一篇文章弄懂Linux磁盘和磁盘分区
前言
Linux 系统中所有的硬件设备都是通过文件的方式来表现和使用的,我们将这些文件称为设备文件,硬盘对应的设备文件一般被称为块设备文件。
本文介绍磁盘设备在 Linux 系统中的表示方法以及如何创建磁盘分区。
为什么要有多个分区?
防止数据丢失:如果系统只有一个分区,那么这个分区损坏,用户将会丢失所的有数据。
增加磁盘空间使用效率:可以用不同的区块大小来格式化分区,如果有很多1K的文件,而硬盘分区区块大小为4K,那么每存储一个文件将会浪费3K空间。这时我们需要取这些文件大小的平均值进行区块大小的划分。
数据激增到极限不会引起系统挂起:将用户数据和系统数据分开,可以避免用户数据填满整个硬盘,引起的系挂起。
磁盘分类
比较常见的磁盘类型有服务器中使用的 SCSI 硬盘和消费类市场中的 SATA 硬盘,当然还有当下大热的各种固态硬盘。
SCSI 硬盘
SCSI 硬盘即采用 SCSI 接口的硬盘。它由于性能好、稳定性高,因此在服务器上得到广泛应用。同时其价格也不菲,正因它的价格昂贵,所以在普通PC上很少见到它的踪迹。SCSI 硬盘使用 50 针接口,外观和普通硬盘接口有些相似(下图来自互联网):

SATA 硬盘
SATA(Serial ATA)口的硬盘又叫串口硬盘,Serial ATA 采用串行连接方式,串行 ATA 总线使用嵌入式时钟信号,具备了更强的纠错能力,与以往相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。串行接口还具有结构简单、支持热插拔的优点(下图来自互联网):

固态硬盘
固态硬盘(Solid State Disk),一般称之为 SSD 硬盘,固态硬盘是用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。其主要特点是没有传统硬盘的机械结构,读写速度非常快(下图来自互联网):

磁盘设备在 Linux 下的表示方法
在 Linux 系统中磁盘设备文件的命名规则为:
主设备号 + 次设备号 + 磁盘分区号
对于目前常见的磁盘,一般表示为:
sd[a-z]x
主设备号代表设备的类型,相同的主设备号表示同类型的设备。当前常见磁盘的主设备号为 sd。
次设备号代表同类设备中的序号,用 "a-z" 表示。比如 /dev/sda 表示第一块磁盘,/dev/sdb 表示第二块磁盘。
x 表示磁盘分区编号。在每块磁盘上可能会划分多个分区,针对每个分区,Linux 用 /dev/sdbx 表示,这里的 x 表示第二块磁盘的第 x 个分区。
如下图所示:

该系统中一共有四块磁盘 /dev/sda,/dev/sdb,/dev/sdc 和 /dev/sdd。其中的 /dev/sda 上创建了三个分区,分别是 /dev/sda1,/dev/sda2,/dev/sda5;/dev/sdb 上只有一个分区 /dev/sdb1。而 /dev/sdc 和 /dev/sdd 则尚未分区(也肯能是只有一个分区,分区的名称和磁盘的名称相同)。
磁盘分区
创建磁盘分区大概有下面几个目的:
- 提升数据的安全性(一个分区的数据损坏不会影响其他分区的数据)
- 支持安装多个操作系统
- 多个小分区对比一个大分区会有性能提升
- 更好的组织数据
磁盘的分区由主分区、扩展分区和逻辑分区组成。在一块磁盘上,主分区的最大个数是 4,其中扩展分区也是一个主分区,并且最多只能有一个扩展分区,但可以在扩展分区上创建多个逻辑分区。因此主分区(包括扩展分区)的范围是 1-4,逻辑分区从 5 开始。对于逻辑分区,Linux 规定它们必须建立在扩展分区上,而不是建立在主分区上。
主分区的作用是用来启动操作系统的,主要存放操作系统的启动或引导程序,因此建议操作系统的引导程序都放在主分区,比如 Linux 的 /boot 分区,最好放在主分区上:

扩展分区只不过是逻辑分区的 "容器"。实际上只有主分区和逻辑分区是用来进行数据存储的,因而可以将数据集中存放在磁盘的逻辑分区中。
我们可以通过 fdisk 命令来查看磁盘分区的信息:
$ sudo fdisk -l /dev/sda

