MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
看下面的例子吧:
1 Replace into ...
1.1 录入原始数据
mysql> use test;
Database changed
mysql> 
mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;
ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;
Query OK, 1 row affected (0.03 sec)
Records: 1 Duplicates: 0 Warnings: 0
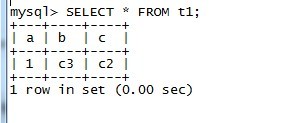
mysql> INSERT INTO t1 SELECT 2,'2', '3';
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t1(b,c) select 'r2','r3';
Query OK, 1 row affected (0.08 sec)
Records: 1 Duplicates: 0 Warnings: 0
1.2 开始replace操作
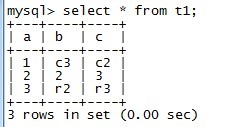
mysql> REPLACE INTO t1(a,b) VALUES(2,'a') ;
Query OK, 2 rows affected (0.06 sec)
【】看到这里,replace,看到这里,a=2的记录中c字段是空串了,
所以当与key冲突时,replace覆盖相关字段,其它字段填充默认值,可以理解为删除重复key的记录,新插入一条记录,一个delete原有记录再insert的操作。
1.3 但是不知道对主键的auto_increment有无影响,接下来测试一下:
mysql> insert into t1(b,c) select 'r4','r5';
Query OK, 1 row affected (0.05 sec)
Records: 1 Duplicates: 0 Warnings: 0mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r2 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)
【】从这里可以看出,新的自增不是从4开始,而是从5开始,就表示一个repalce操作,主键中的auto_increment会累加1.
所以总结如下:
Replace:
当没有key时,replace相当于普通的insert.
当有key时,可以理解为删除重复key的记录,在保持key不变的情况下,delete原有记录,再insert新的记录,新纪录的值只会录入replace语句中字段的值,其余没有在replace语句中的字段,会自动填充默认值。
2.1 ok,再来看Insert into ..... on duplicate key update,
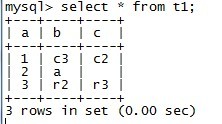
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)
【】a=5时候,原来的c值还在,这表示当key有时,只执行后面的udate操作语句.
2.2 再检查auto_increment情况。
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)mysql> insert into t1(b,c) select 'r6','r7';
Query OK, 1 row affected (0.19 sec)
Records: 1 Duplicates: 0 Warnings: 0mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
+---+----+----+
5 rows in set (0.00 sec)
【】从这里可以看出,新的自增不是从6开始,而是从7开始,就表示一个Insert .. on deplicate udate操作,主键中的auto_increment也跟replace一样累加1.
2.3 再看下当没有key的时候,insert .. on deplicate update的情况
mysql> insert into t1(a,b,c) select '33','r5','c3' on duplicate key update b='r5';
Query OK, 1 row affected, 1 warning (0.23 sec)
Records: 1 Duplicates: 0 Warnings: 1mysql> select * from t1;
+----+----+----+
| a | b | c |
+----+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | b5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
| 9 | s6 | s7 |
| 33 | r5 | c3 |
+----+----+----+
7 rows in set (0.00 sec)
看a=33的记录,ok,全部录入了。
3 总结从上面的测试结果看出,相同之处:
(1),没有key的时候,replace与insert .. on deplicate udpate相同。
(2),有key的时候,都保留主键值,并且auto_increment自动+1
不同之处:有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。
而insert .. deplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句。
但是实际上,根据我推测,如果是简单的update语句,auto_increment不会+1,应该也是先delete,再insert的操作,只是在insert的过程中保留除update后面字段以外的所有字段的值。
所以两者的区别只有一个,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。
从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
个人倾向与用Replace。
相关推荐
-
MYSQL 批量替换之replace语法的使用详解
实际需求中,需要对某张表某字段里面的内容进行批量替换,普通的思考流程如下:SELECT出来str_replace替换UPDATE写入实际这样极其浪费资源以及消耗资源,MYSQL内置了一个批量替换的语法 复制代码 代码如下: UPDATE table SET field = replace(field,'被替换','替换成') 直接就替换了,后面也可以跟WHERE 条件语句支持多个词同时被替换 复制代码 代码如下: UPDATE table SET field = replace(field,'被
-

mysql中使用replace替换某字段的部分内容
最近有个朋友提到如何使用sql来删除一个字段中部分内容,于是就写了这篇文章,简单记过: 测试表如下: 复制代码 代码如下: CREATE TABLE `t` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `domain` tinytext, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 插入测试内容: 复制代码
