对python3中的RE(正则表达式)-详细总结
1.引入正则模块(Regular Expression)
要使用python3中的RE则必须引入 re模块
import re #引入正则表达式
2.主要使用的方法 match(), 从左到右进行匹配
#pattern 为要校验的规则 #str 为要进行校验的字符串 result = re.match(pattern, str) #如果result不为None,则group方法则对result进行数据提取
3. 正则表达式
1️⃣单字符匹配规则
字符 功能 . 匹配任意1个字符(除了\n) [] 匹配[]中列举的字符 \d 匹配数字,也就是0-9 \D 匹配非数字,也就是匹配不是数字的字符 \s 匹配空白符,也就是 空格\tab \S 匹配非空白符,\s取反 \w 陪陪单词字符, a-z, A-Z, 0-9, _ \W 匹配非单词字符, \w取反
2️⃣表示数量的规则
字符 功能
* 匹配前一个字符出现0次多次或者无限次,可有可无,可多可少
+ 匹配前一个字符出现1次多次或则无限次,直到出现一次
? 匹配前一个字符出现1次或者0次,要么有1次,要么没有
{m} 匹配前一个字符出现m次
{m,} 匹配前一个字符至少出现m次
{m,n} 匹配前一个字符出现m到n次
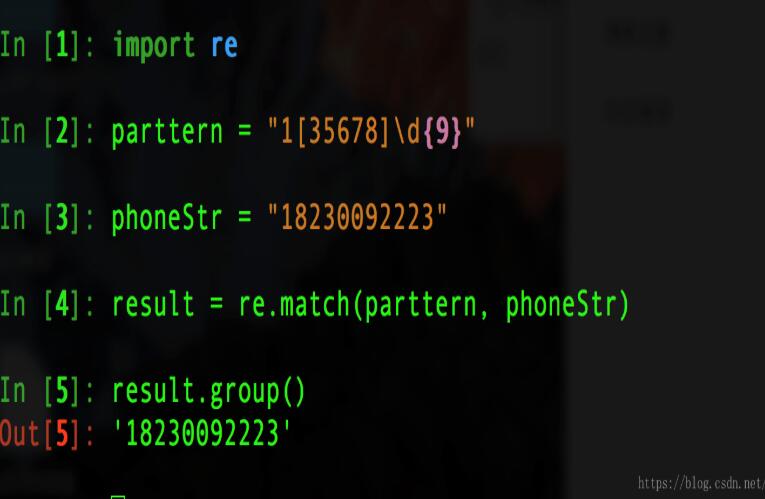
例一: 验证手机号码是否符合规则(不考虑边界问题)
#首先清楚手机号的规则
#1.都是数字 2.长度为11 3.第一位是1 4.第二位是35678中的一位
pattern = "1[35678]\d{9}"
phoneStr = "18230092223"
result = re.match(pattern, phoneStr)
result.group()
#执行结果如下图:
4. 原始字符串raw, 先来看如下实例:
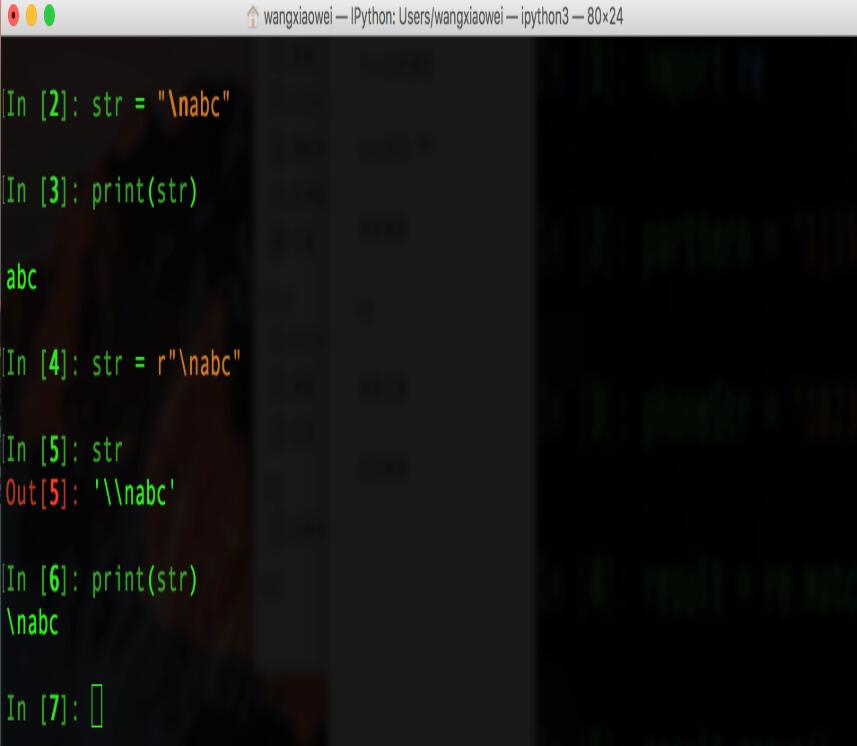
在上图中: 在给str赋值"\nabc"前加上"r"之后,python解释器会自动给str的值"\nabc"在加上一个"\".