输出中的前几行是磁盘的基本信息,比如总大小为 80G,一共有多少个扇区(sector),每个扇区的大小等等。红框中的则是我们比较关注的分区信息:
- 第一列 Device 显示了磁盘分区对应的设备文件名。
- 第二列 Boot 显示是否为引导分区,上图中的 /dev/sda1 就是引导分区。
- 第三列 Start 表示磁盘分区的起始位置。
- 第四列 End 表示磁盘分区的结束位置。
- 第五列 Sectors 表示分区占用的扇区数目。
- 第六列 Size 显示分区的大小。
- 第七列和第八列显示的内容相同,分别是数值 ID 及其文字描述。 Id 列显示了磁盘分区对应的 ID,根据分区的不同,分区对应的 ID 号也不相同。Linux 下用 83 表示主分区和逻辑分区,5 表示扩展分区,8e 表示 LVM 分区,82 表示交换分区,7 表示 NTFS 分区。
上图中的信息表明:/dev/sda1 是一个主分区并且被用作引导分区;/dev/sda2 是扩展分区,其中只有一个逻辑分区,即 /dev/sda5,这点可以通过两个分区相同的大小证明。
利用 fdisk 划分磁盘分区
fdisk 是 Linux 系统中一款功能强大的磁盘分区管理工具,可以观察硬盘的使用情况,也可以用来管理磁盘分区。本文仅介绍如何使用 fdisk 创建新的磁盘分区。
假设我们的 Linux 系统中增加了一块新的磁盘,系统对应的设备名为 /dev/sdd,下面我们通过 fdisk 命令对这个磁盘进行分区。
$ sudo fdisk /dev/sdd

输入命令 n 来创建新分区:

根据上面的提示,我们选择 p 来创建主分区,然后提示我们输入分区的编号:

主分区的编号为 1- 4,这里我们输入了 1。接下来是设置分区的大小:

分区的大小是通过设置分区开始处的扇区和结束处的扇区设置的。这里如果回车两次会把整个磁盘划分为一个分区,也就是整个磁盘的容器都分给了一个分区。这样一个简单的分区就差不多完成了,注意此时的分区信息还没有写入到磁盘中,在这里还可以反悔,如果确认执行上面的分区,执行 w 命令就行了:

这时分区操作已经完成了,我们可以通过下面的命令查看分区的结果:
$ sudo fdisk -l /dev/sdd
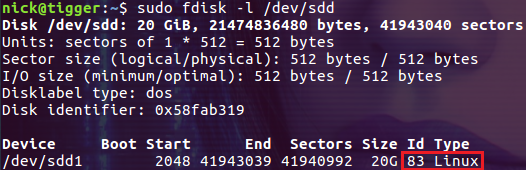
如果嫌上面的执行过程麻烦,可以用下面的一行命令起到相同的效果:
$ (echo n; echo p; echo 1; echo ; echo ; echo w) | sudo fdisk /dev/sdd
更改分区的类型
上面创建的分区类型默认为 83(Linux),如果想要一个 8e(Linux LVM)类型的分区该怎么办?我们可以继续使用 fdisk 命令修改分区的类型,这次输入 t 命令来修改分区的类型:

接下来可以选择要修改的分区号,我们只有一个分区,所以默认就是 1。
下面我们可以通过 L 命令来查看 fdisk 命令支持的分区类型:

我们需要创建 LVM,因此我们使用 LVM 的类型代码 8e:
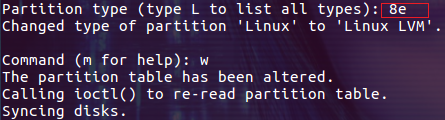
最后输入 w 命令确认变更。再次查看 /dev/sdd 的分区信息,此时分区类型已经变成了 Linux LVM:
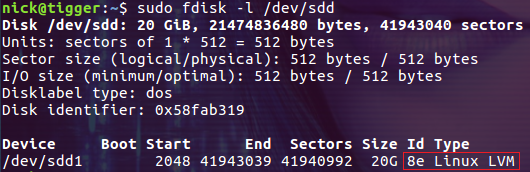
总结
分区是使用磁盘的基础,在分区完成后还需要对分区进行格式化,并把格式化后的文件系统挂载到 Linux 系统之后才能存储文件。
相关推荐
-
Linux磁盘分区实战案例(必看篇)
一.查看新添加磁盘 [root@localhost /]# fdisk -l 磁盘 /dev/sda:53.7 GB, 53687091200 字节,104857600 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节 磁盘标签类型:dos 磁盘标识符:0x0009f1d1 设备 Boot Start End Blocks Id System /dev/s
-
Linux系统磁盘格式化以及手动增加swap分区
windows:支持NTFS ,fat linux支持文件格式: cat /etc/filesystems 查看Centos 7可支持的文件格式. xfs Centos 7 默认文件系统名称为xfs mount 查看 /dev/vda1 on / type ext4 (rw,relatime,data=ordered) 磁盘格式化 mke2fs -t exet4 指定格式化为什么格式的文件系统 mke2fs -b 指定块大小 例如:mke2fs -t ext4 -b 2048 /dev/sdb1
-
Linux磁盘挂载、分区、扩容操作的实现方法
基本概念 在操作前,首先要了解一些基本概念 磁盘 在Linux系统中所有的设备都会以文件的形式存储.设备一般保存在/dev目录下面,以sda.sda1.sda2 -,sdb.sdb1-,hda,hdb.现在的设备一般都是sd命名,以前的很老的硬盘是以ha命名. sda:第一块硬盘,如果对磁盘进行了分区会有sda1(第一个分区),sda2等. sdb:第二个硬盘,同样对硬盘分区后有sdb1,sdb2等. 分区 分区的目的就是便于管理,比如在Windows系统我们一般会分C盘,D盘,E盘等. Lin
-

