书写Python代码的一种更优雅方式(推荐!)
目录
- 1 简介
- 2 在Python中配合pipe灵活使用链式写法
- 2.1 pipe中常用的管道操作函数
- 2.1.1 使用traverse()展平嵌套数组
- 2.1.2 使用dedup()进行顺序去重
- 2.1.3 使用filter()进行值过滤
- 2.1.4 使用groupby()进行分组运算
- 2.1.5 使用select()对上一步结果进行自定义遍历运算
- 2.1.6 使用sort()进行排序
- 总结
1 简介
一些比较熟悉pandas的读者朋友应该经常会使用query()、eval()、pipe()、assign()等pandas的常用方法,书写可读性很高的「链式」数据分析处理代码,从而更加丝滑流畅地组织代码逻辑。
但在原生Python中并没有提供类似shell中的管道操作符|、R中的管道操作符%>%等语法,也没有针对列表等数组结构的可进行链式书写的快捷方法,譬如javascript中数组的map()、filter()、some()、every()等。
正所谓“标准库不够,三方库来凑”,Python原生对链式写法支持不到位没关系,我们可以使用一些简单方便且轻量的第三方库来协助我们在Python代码中大面积实现链式写法,今天的文章中我就将带大家一起学习相关的知识技巧~
2 在Python中配合pipe灵活使用链式写法
我们将使用到pipe这个第三方库,它不仅内置了很多实用的「管道操作函数」,还提供了将常规函数快捷「转换」为管道操作函数的方法,使用pip install pipe对其进行安装即可。
pipe的用法非常方便,类似shell中的管道操作:以你的数组变量为起点,使用操作符|衔接pipe内置的各个常见管道操作函数,组装起自己所需的计算步骤即可,譬如,我们筛选输入数组中为偶数的,再求平方,就可以写作:
import pipe
list(
range(10) |
pipe.filter(lambda x: x % 2 == 0) |
pipe.select(lambda x: x ** 2)
)

因为pipe搭建的管道默认都是惰性运算的,直接产生的结果是生成器类型,所以上面的例子中我们最外层套上了list()来取得实际计算结果,更优雅的方式是配合pipe.Pipe(),将list()也改造为管道操作函数:
from pipe import Pipe
(
range(10) |
pipe.filter(lambda x: x % 2 == 0) |
pipe.select(lambda x: x ** 2) |
Pipe(list)
)

在上面的简单例子中我们使用到的filter()、select()等就是pipe中常见的管道操作函数,事实上pipe中的管道操作函数相当的丰富,下面我们来展示其中一些常用的:
2.1 pipe中常用的管道操作函数
2.1.1 使用traverse()展平嵌套数组
如果你想要将任意嵌套数组结构展平,可以使用traverse():
(
[1, [2, 3, [4, 5]], 6, [7, 8, [9, [10, 11]]]] |
pipe.traverse |
Pipe(list)
)

2.1.2 使用dedup()进行顺序去重
如果我们需要对包含若干重复值的数组进行去重,且希望保留原始数据的顺序,则可以使用dedup(),其还支持key参数,类似sorted()中的同名参数,实现自定义去重规则:
(
[-1, 0, 0, 0, 1, 2, 3] |
pipe.dedup |
Pipe(list)
)
(
[-1, 0, 0, 0, 1, 2, 3] |
# 基于每个元素的绝对值进行去重
pipe.dedup(key=abs) |
Pipe(list)
)

2.1.3 使用filter()进行值过滤
我们最开始的例子中使用过它,用法就是基于传入的lambda函数对每个元素进行条件判断,并保留结果为True的,与javascript中的filter()方法非常相似:
(
[1, 4, 3, 2, 5, 6, 8] |
# 保留大于5的元素
pipe.filter(lambda x: x > 5) |
Pipe(list)
)

2.1.4 使用groupby()进行分组运算
这个函数非常实用,其功能相当于管道操作版本的itertools.groupby(),可以帮助我们基于lambda函数运算结果对原始输入数组进行分组,通过groupby()操作后直接得到的结果是分组结果的二元组列表,每个元组的第一个元素是分组标签,第二个元素是分到该组内的各个元素:

