Pandas中DataFrame的分组/分割/合并的实现
学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
DataFrame分组操作
注意分组后得到的就是Series对象了,而不再是DataFrame对象。
import pandas as pd
# 还是读取这份文件
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# 计算'成交量'按'位置'分组的平均值
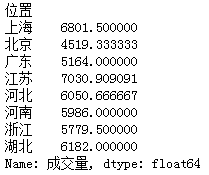
grouped1 = df['成交量'].groupby(df['位置']).mean()
# print(grouped1)
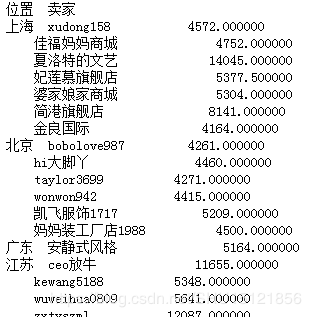
# 计算'成交量'先按'位置'再按'卖家'分组后的平均值 grouped2 = df['成交量'].groupby([df['位置'], df['卖家']]).mean() # print(grouped2)
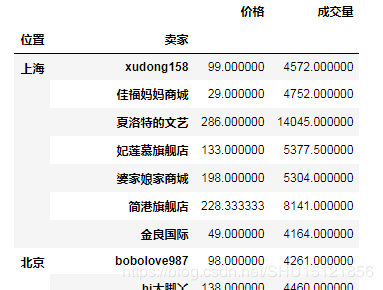
# 计算先按'位置'再按'卖家'分组后的所有指标(如果可以计算平均值)的平均值 grouped3 = df.groupby([df['位置'], df['卖家']]).mean() # print(grouped3)
DataFrame数据分割和合并
这里其实可以操作得很复杂,这里是一些比较基本的用法。
import pandas as pd
# 还是读取这份文件
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# 计算销售额
df['销售额'] = df['价格'] * df['成交量']
# (1)前面学了ix,loc,iloc,这里是直接用[]运算做分割
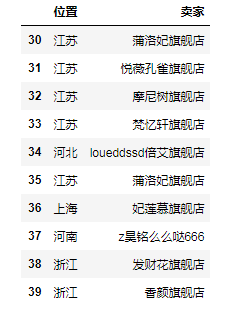
df1 = df[30:40][['位置', '卖家']]
# print(df1) # 从30号行到39号行
df2 = df[80:90][['卖家', '销售额']]
# (2)内联接操作(相当于JOIN,INNER JOIN) df3 = pd.merge(df1, df2) # 不指定列名,默认选择列名相同的'卖家'列 # print(df3) df4 = pd.merge(df1, df2, on='卖家') # 指定按照'卖家'相同做联接 # print(df4)

# (3)全外联接操作(相当于FULL JOIN),没有值的补NaN df5 = pd.merge(df1, df2, how='outer') # print(df5)
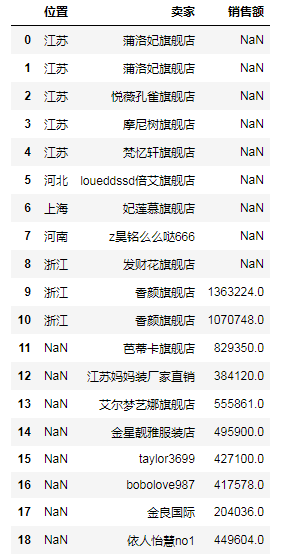
# (4)左外联接操作(相当于LEFT JOIN),即左边的都要,'销售额'没有就NaN df6 = pd.merge(df1, df2, how='left') # print(df6)
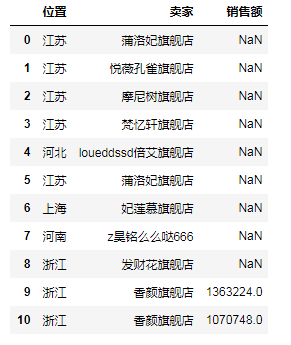
# (5)右外联接操作(相当于RIGHT JOIN),即右边的都要,'位置'没有就NaN df7 = pd.merge(df1, df2, how='right') # print(df7)
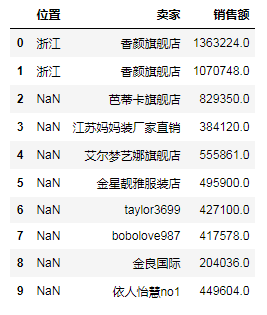
# (6)按索引相同做联接 df_a = df[:10][['位置', '卖家']] df_b = df[3:13][['价格', '成交量']] df_c_1 = pd.merge(df_a, df_b, left_index=True, right_index=True) # 内联接 # print(df_c_1) # 只有从3到9的
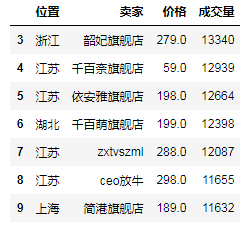
df_c_2 = df_a.join(df_b) # 左外联接 # print(df_c_2) # 从0到10
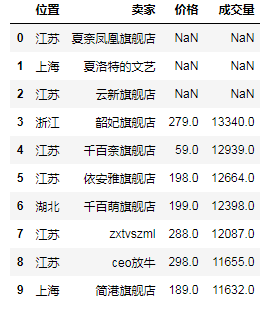