详解Linux 虚拟机根分区磁盘扩充空间记录
博主:Centos6.5 64 位 VM 11 起因:想让VM11里的Linux虚拟机全屏显示,想支持虚拟机与物理机之间的无缝复制粘贴功能.安装vmware tools 导致空间不足,出现如下 网上查找后发现解决方法: yum remove gnome-power-manager yum install gnome-power-manager 执行后出现: 提示是空间不足 进行查看: 果然,空间利用100% 问题转向: 1.为何使用如此之快? 2.如何扩充? 问题1: 此为根目录,安装的东西都在
-
linux大于2T的磁盘使用GPT分区的方法分享
在linux我们可以先把大容量的磁盘进行转换,转换为GPT格式.由于GPT格式的磁盘相当于原来MBR磁盘中原来保留4个 partition table的4*16个字节只留第一个16个字节,其它的类似于扩展分区,真正的partition table在512字节之后,所以对GPT磁盘表来讲没有四个主分区的限制. 对GPT磁盘分区表进行操作,我们要使用功能强大的parted命令. 例:常用的parted命令 # parted /dev/sdb GNU Parted 1.8.1 Using /dev/s
-
LINUX磁盘分区、格式化、挂载、卸载详细过程
1.一切皆文件 Linux系统有一个理念:"一切皆文件",所以计算机的硬件在linux中也是以"文件"的形式存在于/dev目录中. 图为CentOS 6.5系统中/dev目录的部分内容.不同的计算机显示的内容大同小异. 比如,光驱对应的文件是/dev/cdrom,CPU对应的文件是/dev/cpu.而硬盘对应的是/dev/sd*.第一块硬盘是/dev/sda,第二块磁盘是/dev/sdb. 但是一个磁盘通常又被分成多个分区,所以在磁盘文件的后面加上分区的序号来对应这
-
一篇文章弄懂Linux磁盘和磁盘分区
前言 Linux 系统中所有的硬件设备都是通过文件的方式来表现和使用的,我们将这些文件称为设备文件,硬盘对应的设备文件一般被称为块设备文件. 本文介绍磁盘设备在 Linux 系统中的表示方法以及如何创建磁盘分区. 为什么要有多个分区? 防止数据丢失:如果系统只有一个分区,那么这个分区损坏,用户将会丢失所的有数据. 增加磁盘空间使用效率:可以用不同的区块大小来格式化分区,如果有很多1K的文件,而硬盘分区区块大小为4K,那么每存储一个文件将会浪费3K空间.这时我们需要取这些文件大小的平均值进行区块大
-
一篇文章弄懂MySQL查询语句的执行过程
前言 需要从数据库检索某些符合要求的数据,我们很容易写出 Select A B C FROM T WHERE ID = XX 这样的SQL,那么当我们向数据库发送这样一个请求时,数据库到底做了什么? 我们今天以MYSQL为例,揭示一下MySQL数据库的查询过程,并让大家对数据库里的一些零件有所了解. MYSQL架构 mysql架构 MySQL 主要可以分为 Server 层和存储引擎层. Server层 包括连接器.查询缓存.分析器.优化器.执行器等,所有跨存储引擎的功能都在这一层实现,比如存
-
一篇文章弄懂JVM类加载机制过程以及原理
目录 一.做一个小测试 二.类的初始化步骤: 三.看看你写对了没? 四.类的加载过程 五.类加载器的分类 1.启动类加载器(引导类加载器) 2.扩展类加载器 3.应用程序类加载器(系统类加载器) 六.类加载器子系统的作用 七.总结 一.做一个小测试 通过注释,标注出下面两个类中每个方法的执行顺序,并写出studentId的最终值. package com.nezha.javase; public class Person1 { private int personId; public Perso
-
一篇文章弄懂C++左值引用和右值引用
