Python爬虫学习之requests的使用教程
目录
- requests库简介
- requests库安装
- 1、pip命令安装
- 2、下载代码进行安装
- requests库的使用
- 发送请求
- get请求
- 抓取二进制数据
- post请求
- POST请求的文件上传
- 利用requests返回响应状态码
requests库简介
requests 库是一个常用的用于 http 请求的模块,它使用 python 语言编写,可以方便的对网页进行爬取,是学习 python 爬虫的较好的http请求模块。 它基于 urllib 库,但比 urllib 方便很多,能完全满足我们 HTTP 请求以及处理 URL 资源的功能。
requests库安装
如果已经安装了 anaconda ,就已经自带了 requets 库(建议新手安装 Python 的话直接安装 anaconda 就好了,可以省去很多繁琐的安装过程的)。如果确实没有安装,可以通过以下两种方式来进行安装
1、pip命令安装
在有pip的情况下直接客户端输入命令下载
pip install requests
2、下载代码进行安装
由于 pip 命令可能安装失败所以有时我们要通过下载第三方库文件来进行安装。
在 github 上的地址为:https://github.com/requests/requests
下载文件到本地之后,解压到 python 安装目录。
之后打开解压文件,在此处运行命令行并输入:
python setup.py install
即可。
之后我们测试 requests 模块是否安装正确,在交互式环境中输入
import requests
如果没有任何报错,说明requests模块我们已经安装成功了
requests库的使用
发送请求
在时用requests库要导入requests模块
import requests
接下来我们就可以尝试获取某个页面
import requests
r = requests.get('http://www.baidu.com')
print(r.text)
现在,我们有一个名为 r 的 Response 对象。我们可以从这个对象中获取所有我们想要的信息
除了get请求我们还有PUT,DELETE,HEAD 以及 OPTIONS 这些http请求方式
接下来我们先看看get请求
get请求
上面的例子就是我们用get方法获取到了百度的首页,并且输出打印结果为
<!DOCTYPE html>
<!--STATUS OK--><html> <head>......</body> </html>
Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。举例来说,如果你想传递 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代码:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
通过print(r.url),可以打印输出URL
http://httpbin.org/get?key2=value2&key1=value1
注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
你还可以将一个列表作为值传入:
payload = {‘key1’: ‘value1’, ‘key2’: [‘value2’, ‘value3’]}
范例
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(r.text)
输出结果
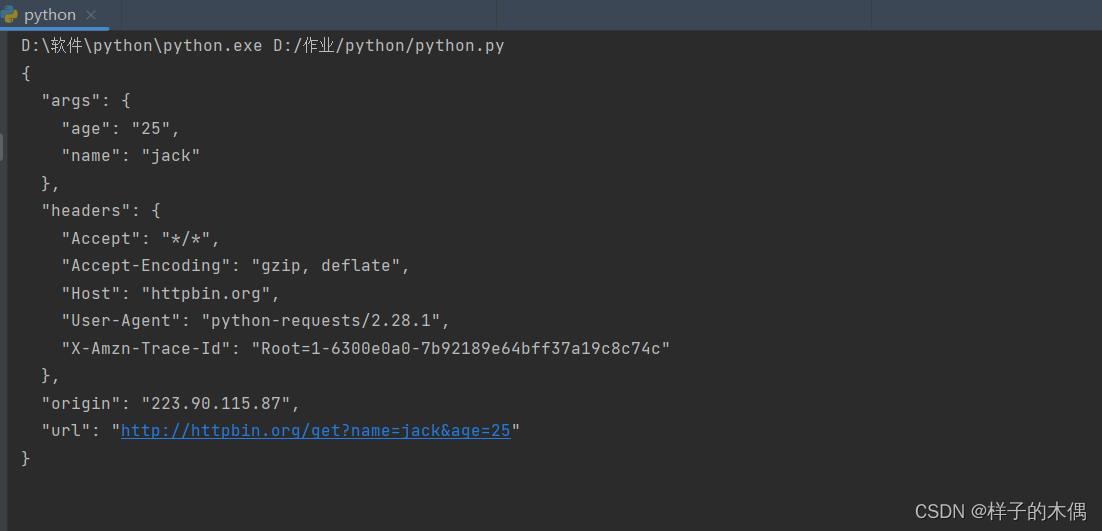
在这里,我们将请求的参数封装为一个 json 格式的数据,然后在 get 方法中传给 params 参数,这样就完成了带参数的 GET 请求 URL 的拼接,省去了自己拼接 http://httpbin.org/get?age=22&name=jack 的过程,非常的方便。
此外,在上面我们看到返回的r.tetx虽然是个字符串,但是它其实是个JSON格式的字符串,我们可以通过 r.json() 方法来将其直接转换为JSON格式数据,从而可以直接解析,省去了引入 json 模块的麻烦。示例如下
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(type(r.json()))
print(r.json())
print(r.json().get('args').get('age'))
输出结果
<class 'dict'>
{'args': {'age': '25', 'name': 'jack'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.28.1', 'X-Amzn-Trace-Id': 'Root=1-6300e24d-71111778036e3f8339b55886'}, 'origin': '223.90.115.87', 'url': 'http://httpbin.org/get?name=germey&age=25'}
25
抓取二进制数据
从上面的例子中我们发现我们可以轻松获取网页的html文档,但是如果我们在浏览网址时想要获取的是图片、视频、音频这些内容的话又该怎么办呢?
