对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数
1.交叉验证(Cross-validation)
交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型。
下图所示
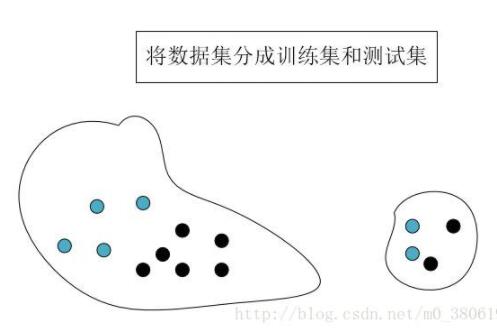
2.StratifiedShuffleSplit函数的使用
用法:
from sklearn.model_selection import StratifiedShuffleSplit StratifiedShuffleSplit(n_splits=10,test_size=None,train_size=None, random_state=None)
2.1 参数说明
参数 n_splits是将训练数据分成train/test对的组数,可根据需要进行设置,默认为10
参数test_size和train_size是用来设置train/test对中train和test所占的比例。例如:
1.提供10个数据num进行训练和测试集划分
2.设置train_size=0.8 test_size=0.2
3.train_num=num*train_size=8 test_num=num*test_size=2
4.即10个数据,进行划分以后8个是训练数据,2个是测试数据
注*:train_num≥2,test_num≥2 ;test_size+train_size可以小于1*
参数 random_state控制是将样本随机打乱
2.2 函数作用描述
1.其产生指定数量的独立的train/test数据集划分数据集划分成n组。
2.首先将样本随机打乱,然后根据设置参数划分出train/test对。
3.其创建的每一组划分将保证每组类比比例相同。即第一组训练数据类别比例为2:1,则后面每组类别都满足这个比例
2.3 具体实现
from sklearn.model_selection import StratifiedShuffleSplit
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4],
[1, 2],[3, 4], [1, 2], [3, 4]])#训练数据集8*2
y = np.array([0, 0, 1, 1,0,0,1,1])#类别数据集8*1
ss=StratifiedShuffleSplit(n_splits=5,test_size=0.25,train_size=0.75,random_state=0)#分成5组,测试比例为0.25,训练比例是0.75
for train_index, test_index in ss.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)#获得索引值
X_train, X_test = X[train_index], X[test_index]#训练集对应的值
y_train, y_test = y[train_index], y[test_index]#类别集对应的值
运行结果:
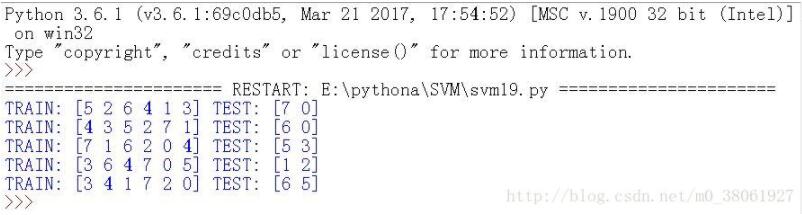
从结果看出,1.训练集是6个,测试集是2,与设置的所对应;2.五组中每组对应的类别比例相同
以上这篇对python中数据集划分函数StratifiedShuffleSplit的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python基础教程之if判断,while循环,循环嵌套
if判断 判断的定义 如果条件满足,就做一件事:条件不满足,就做另一件事: 判断语句又被称为分支语句,有判断,才有分支: if判断语句基本语法 if语句格式: if 判断的条件: 条件成立后做的事 ... ... 代码缩进为一个tab键,或者四个空格,官方建议使用空格:但应注意,在python开发中,tab和空格不能混用! 判断年龄示例: # 判断是否成年,成年则可以进网吧 age = 19 if age>=18: print("你满了18岁,可以进网吧") i
-
Python利用字典破解WIFI密码的方法
最近看到网上的一些作品,然后进行一些完善.只是用于学习,不要去干坏事哦.程序来源于网,我只是做了一些优化.当然这种方法破解还是有点慢哦.我用的python 3.6.5 既然要破解wifi,那么连接wifi的模块首先要有的,我们要导入pywifi模块. 有些同学可能没有这个,如果直接通过pip安装的话,可能不能用,听说这个wifi模块被停用了,所以大家如果通过pip安装的不行,那么就下载我提供的. 链接:https://pan.baidu.com/s/1rn-5F1CS5UXOTcLh3QAMhg
-

如何用Python破解wifi密码过程详解
前言 Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非常方便.wifi跟我们的生活息息相关,无处不在.今天从WiFi连接的原理,再结合代码为大家详细的出一期关于Python破译wifi密码的Python学习教程! 01.如何连接wifi 首先我们的电脑是如何连接wifi的呢?就拿我们的笔记本电脑来说,我们的笔记本电脑都有无线网卡,如下图所示: 当我们连接WiFi时,无线网卡会自动帮助我们扫描附近的WiFi信号,并且会返回WiFi信号的一
-
正确理解Python中if __name__ == '__main__'
在Python,我们经常会编写 if __name__ == '__main__' 这么一段代码,这段代码该怎么来理解? 这段代码的功能理解如下: 一个python的文件有两种使用的方法: 作用一,直接作为脚本执行. 作用二,import到其他的python脚本中被调用(模块重用)执行. if __name__ == '__main__': 的作用就是控制这两种情况执行代码的过程,在if __name__ == '__main__': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执
-
浅谈python下tiff图像的读取和保存方法
对比测试 scipy.misc 和 PIL.Image 和 libtiff.TIFF 三个库 输入: 1. (读取矩阵) 读入uint8.uint16.float32的lena.tif 2. (生成矩阵) 使用numpy产生随机矩阵,float64的mat import numpy as np from scipy import misc from PIL import Image from libtiff import TIFF # # 读入已有图像,数据类型和原图像一致 tif32 = mi
-
python实现猜拳小游戏
用python实现猜拳小游戏,供大家参考,具体内容如下 本练习旨在养成良好的编码习惯和练习逻辑思考. 1.使用python版本: 3.7.3: 2.代码内容实现如下 #!/usr/bin/env python # -*- coding: utf-8 -*- """ 简单实现猜拳小游戏,默认每回合 五局 Version: 0.1 Author: smartbabble Date: 2018-03-12 """ from random import
-
python使用if语句实现一个猜拳游戏详解
任务要求 在控制台中提示输入石头.剪刀.布,按回车键,然后给出游戏结果. 分析 我们知道在游戏规则中,石头克剪刀,剪刀克布,布克石头.但是这在计算机中并不是很好直接的表示,因此我们分别用0.1.2分别代表游戏中的石头剪刀布. 那么电脑该如何出拳呢?那就该用到python中的一个模块random中的一个方法random.randint()在0~2范围内产生一个随机整数,就表电脑出拳了. random.randint()的用法如下: # 首先导入模块 import random # 调用时传入两个整
-
对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数 1.交叉验证(Cross-validation) 交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和.这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型. 下图所示 2.StratifiedShuffleSplit函数的使用 官方文档 用法: from sklearn.