目录 1. 左值和右值 2. 左值引用 3. 右值引用 3.1 出现 3.2 概念 3.3 应用 3.3.1 右值引用绑定到左值上 3.3.2 std::move()本质 3.3.3 移动构造函数和移动赋值运算符 3.3.4 std::move()的一个例子 4. 补充-协助完成返回值优化(RVO) 5. 总结 篇幅较长,算是从0开始介绍的,请耐心看~ 该篇介绍了左值和右值的区别.左值引用的概念.右值引用的概念.std::move()的本质.移动构造函数.移动复制运算符和RVO. 1. 左值和右
-
一篇文章弄懂Docker镜像的制作、上传、拉取和部署
目录 一.镜像(images) 1. 什么是镜像? 2. 镜像的组成和用途 (1)Dockerfile (2)scratch (3)一个完整的操作系统需要: 3. 为什么要自己制作镜像? 二.镜像制作的步骤(10步法) 第1步:编辑Dockerfile 第2步:编辑requirements.txt文件 第3步:编辑app.py文件,我们的程序文件 第4步:生成镜像文件 第5步:检查镜像是否成功 第6步:使用镜像,启动容器 第7步:访问容器的web服务 第8步:启动redis容器 第9步:再次启动
-
一篇文章弄懂Android自定义viewgroup的相关难点
本文的目的 目的在于教会大家到底如何自定义viewgroup,自定义布局和自定义测量到底如何写.很多网上随便搜搜的概念和流程图 这里不再过多描述了,建议大家看本文之前,先看看基本的自定义viewgroup流程,心中有个大概即可.本文注重于实践 viewgroup 的测量布局流程基本梳理 稍微回顾下,基本的viewgroup绘制和布局流程中的重点: 1.view 在onMeasure()方法中进行自我测量和保存,也就是说对于view(不是viewgroup噢)来说一定在onMeasure方法中计算
-
一篇文章弄懂javascript中的执行栈与执行上下文
前言 作为一个前端开发人员,弄清楚JavaScript的执行上下文有助于我们理解js中一些晦涩的概念,比如闭包,作用域,变量提升等等. 执行栈 执行栈用于存储代码执行期间创建的所有执行上下文.具有FILO接口,也被称为调用栈. 当JavaScript代码被运行的时候,会创建一个全局上下文,并push到当前执行栈.之后当发生函数调用的时候,引擎会为函数创建一个函数执行上下文并push到栈顶.引擎会先执行调用栈顶部的函数,当函数执行完成后,当前函数的执行上下文会被移除当前执行栈.并移动到下一个上下文
-
一篇文章弄懂kotlin的扩展方法
Usage 扩展函数是 kotlin 的又一杀手锏功能,能够在不修改源码的基础上,扩展某些类的能力,方便开发. 例如这里演示了给 String 添加一个获取第一个元素的方法. fun String.first(): Char { if (isEmpty()) { throw NoSuchElementException("String is empty") } return this[0] } fun main(args: Array<String>) { println(
-
一篇文章弄懂C#中的async和await
目录 前言 async await 从以往知识推导 创建异步任务 创建异步任务并返回Task 异步改同步 说说 await Task 说说 async Task<TResult> 同步异步? Task封装异步任务 关于跳到 await 变异步 为什么出现一层层的 await 总结 前言 本文介绍async/Task.在学习该知识点过程中,一定要按照每一个示例,去写代码.执行.输出结果,自己尝试分析思路. async 微软文档:使用 async 修饰符可将方法.lambda 表达式或匿名方法指定
-
一篇文章弄懂Spring MVC的参数绑定
前言 参数绑定,简单来说就是客户端发送请求,而请求中包含一些数据,那么这些数据怎么到达 Controller ?这在实际项目开发中也是用到的最多的,那么 SpringMVC 的参数绑定是怎么实现的呢? 下面我们来详细的讲解. SpringMVC参数绑定,简单来说就是将客户端请求的key/value数据绑定到controller方法的形参上,然后就可以在controller中使用该参数了 下面通过5个常用的注解演示下如何进行参数绑定: 1. @PathVariable注解 @PathVariabl