使str在被打印的时候,能够保持原始字符串的值"\nabc"打印出来.
例二: (原始字符串在正则表达式中的应用)
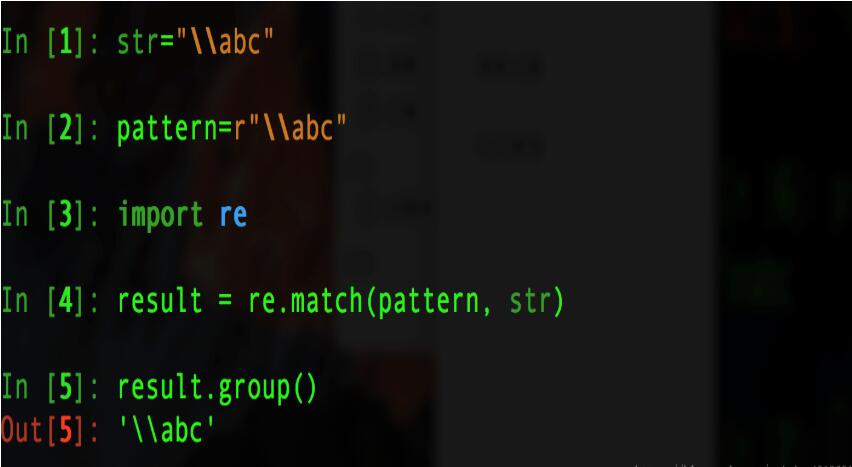
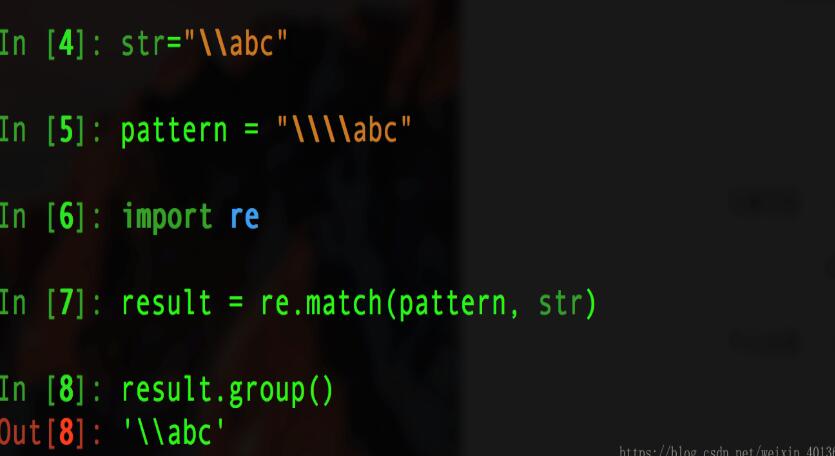
假若没有原始自付出r,则我们就要进行如下的操作: 给pattern加上双倍的"\"以避免转义字符中减少"\".会比较麻烦
当我们使用r原始字符串时,就不必考虑字符串的转移问题,更易集中解决字符匹配问题.