-
对python中矩阵相加函数sum()的使用详解
假如矩阵A是n*n的矩阵 A.sum()是计算矩阵A的每一个元素之和. A.sum(axis=0)是计算矩阵每一列元素相加之和. A.Sum(axis=1)是计算矩阵的每一行元素相加之和. 以上这篇对python中矩阵相加函数sum()的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python中set与frozenset方法和区别详解
set(可变集合)与frozenset(不可变集合)的区别: set无序排序且不重复,是可变的,有add(),remove()等方法.既然是可变的,所以它不存在哈希值.基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交集), difference(差集)和sysmmetric difference(对称差集)等数学运算. sets 支持 x in set, len(set),和 for x in set.作为一个无序的集合,sets不记录元素位
-
对python中字典keys,values,items的使用详解
在python中对字典进行遍历时,可以直接使用如下模式: dict = {"name": "jack", "age": 15, "height": 1.75} for k in dict.keys(): print(k) 使用keys方法遍历得到的是key,可以依次输出,但是当单独使用dict.keys() 时,得到的结果时dict.keys类,属于迭代器,此时并不能使用列表的下标,需要转换一下,方法如下: 直接使用list(
-
对python中的 os.mkdir和os.mkdirs详解
创建目录 在Python中可以使用os.mkdir()函数创建目录(创建一级目录). 其原型如下所示: os.mkdir(path) 其参数path 为要创建目录的路径. 例如要在D盘下创建hello的目录 >>> import os >>> os.mkdir('d:\hello') 可以使用os.makedirs()函数创建多级目录. 其原型如下所示: os.makedirs(path) 其参数path 为要创建目录的路径. 如在D盘下创建books的目录,books
-
对python 中class与变量的使用方法详解
python中的变量定义是很灵活的,很容易搞混淆,特别是对于class的变量的定义,如何定义使用类里的变量是我们维护代码和保证代码稳定性的关键. #!/usr/bin/python #encoding:utf-8 global_variable_1 = 'global_variable' class MyClass(): class_var_1 = 'class_val_1' # define class variable here def __init__(self, param): self
-
对python 中re.sub,replace(),strip()的区别详解
1.strip(): str.strip([chars]);去除字符串前面和后面的所有设置的字符串,默认为空格 chars -- 移除字符串头尾指定的字符序列. st = " hello " st = st.strip() print(st+"end") 输出: 如果设置了字符序列的话,那么它会删除,字符串前后出现的所有序列中有的字符.但不会清除空格. st = "hello" st = st.strip('h,o,e') print(st) 因
-
Python中filter与lambda的结合使用详解
filter是Python的内置方法. 官方定义是: filter(function or None, sequence) -> list, tuple, or string Return those items of sequence for which function(item) is true. If function is None, return the items that are true. If sequence is a tuple or string, return the
-
python中前缀运算符 *和 **的用法示例详解
这篇主要探讨 ** 和 * 前缀运算符,**在变量之前使用的*and **运算符. 一个星(*):表示接收的参数作为元组来处理 两个星(**):表示接收的参数作为字典来处理 简单示例: >>> numbers = [2, 1, 3, 4, 7] >>> more_numbers = [*numbers, 11, 18] >>> print(*more_numbers, sep=', ') 2, 1, 3, 4, 7, 11, 18 用途: 使用 * 和
-
Python中可变变量与不可变变量详解
目录 一 .常见的变量分类 1.变量的创建 二.变量分类 1..常见的不可变变量 2.常见的可变变量 三.拷贝的差别 四.参数传递的差别 前言: C++不同于Python的显著特点,就是有指针和引用,这让我们在调用参数的时候更加清晰明朗.但Python中没有指针和引用的概念,导致很多时候参数的传递和调用的时候会产生疑问:我到底是复制了一份新的做操作还是在它指向的内存操作? 这个问题根本上和可变.不可变变量有关,我想把这个二者的区别和联系做一个总结,以更深入地理解Python内部的操作.我本身非科