我们知道视频音频这些不过就是二进制码,所以我们获取二进制码就能够获取到这些形形色色的图片视频了,接下来我们看看如何获取这些二进制码
接下来以baidu的站点图标为例:
import requests
r = requests.get('https://baidu.com/favicon.ico')
print(r.text)
print(r.content)
......
b'\x00\......x00'
使用content我们可以输出获取的文档的二进制码,但是我们又该如何处理这些二进制码呢?
其实很简单直接将其保留到本地就可以了
import requests
r = requests.get('https://baidu.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)
运行之后就发现我们成功爬取了图片,其实其他之类的视频也是这样操作的

post请求
接下来就是另外一种请求方式post请求
先看看是如何进行请求的
import requests
data = {'name': 'jack', 'age': '25'}
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)
输出结果
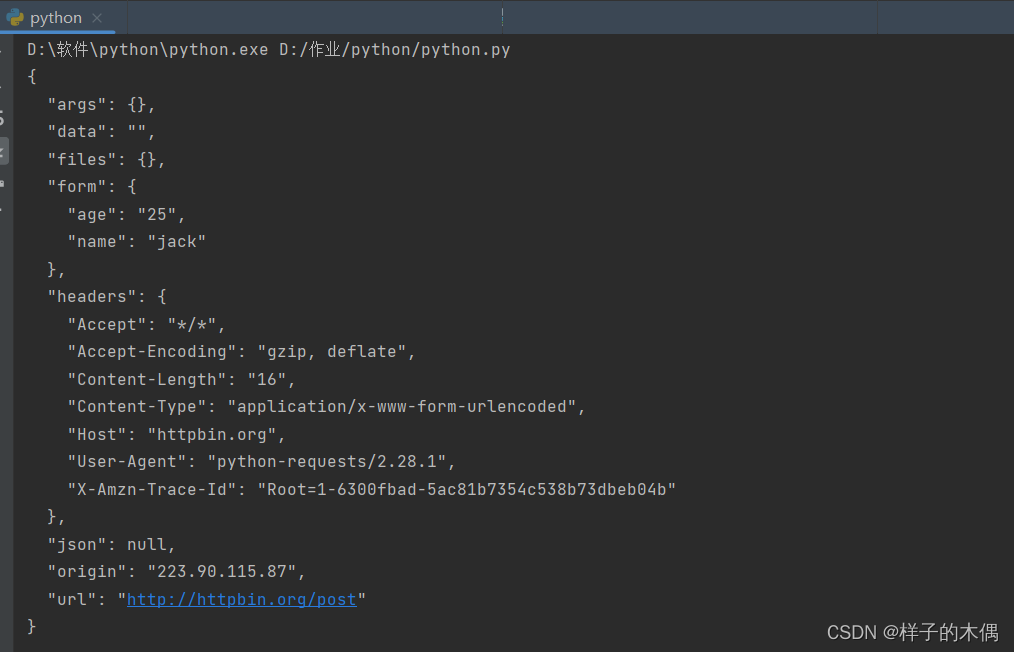
在这里我们将需要的表单数据通过data进行提交,完成一次post请求
同时,你还可以为 data 参数传入一个元组列表。在表单中多个元素使用同一 key 的时候,这种方式尤其有效:
data = (('key1', 'value1'), ('key1', 'value2'))
POST请求的文件上传
范例
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
print(r.text)

我们通过传入files参数来实现文件上传,不过前提是open方法中的文件需要存在(这里我上传的文件就是在get请求里面获取的百度图标),在这里不写路径表示该文件在当前目录下, 否则需要写上完整的路径。这个网站会返回响应,里面包含 files 这个字段,而 form 字段是空的,这证明文件上传部分会单独有一个 files 字段来标识。
利用requests返回响应状态码
r.status_code:获得返回的响应状态码
r.status_code == requests.codes.ok:内置状态码查询
Response.raise_for_status():抛出异常的响应状态
利用前两个方法我们可以获得响应的状态
r = requests.get('http://httpbin.org/get')
r.status_code
200
查询状态
r.status_code == requests.codes.ok True
如果我们发送一个错误请求获取,我们就可以使用Response.raise_for_status()来抛出异常
r = requests.get('http://httpbin.org/status/404')
r.status_code
404
bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
如果响应正常就不会抛出异常,返回以None
到此这篇关于Python爬虫学习之requests的使用教程的文章就介绍到这了,更多相关Python requests内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python中requests库的学习方法详解
目录 前言 一 URL,URI和URN 1. URL,URI和URN 2. URL的组成 二 请求组成 1. 请求方法 2. 请求网址 3. 请求头 4. 请求体 三 请求 1. get请求 2. get带请求头headers参数 3. post请求 四 响应 1. 响应状态码 2. 响应头 3. 响应体 总结 前言 好记性不如烂笔头!最近在接口测试,以及爬虫相关,需要用到Python中的requests库,之前用过,但是好久没有用又忘了,这次就把这块的简单整理下(个人笔记使用) 一 URL,U
-
Python爬虫之requests库基本介绍
