python将文本中的空格替换为换行的方法
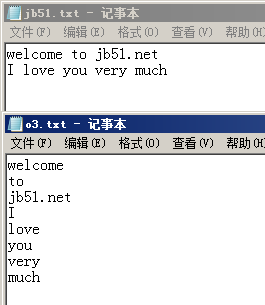
测试文本 jb51.txt
welcome to jb51.net
I love you very much
python代码
# -*- coding: utf-8 -*-
'''
遇到文中的空格就换行
'''
def delblankline(infile, outfile):
infopen = open(infile, 'r',encoding="utf-8")
outfopen = open(outfile, 'w',encoding="utf-8")
db = infopen.read()
outfopen.write(db.replace(' ','\n'))
infopen.close()
outfopen.close()
delblankline("jb51.txt", "o3.txt")
效果图
主要就是用到了replace函数
Python3 replace()方法
描述
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
语法
replace()方法语法:
str.replace(old, new[, max])
参数
old -- 将被替换的子字符串。
new -- 新字符串,用于替换old子字符串。
max -- 可选字符串, 替换不超过 max 次
返回值
返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
实例
以下实例展示了replace()函数的使用方法:
#!/usr/bin/python3
str = "欢迎访问我们www.jb51.net"
print ("我们旧地址:", str)
print ("我们新地址:", str.replace("jb51.net", "jbzj.com"))
str = "this is string example....wow!!!"
print (str.replace("is", "was", 3))
以上实例输出结果如下:
我们旧地址: 欢迎访问我们www.jb51.net
我们新地址: 欢迎访问我们www.jbzj.com
thwas was string example....wow!!!
相关推荐
-
python将文本中的空格替换为换行的方法
测试文本 jb51.txt welcome to jb51.net I love you very much python代码 # -*- coding: utf-8 -*- ''' 遇到文中的空格就换行 ''' def delblankline(infile, outfile): infopen = open(infile, 'r',encoding="utf-8") outfopen = open(outfile, 'w',encoding="utf-8") d
-
Python 删除整个文本中的空格,并实现按行显示
希望以后每天写一篇博客,总结一下每天用到的基本功能,不然项目做完也就做完了,给自己留下的资料太少了. 今天需要造大量的姓名和家庭住址的数据,因此根据读取文件中现有的lastname.firstname以及省.市.道路等随机生成大量的模拟姓名和住址.其中用python进行了简单的文本处理,去掉文本中的空格,数字或者没用的字符等. example 1: 从ifn文件中读取数据,根据空格进行逐个读取,并进行换行显示. #encoding = utf-8# ifn = r"firstname.txt&q
-
python 去除txt文本中的空格、数字、特定字母等方法
使用场景:需要去除txt文本中的空格.数字.特定字母等. 需要修改的txt文本叫做:train.txt 修改之后保存成:train_output.txt # ecoding=utf-8 ifn = r"train.txt" ofn = r"train_output.txt" infile = open(ifn,'rb') outfile = open(ofn,'wb') for eachline in infile.readlines(): #去掉文本行里面的空格.
-
python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来. 从纯文本格式文件 "file_in"中读取数据,格式如下: 需要输出成"file_out",格式如下: 数据的原格式是"类别:内容",以空行"\n"为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容. 建议读取后,使用pandas,把数据建立称DataFrame的表格.这样方便以后处理数据.但是原格式并不是通常的表格格式,所以要先做一些简单的处理
-
利用Python将文本中的中英文分离方法
在进行文本分析.提取关键词时,新闻评论等文本通常是中英文及其他语言的混杂,若不加处理直接分析,结果往往差强人意. 下面对中英文文本进行分离做一下总结: 1.超短文本,ASCII识别. s = "China's Legend Holdings will split its several business arms to go public on stock markets, the group's president Zhu Linan said on Tuesday.该集团总裁朱利安周二表示,
-
Python判断文本中消息重复次数的方法
本文实例讲述了Python判断文本中消息重复次数的方法.分享给大家供大家参考,具体如下: #coding:gbk ''' Created on 2012-2-3 从文件中读取文本,并判断文本中形如"message0"."message123"这样的消息有多少条是重复的 @author: Administrator ''' import re if __name__ == '__main__': pattern = u"(message((\d)+))&qu
-
python读取文本中的坐标方法
利用python读取文本文件很方便,用到了string模块,下面用一个小例子演示读取文本中的坐标信息. import string x , y , z = [] , [] ,[] with open("test.txt") as A: for eachline in A: tmp = eachline.split() x.append(string.atof(tmp[0])) y.append(string.atof(tmp[1])) z.append(string.atof(tmp[
-
python自动提取文本中的时间(包含中文日期)
有时在处理不规则数据时需要提取文本包含的时间日期. dateutil.parser模块可以统一日期字符串格式. datefinder模块可以在字符串中提取日期. datefinder模块实现也是用正则,功能很全 但是对中文不友好. 但是这两个模块都不能支持中文及一些特殊的情况:所以我用正则写了段代码可进行中文日期及一些特殊的时间识别 例如: '2012年12月12日','3小时前','在2012/12/13哈哈','时间2012-12-11 12:22:30','日期2012-13-11','测
-

使用Python提取文本中含有特定字符串的方法示例
今天搞了一天的文本处理,发现python真的太适合做数据处理了.废话不多说,一起学习吧! 1.我的原始数据是这样的,如图 2.如果要提取每行含有pass的字符串,代码如下: import re filepath = "E:/untitled1/analyze_log/test.log" txt = open(filepath, "r").read() result="" test_text = re.findall(".........
-
如何利用Python获取文本中的电话号码实例代码
目录 前言 打开文本 正则表达式遍历电话 最后拼接输出 完整的代码↓ 使用方法 补充:使用Python提取电话号码和E-mail地址 结语 前言 此编制利用Python的简单编程,实现获取txt文本里的电话号码. 这里小编使用了Python3.8.6,os.re库 打开文本 #事先新建文本readphone.txt,将要提取的文章内容复制到readphone.txt里. 下方为Python打开文本 TXTtemp = open("readphone.txt","r+"