-
MYSQL的REPLACE和ON DUPLICATE KEY UPDATE语句介绍解决问题实例
在对看看的后台进行排序的时候,遇到了一个像这样的需求,在电影表中有ID(主键自增)和orderby(排序字段) ,假设有十条数据id分别从1-10之间,对应的orderby也是从1-10之间,我现在想把id=9的数据移动到第三的位置(id=3)的这个位置,并且保证之前的数据排列顺序(即id=3的orderby=4,id=4的orderby=5-id=8的orderby=9),这样如果用循环的形式是可以解决数据的问题,但是这样操作数据库过程太多,现在就想用一条sql语句来解决这个问题. 下面来看看
-
MySQL批量去掉某个字段中的空格
Mysql有什么办法批量去掉某个字段字符中的空格?不仅是字符串前后的空格,还包含字符串中间的空格,答案是 replace,使用mysql自带的 replace 函数,另外还有个 trim 函数. (1)mysql replace 函数 语法:replace(object,search,replace) 意思:把object中出现search的全部替换为replace 案例:清除news表中content字段中的空格 update `news` set `content`=replace(`con
-
MySQL中replace into语句的用法详解
在向表中插入数据的时候,经常遇到这样的情况: 1.首先判断数据是否存在: 2.如果不存在,则插入: 3.如果存在,则更新. 在 SQL Server 中可以这样写: 复制代码 代码如下: if not exists (select 1 from table where id = 1) insert into table(id, update_time) values(1, getdate()) else update table set update_time = getdate() whe
-
MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
看下面的例子吧: 1 Replace into ...1.1 录入原始数据mysql> use test;Database changedmysql> mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;Query OK, 1 row affected (0.03 sec)Records: 1 Duplic
-
mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点实例分析
本文实例讲述了mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点.分享给大家供大家参考,具体如下: replace into和insert into on duplicate key update都是为了解决我们平时的一个问题 就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录. 我们创建一个测试表test CREATE TABLE `test` ( `id` int(11) unsigned N
-
insert into … on duplicate key update / replace into 多行数据介绍
场景是这样的,我有KV型的表,建表语句如下: 复制代码 代码如下: CREATE TABLE `dkv` ( `k1` int(11) NOT NULL DEFAULT '0', `k2` int(11) NOT NULL DEFAULT '0', `val` varchar(30) DEFAULT NULL, PRIMARY KEY (`k1`,`k2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 数据大概是这样的: +----+----+---
-
mysql ON DUPLICATE KEY UPDATE重复插入时更新方式
目录 mysql当插入重复时更新的方法 第一种方法 第二种方法 第三种方法 Mysql on duplicate key update 解决插入重复数据时更新值的问题以及其存在的问题 一.使用 二.存在问题 mysql当插入重复时更新的方法 第一种方法 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (client_id,client_name,client_type) SELECT supplie
-
mysql insert的几点操作(DELAYED,IGNORE,ON DUPLICATE KEY UPDATE )
INSERT语法 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] VALUES ({expr | DEFAULT},...),(...),... [ ON DUPLICATE KEY UPDATE col_name=expr, ... ] 或: INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INT
-
Mysql中Insert into xxx on duplicate key update问题
例如,如果列a被定义为unique,并且值为1,则下列语句有同样的效果,也就是说一旦出入的记录中存在a=1的情况,直接更新c = c + 1,而不执行c = 3的操作. 复制代码 代码如下: insert into table(a, b, c) values (1, 2, 3) on duplicate key update c = c + 1;1 update table set c = c + 1 where a = 1; 另外值得一提的是,这个语句知识mysql中,而标准sql语句中是没有
-
mysql ON DUPLICATE KEY UPDATE语句示例
MySQL 自4.1版以后开始支持INSERT - ON DUPLICATE KEY UPDATE语法,使得原本需要执行3条SQL语句(SELECT,INSERT,UPDATE),缩减为1条语句即可完成.例如ipstats表结构如下: 复制代码 代码如下: CREATE TABLE ipstats (ip VARCHAR(15) NOT NULL UNIQUE,clicks SMALLINT(5) UNSIGNED NOT NULL DEFAULT '0'); 原本需要执行3条SQL语句,如下:
-
INSERT INTO .. ON DUPLICATE KEY更新多行记录
如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE:如果不会导致唯一值列重复的问题,则插入新行.例如,如果列a被定义为UNIQUE,并且包含值1,则以下两个语句具有相同的效果: 复制代码 代码如下: INSERT INTO TABLE (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;UPDATE TABLE S
-
深入mysql "ON DUPLICATE KEY UPDATE" 语法的分析
mysql "ON DUPLICATE KEY UPDATE" 语法如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE:如果不会导致唯一值列重复的问题,则插入新行. 例如,如果列 a 为 主键 或 拥有UNIQUE索引,并且包含值1,则以下两个语句具有相同的效果: 复制代码 代码如下: INSERT INTO TABLE (a,c) VALUES