? 总结 本文总览 上一篇学习了Kotlin基础语法知识,本篇开始会深入探讨一下Kotlin各个基础语法点.首先来熟悉Kotlin的数据类型和类型转换版块. 1.数值类型 在Kotlin中提供了数值类型: 整数类型:Byte,Short,In
-
go语言编程实现递归函数示例详解
目录 前言 函数中的 return 递归的问题 总结 前言 本篇文章主要是记录一下在 GScript 中实现递归调用时所遇到的坑,类似的问题在中文互联网上我几乎没有找到相关的内容,所以还是很有必要记录一下. 在开始之前还是简单介绍下本次更新的 GScript v0.0.9 所包含的内容: 支持可变参数 优化 append 函数语义 优化编译错误信息 最后一个就是支持递归调用 先看第一个可变参数: //formats according to a format specifier and writ
-
java异步编程CompletableFuture使用示例详解
目录 一.简单介绍 二.常见操作 1.使用默认线程池 2.使用自定义线程池 3.获取线程的执行结果 三.处理异步结算的结果 四.异常处理 五.组合 CompletableFuture 六.并行运行多个 CompletableFuture 七.案例 1.从多个平台获取书价格 2.从任意一个平台获取结果就返回 一.简单介绍 CompletableFuture 同时实现了 Future 和 CompletionStage 接口. public class CompletableFuture<T> i
-
Spring AOP面向切面编程实现原理方法详解
1. 什么是AOP AOP (Aspect Oriented Programming)意为:面向切面编程,通过预编译方式和运行期动态代理实现在不修改源代码的情况下,给程序动态统一添加功能的一种技术,可以理解成动态代理.是Spring框架中的一个重要内容.利用 AOP 可以对业务逻辑的各个部分进行隔离,使业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高开发的效率 2. Spring AOP ①. AOP 在Spring中的作用 提供声明式事务:允许用户自定义切面 ②. AOP 的基本概
-
C++11模板元编程-std::enable_if示例详解
C++11中引入了std::enable_if函数,函数原型如下: template< bool B, class T = void > struct enable_if; 可能的函数实现: template<bool B, class T = void> struct enable_if {}; template<class T> struct enable_if<true, T> { typedef T type; }; 由上可知,只有当第一个模板参数为
-
python多线程编程方式分析示例详解
在Python多线程中如何创建一个线程对象如果你要创建一个线程对象,很简单,只要你的类继承threading.Thread,然后在__init__里首先调用threading.Thread的__init__方法即可 复制代码 代码如下: import threading class mythread(threading.Thread): def __init__(self, threadname): threading.Thread.__init__(self, name = thread
-
Spring AOP面向切面编程实现及配置详解
动态代理 特点 字节码随用随创建,随用随加载 作用 不用修改源码对方法增强 分类 基于接口的动态代理 基于子类的动态代理 创建 使用Proxy类中的newProxyInstance方法 要求 被代理类最少实现一个接口,没有则不能使用 newProxyInstance方法参数 classLoader:类加载器 用于加载代理对象字节码的,和被代理对象使用相同的类加载器 class[ ]:字节码数组 用于让代理对象和被代理对象有相同方法,固定写法. InvocationHandler:用于提供增强的代