目录 一.说明 二.基本用法: 总结 一.说明 requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多. Requests 有这些功能: 1.Keep-Alive & 连接池2.国际化域名和 URL3.带持久 Cookie 的会话4.浏览器式的 SSL 认证5.自动内容解码6.基本/摘要式的身份认证7.优雅的 key/value Cookie8.自
-
Python爬虫Requests库的使用详情
目录 一.Requests库的7个主要的方法 二.Response对象的属性 三.爬取网页通用代码 四.Resquests库的常见异常 五.Robots协议展示 六.案例展示 一.Requests库的7个主要的方法 1.request() 构造请求,支撑以下的基础方法 2.get() 获取HTML页面的主要方法,对应于http的get 3.head() 获取HTML页面的头部信息的主要方法,对应于http的head -以很少的流量获取索要信息的概要内容 4.post() 向HTML提
-
Python中requests库的基本概念与具体使用方法
目录 一. 基本概念 1. 简介 2. 获取 3. http 协议 3.1 URL 3.2 常用 http 请求方法 二. 使用方法 1. 基本语法 2. 具体使用方法 2.1 get 2.2 post 2.3 response 2.4 head 2.5 put 总结 一. 基本概念 1. 简介 requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测
-
python中requests库安装与使用详解
目录 前言 1.Requests介绍 2.requests库的安装 3.requests库常用的方法 4.response对象的常用属性 5.使用requests发送get请求 5.1 不带参数的get请求 5.2 带参数的get请求 5.2.1 查询参数params 5.2.2 SSL证书认证参数 verify 5.2.3 设置超时时间 timeout 5.2.4 代理IP参数 proxies 5.3 获取JSON数据 5.4 获取二进制数据 6.使用requests发送post请求 7.使
-
Python中requests库的用法详解
目录 一.requests库 安装 请求 响应 二.发送get请求 1.一个带参数的get请求: 2.响应json 3.添加头信息headers 4.添加和获取cookie信息 三.发送post请求 1.一个带参数的Post请求: 2.传递JSON数据 3.文件上传 四.高级应用 1.session会话维持 2.身份验证 3.代理设置 4.证书验证 5.超时时间 6.重定向与请求历史 7.其他 五.异常处理 六.requests库和urllib包对比 1.使用urllib.request 2.使
-
详解Python requests模块
前言 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 "HTTP for Humans",说明使用更简洁方便. Requests 继承了urllib2的所有特性.Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码. 开源地址:https://github.com/ke
-
Python爬虫学习之requests的使用教程
目录 requests库简介 requests库安装 1.pip命令安装 2.下载代码进行安装 requests库的使用 发送请求 get请求 抓取二进制数据 post请求 POST请求的文件上传 利用requests返回响应状态码 requests库简介 requests 库是一个常用的用于 http 请求的模块,它使用 python 语言编写,可以方便的对网页进行爬取,是学习 python 爬虫的较好的http请求模块. 它基于 urllib 库,但比 urllib 方便很多,能完全满足我们
-
Python 爬虫学习笔记之单线程爬虫
介绍 本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图 怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像下面这样 这个时候进行翻页,观看网址的变化,首先,第一页的网址是 http://www.maiziedu.com/course/list/, 第二页变成了 http://www.maiziedu.com/course/list/all-all/0-2/, 第三页变成了 http://www.ma