df_c_3 = df_b.join(df_a) # "右"外联接(其实还是左外联接,就是b在左边a在右边) # print(df_c_3) # 从3到12
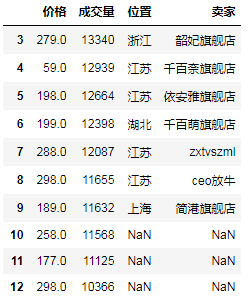
# (7)轴向堆叠操作(上下堆叠时就相当于UNION ALL,默认不去重) df8 = df[2:5][['价格']] # 注意这里只取一个列也要用[[]] df9 = df[3:8][['销售额', '宝贝']] df10 = df[6:11][['卖家', '位置']] # (7.1)默认axis=0即上下堆叠,上下堆叠时,堆叠顺序和传进concat的顺序一致,最终列=所有列数去重,缺失的补NaN # 关于axis=0需要设置sort属性的问题,还没查到有讲这个的,这个问题先留着... df11 = pd.concat([df10, df9, df8], sort=False) # print(df11)
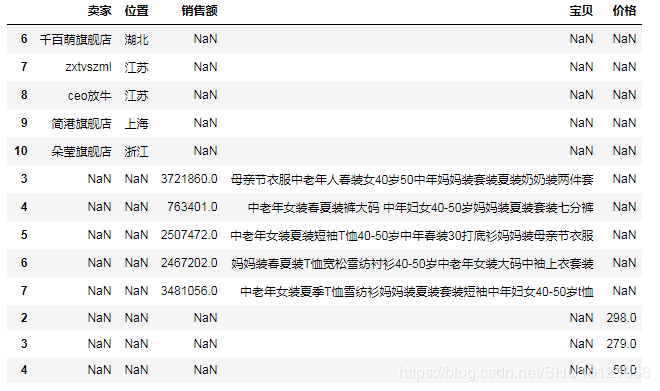
# (7.2)设置axis=1即左右堆叠,左右堆叠不允许索引重复,相同索引的将被合并到一行 # 左右堆叠中,堆叠顺序仅仅影响列的出现顺序 # 这很好理解,毕竟不是从上到下"摞"在一起的,而是从左到右"卡"在一起的 df12 = pd.concat([df10, df9, df8], axis=1) df13 = pd.concat([df8, df9, df10], axis=1) # print(df12) # print(df13)
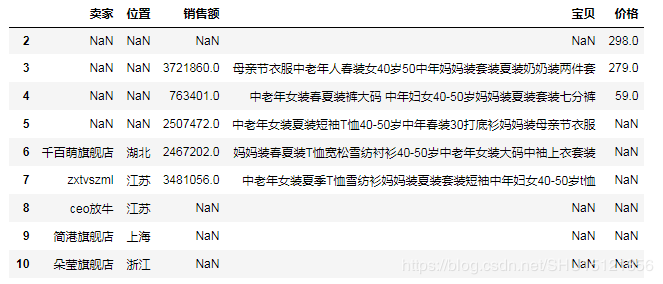

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas dataframe的合并实现(append, merge, concat)
创建2个DataFrame: >>> df1 = pd.DataFrame(np.ones((4, 4))*1, columns=list('DCBA'), index=list('4321')) >>> df2 = pd.DataFrame(np.ones((4, 4))*2, columns=list('FEDC'), index=list('6543')) >>> df3 = pd.DataFrame(np.ones((4, 4))*3, col
-
pandas DataFrame实现几列数据合并成为新的一列方法
问题描述 我有一个用于模型训练的DataFrame如下图所示: 其中的country.province.city.county四列其实是位置信息的不同层级,应该合成一列用于模型训练 方法: parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county'] 就
-
Pandas 合并多个Dataframe(merge,concat)的方法
在数据处理的时候,尤其在搞大数据竞赛的时候经常会遇到一个问题就是,多个表单的合并问题,比如一个表单有user_id和age这两个字段,另一个表单有user_id和sex这两个字段,要把这两个表合并成只有user_id.age.sex三个字段的表怎么办的,普通的拼接是做不到的,因为user_id每一行之间不是对应的,像拼积木似的横向拼接肯定是不行的. pandas中有个merge函数可以做到这个实用的功能,merge这个词会点SQL语言的应该都不陌生. 下面说说merge函数怎么用: df = p
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind
-
Pandas中DataFrame的分组/分割/合并的实现
学习<Python3爬虫.数据清洗与可视化实战>时自己的一些实践. DataFrame分组操作 注意分组后得到的就是Series对象了,而不再是DataFrame对象. import pandas as pd # 还是读取这份文件 df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0) # 计算'成交量'按'位置'分组的平均值 groupe