5. 表示边界
字符 功能 ^ 匹配字符串开头 $ 匹配字符串结尾 \b 匹配一个单词的边界 \B 匹配非单词边界
例三: 边界(制定规则来匹配str="ho ve r")
import re #定义规则匹配str="ho ve r" #1. 以字母开始 #2. 中间有空字符 #3. ve两边分别限定匹配单词边界 pattern = r"^\w+\s\bve\b\sr" str = "ho ve r" result = re.match(pattern, str) result.group()
6. 匹配分组
字符 功能 | 匹配左右任意一个表达式 (ab) 将括号中字符作为一个分组 \num 引用分组num匹配到的字符串 (?P<name>) 分组起别名 (?P=name) 引用别名为name分组匹配到的字符串
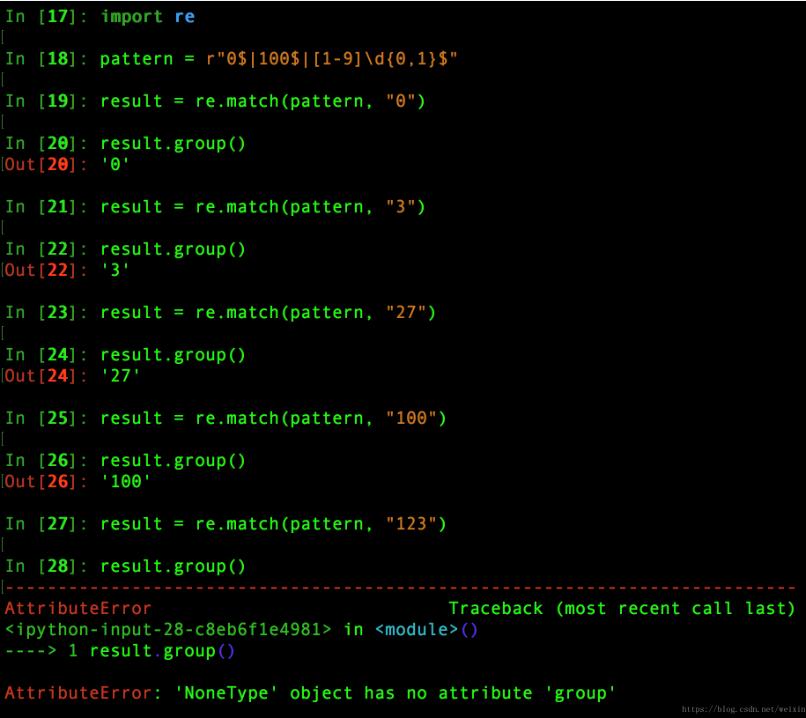
例四: 匹配出0-100之间的数字
import re
#匹配出0-100之间的数字
#首先:正则是从左往又开始匹配
#经过分析: 可以将0-100分为三部分
#1. 0 "0$"
#2. 100 "100$"
#3. 1-99 "[1-9]\d{0,1}$"
#所以整合如下
pattern = r"0$|100$|[1-9]\d{0,1}$"
#测试数据为0,3,27,100,123
result = re.match(pattern, "27")
result.group()
#将0考虑到1-99上,上述pattern还可以简写为:pattern=r"100$|[1-9]?\d{0,1}$"
#测试结果如下图:
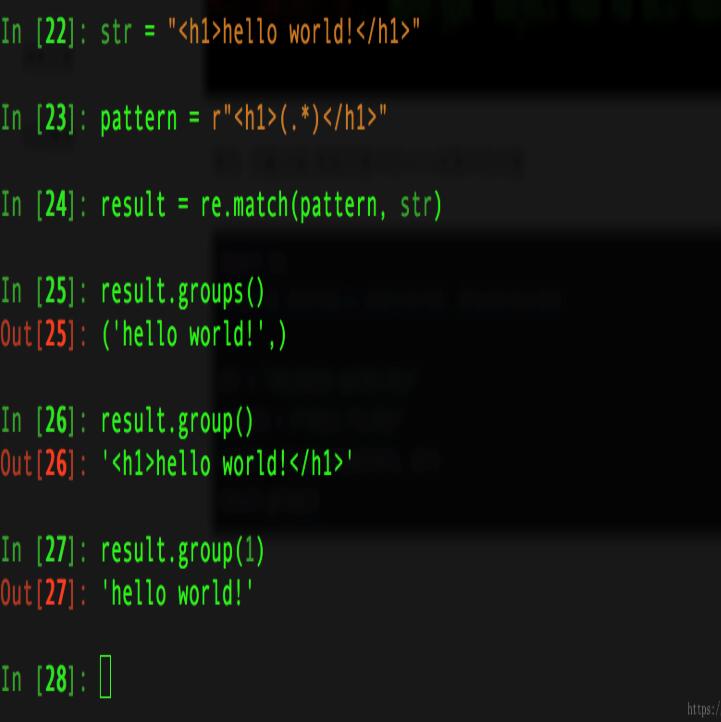
例五: 匹配分组,获取页面中的<h1>标签中的内容
import re #匹配分组,获取页面<h1>标签中的内容, 爬虫的时候会用到 str = "<h1>hello world!<h1>" pattern = r"<h1>(.*)</h1>" result = re.match(pattern, str) result.group() #执行如下图
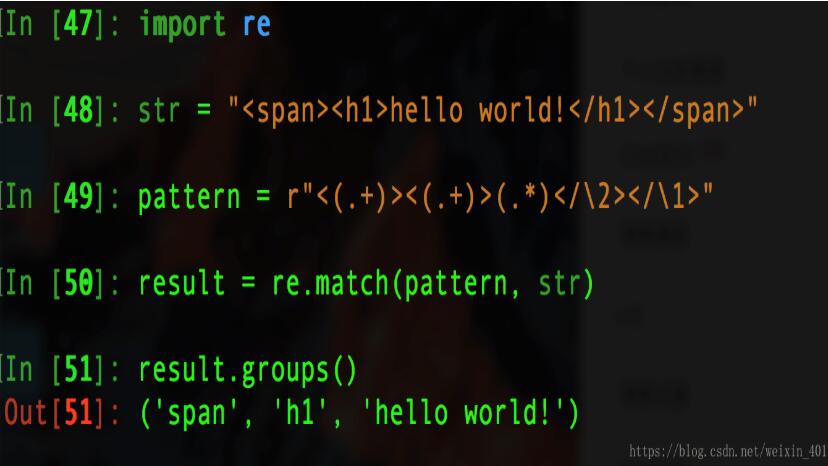
例六: 分组引用, 精确获取多个标签内的内容