-
python爬虫学习笔记之Beautifulsoup模块用法详解
本文实例讲述了python爬虫学习笔记之Beautifulsoup模块用法.分享给大家供大家参考,具体如下: 相关内容: 什么是beautifulsoup bs4的使用 导入模块 选择使用解析器 使用标签名查找 使用find\find_all查找 使用select查找 首发时间:2018-03-02 00:10 什么是beautifulsoup: 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(官方) beautif
-
python爬虫学习笔记之pyquery模块基本用法详解
本文实例讲述了python爬虫学习笔记之pyquery模块基本用法.分享给大家供大家参考,具体如下: 相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css操作 Dom操作 CSS操作 一个利用pyquery爬取豆瓣新书的例子 首发时间:2018-03-09 21:26 pyquery的介绍 pyquery允许对xml.html文档进行jQuery查询
-
python爬虫scrapy基本使用超详细教程
一.介绍 官方文档:中文2.3版本 下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的. 二.基本使用 2.1 环境安装 1.linux和mac操作系统: pip install scrapy 2.windows系统: 先安装wheel:pip install wheel 下载twisted:下载地址 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
python 爬虫请求模块requests详解
requests 相比urllib,第三方库requests更加简单人性化,是爬虫工作中常用的库 requests安装 初级爬虫的开始主要是使用requests模块 安装requests模块: Windows系统: cmd中: pip install requests mac系统中: 终端中: pip3 install requests requests库的基本使用 import requests url = 'https://www.csdn.net/' reponse = requests.
-
Python爬虫之Scrapy环境搭建案例教程
Python爬虫之Scrapy环境搭建 如何搭建Scrapy环境 首先要安装Python环境,Python环境搭建见:https://blog.csdn.net/alice_tl/article/details/76793590 接下来安装Scrapy 1.安装Scrapy,在终端使用pip install Scrapy(注意最好是国外的环境) 进度提示如下: alicedeMacBook-Pro:~ alice$ pip install Scrapy Collecting Scrapy Usi
-
Python爬虫urllib和requests的区别详解
我们讲了requests的用法以及利用requests简单爬取.保存网页的方法,这节课我们主要讲urllib和requests的区别. 1.获取网页数据 第一步,引入模块. 两者引入的模块是不一样的,这一点显而易见. 第二步,简单网页发起的请求. urllib是通过urlopen方法获取数据. requests需要通过网页的响应类型获取数据. 第三步,数据封装. 对于复杂的数据请求,我们只是简单的通过urlopen方法肯定是不行的.最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕
-
python深度学习tensorflow卷积层示例教程
目录 一.旧版本(1.0以下)的卷积函数:tf.nn.conv2d 二.1.0版本中的卷积函数:tf.layers.conv2d 一.旧版本(1.0以下)的卷积函数:tf.nn.conv2d 在tf1.0中,对卷积层重新进行了封装,比原来版本的卷积层有了很大的简化. conv2d( input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None ) 该函数定义在tensorflow/pytho