基于此,我们可以衔接很多其他管道操作函数,譬如衔接select()对分组结果进行自定义运算:
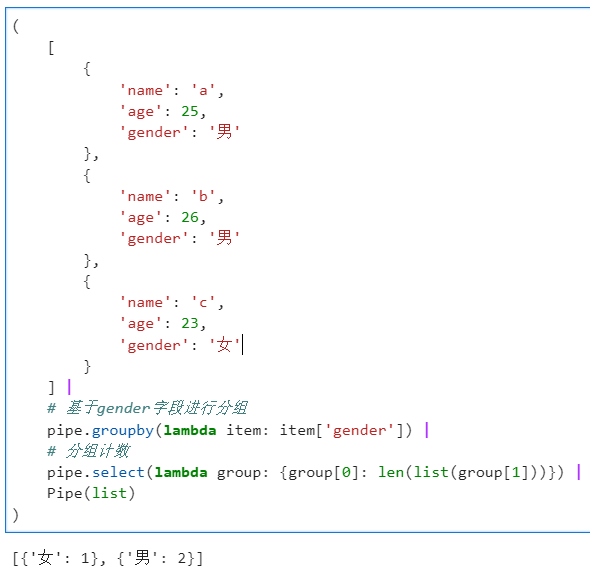
2.1.5 使用select()对上一步结果进行自定义遍历运算
这个函数是pipe()中核心的管道操作函数,通过前面的若干例子也能弄明白,它的功能是基于我们自定义的函数,对上一步的运算结果进行遍历运算。
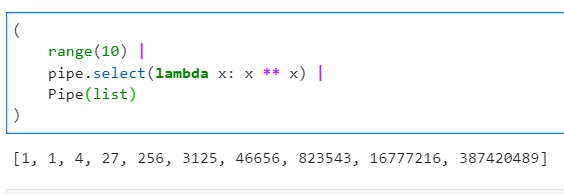
2.1.6 使用sort()进行排序
相当于内置函数sorted()的管道操作版本,同样支持key、reverse参数:

上述内容足以支撑大部分日常操作需求,你也可以在https://github.com/JulienPalard/Pipe中查看pipe的更多功能介绍。
总结
到此这篇关于书写Python代码的一种更优雅方式的文章就介绍到这了,更多相关Python代码书写内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
让你的python代码更加pythonic(简练、明确、优雅)
何为pythonic? pythonic如果翻译成中文的话就是很python.很+名词结构的用法在中国不少,比如:很娘,很国足,很CCTV等等. 我的理解为,很+名词表达了一种特殊和强调的意味.所以很python可以理解为:只有python能做到的,区别于其他语言的写法,其实就是python的惯用和特有写法. 置换两个变量的值. 很python的写法: 复制代码 代码如下: a,b = b,a 不python的写法: 复制代码 代码如下: temp = a a = b b = temp 上面的例
-
这样写python注释让代码更加的优雅
python这样注释,让你的代码看起来更加的优雅,是不是常常感觉自己的python代码写出来,看起来特别的乱,虽然可以正常运行,但是在优雅性上似乎欠缺的很多,这篇文章主要教你,如何让你的python代码看起来更加的优雅与美观, 一.注释欣赏 这里有一段飞兔小哥哥自己常写的注释模版 这里主要分为表头注释.类注释.欢迎语以及方法注释 表头注释会标注这个项目的名称.文件名.项目作者.时间等基础信息 类注释会标注这个类主要用来做什么的 而方法注释则表示当前方法的作用 #!/usr/bin/env p
-