import re #引用分组,精确获取多个标签内的内容 #"\1"是对第一个分组的引用,同理...... str = "<span><h1>hello world!</h1></span>" pattern = r"<(.+)><(.+)>.*</\2></\1>" result = re.match(pattern, str) result.groups() #执行如下图:
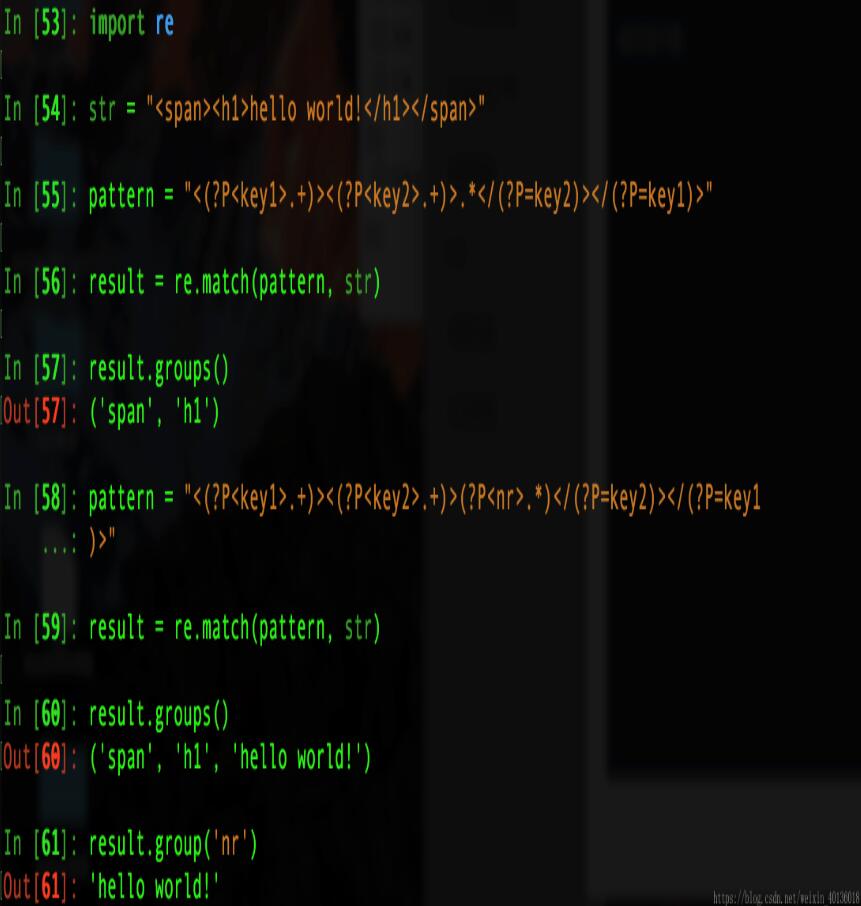
例七-2:分组起别名
import re #分组起别名 str = "<span><h1>hello world!</h1></span>" pattern = "<(?P<key1>.+)><(?P<key2>.+)>(?P<nr>.*)</(?P=key2)></(?P=key1)>" result = re.match(pattern, str) result.groups() #执行如下图:
以上这篇对python3中的RE(正则表达式)-详细总结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python3爬虫之入门基础和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式: 用python抓取指定页面: 代码如下: import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# d
-
Python3使用正则表达式爬取内涵段子示例
本文实例讲述了Python3使用正则表达式爬取内涵段子的方法.分享给大家供大家参考,具体如下: 似乎正则在爬虫中用的不是很广泛,但是也是基本功需要我们去掌握. 先将内涵段子网页爬取下来,之后利用正则进行匹配,匹配完成后将匹配的段子写入文本文档内.代码如下: # -*- coding:utf-8 -*- from urllib import request as urllib2 import re # 利用正则表达式爬取内涵段子 url = r'http://www.neihanpa.com/ar
-
python3.x提取中文的正则表达式示例代码