-

pandas中DataFrame数据合并连接(merge、join、concat)
pandas作者Wes McKinney 在[PYTHON FOR DATA ANALYSIS]中对pandas的方方面面都有了一个权威简明的入门级的介绍,但在实际使用过程中,我发现书中的内容还只是冰山一角.谈到pandas数据的行更新.表合并等操作,一般用到的方法有concat.join.merge.但这三种方法对于很多新手来说,都不太好分清使用的场合与用途.今天就pandas官网中关于数据合并和重述的章节做个使用方法的总结. 文中代码块主要有pandas官网教程提供. 1 concat co
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Pandas中DataFrame基本函数整理(小结)
构造函数 DataFrame([data, index, columns, dtype, copy]) #构造数据框 属性和数据 DataFrame.axes #index: 行标签:columns: 列标签 DataFrame.as_matrix([columns]) #转换为矩阵 DataFrame.dtypes #返回数据的类型 DataFrame.ftypes #返回每一列的 数据类型float64:dense DataFrame.get_dtype_counts() #返回数据框数据类
-
浅谈pandas中DataFrame关于显示值省略的解决方法
python的pandas库是一个非常好的工具,里面的DataFrame更是常用且好用,最近是越用越觉得设计的漂亮,pandas的很多细节设计的都非常好,有待使用过程中发掘. 好了,发完感慨,说一下最近DataFrame遇到的一个细节: 在使用DataFrame中有时候会遇到表格中的value显示不完全,像下面这样: In: import pandas as pd longString = u'''真正的科学家应当是个幻想家:谁不是幻想家,谁就只能把自己称为实践家.人生的磨难是很多的, 所以我们
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
Pandas中DataFrame交换列顺序的方法实现
一.获取DataFrame列标签 import pandas as pd file_path = '/Users/Arithmetic/da-rnn-master/data/collectd67_power_after_test_smooth.csv' dataset = pd.read_csv(file_path) cols = list(dataset) ['ps_state-stopped', 'ps_state-running', 'ps_state-blocked', 'ps_stat
-
pandas中DataFrame重置索引的几种方法
在pandas中,经常对数据进行处理 而导致数据索引顺序混乱,从而影响数据读取.插入等. 小笔总结了以下几种重置索引的方法: import pandas as pd import numpy as np df = pd.DataFrame(np.arange(20).reshape((5, 4)),columns=['a', 'b', 'c', 'd']) #得到df: a b c d 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 4 16 17 1
-
pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重 DataFrame.duplicated(subset=None, keep='first') subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面.默认是所有字段重复为重复数据. keep: 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True. 如果为'last',也就是如果有重复数据,则最后一条出现的定义为Fa