分享一下如何编写高效且优雅的 Python 代码
本文部分提炼自书籍:<Effective Python>&<Python3 Cookbook>,但也做出了修改,并加上了作者自己的理解和运用中的最佳实践. 全文约 9956 字,读完可能需要 24 分钟. Pythonic列表切割 list[start:end:step] 如果从列表开头开始切割,那么忽略 start 位的 0,例如list[:4] 如果一直切到列表尾部,则忽略 end 位的 0,例如list[3:] 切割列表时,即便 start 或者 end 索引跨界也不
-
如何更优雅地写python代码
前言 Python 这门语言最大的优点之一就是语法简洁,好的代码就像伪代码一样,干净.整洁.一目了然.但有时候我们写代码,特别是 Python 初学者,往往还是按照其它语言的思维习惯来写,那样的写法不仅运行速度慢,代码读起来也费尽,给人一种拖泥带水的感觉,过段时间连自己也读不懂. <计算机程序的构造和解释>的作者哈尔·阿伯尔森曾这样说:"Programs must be written for people to read, and only incidentally for mac
-
书写Python代码的一种更优雅方式(推荐!)
目录 1 简介 2 在Python中配合pipe灵活使用链式写法 2.1 pipe中常用的管道操作函数 2.1.1 使用traverse()展平嵌套数组 2.1.2 使用dedup()进行顺序去重 2.1.3 使用filter()进行值过滤 2.1.4 使用groupby()进行分组运算 2.1.5 使用select()对上一步结果进行自定义遍历运算 2.1.6 使用sort()进行排序 总结 1 简介 一些比较熟悉pandas的读者朋友应该经常会使用query().eval().pipe().
-
python代码的几种常见加密方式分享
目录 1.发行.pyc文件 1.1 编译加密 1.2 是否可逆 1.3是否影响模块调用 2.代码混淆 3.生成exe可执行文件 4…py文件转化为.so文件 5.附加运行辅助包文件 方式一:高级加密模式,需要引导代码 方式二:超级加密模式 方式三: 虚拟加密模式 Python的文件类型介绍: .py python的源代码文件 .pyc Python源代码import后,编译生成的字节码 .pyo Python源代码编译优化生成的字节码.pyo比pyc并没有优化多少,只是去掉了断言 .pyd Py
-
Java代码中4种字符串拼接方式分析
目录 结论 最佳实践 分析过程 环境 分析用示例代码: 代码及结果分析 本文研讨的字符串拼接方式为以下4种:“+”号.StringBuilder.StringJoiner.String#join,对比分析及探讨最佳实践. 结论 后面内容比较枯燥,所以先说结论: 本文研讨的字符串拼接方式为以下4种:“+”号.StringBuilder.StringJoiner.String#join 在简单的字符串拼接场景中「如:"a" + "b" + "c"」,
-
10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测. from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_b
-
详解vue-meta如何让你更优雅的管理头部标签
在 Vue SPA 应用中,如果想要修改HTML的头部标签,或许,你会在代码里,直接这么做: // 改下title document.title = 'what?' // 引入一段script let s = document.createElement('script') s.setAttribute('src', './vconsole.js') document.head.appendChild(s) // 修改meta信息,或者给html标签添加属性... // 此处省略一大坨代码...
-
JavaScript中async await更优雅的错误处理方式
目录 背景 为什么要错误处理 async await 更优雅的错误处理 小结 总结 背景 团队来了新的小伙伴,发现我们的团队代码规范中,要给 async await 添加 try...catch.他感觉很疑惑,假如有很多个(不集中),那不是要加很多个地方?那不是很不优雅? 为什么要错误处理 JavaScript 是一个单线程的语言,假如不加 try ...catch ,会导致直接报错无法继续执行.当然不意味着你代码中一定要用 try...catch 包住,使用 try...catch 意味着你
-
MySQL root密码忘记后更优雅的解决方法
前言 一直以来,对于MySQL root密码的忘记,以为只有一种解法-skip-grant-tables. 问了下群里的大咖,第一反应也是skip-grant-tables.通过搜索引擎简单搜索了下,无论是百度,抑或Google,只要是用中文搜索,首页都是这种解法.可见这种解法在某种程度上已经占据了使用者的心智.下面具体来看看. skip-grant-tables的解法 首先,关闭实例 这里,只能通过kill mysqld进程的方式. 注意:不是mysqld_safe进程,也切忌使用kill -
-
让Python代码更快运行的5种方法
不论什么语言,我们都需要注意性能优化问题,提高执行效率.选择了脚本语言就要忍受其速度,这句话在某种程度上说明了Python作为脚本语言的不足之处,那就是执行效率和性能不够亮.尽管Python从未如C和Java一般快速,但是不少Python项目都处于开发语言领先位置. Python很简单易用,但大多数人使用Python都知道在处理密集型cpu工作时,它的数量级依然低于C.Java和JavaScript.但不少第三方不愿赘述Python的优点,而是决定自内而外提高其性能.如果你想让Python在同一
-
如何利用Promises编写更优雅的JavaScript代码
你可能已经无意中听说过 Promises,很多人都在讨论它,使用它,但你不知道为什么它们如此特别.难道你不能使用回调么?有什么了特别的?在本文中,我们一起来看看 Promises 是什么以及如何使用它们写出更优雅的 JavaScript 代码. Promises 易于阅读 比如说我们想从 HipsterJesus 的API中抓取一些数据并将这些数据添加到我们的页面中.这些 API 的响应数据形式如下: { "text": "<p>Lorem ipsum...<