实例一: 读取txt文件中含有中文的字符 import re ##此处使用的编辑器是python3.x d="[\u4e00-\u9fa5]+" #中文匹配的符号 f=open('test.txt','rb') #这里以二进制读取,方便中文的转义 ,不设置回报错 这里的TXT文档 #文档内容: Hello world China 你好,你好好 This is a txt File s2f程序员杂志一2d3程序员杂志二2d3程序员杂志三2d3程序员杂志四2d3 #此处涉及到文本的读取工作
-
对python3中的RE(正则表达式)-详细总结
1.引入正则模块(Regular Expression) 要使用python3中的RE则必须引入 re模块 import re #引入正则表达式 2.主要使用的方法 match(), 从左到右进行匹配 #pattern 为要校验的规则 #str 为要进行校验的字符串 result = re.match(pattern, str) #如果result不为None,则group方法则对result进行数据提取 3. 正则表达式 1️⃣单字符匹配规则 字符 功能 . 匹配任意1个字符(除了\n) []
-
在python3中使用Supervisor的详细教程
目录 supervisor介绍 安装supervisor 设置环境变量 配置supervisor 管理一个进程 supervisor配置文件详解 启动supervisor 有时候kill进程之后需要释放连接 web界面管理 开启web访问 supervisorctl的用法 superlance介绍 Supervisord支持的Event 安装superlance superlance实战 supervisor介绍 首先,介绍一下supervisor.Supervisor(http://super
-
详解Python3中的正则表达式的基本用法
正则表达式 本节我们看一下正则表达式的相关用法,正则表达式是处理字符串的强大的工具,它有自己特定的语法结构,有了它,实现字符串的检索.替换.匹配验证都不在话下. 当然对于爬虫来说,有了它,我们从HTML里面提取我们想要的信息就非常方便了. 实例引入 说了这么多,可能我们对它到底是个什么还是比较模糊,下面我们就用几个实例来感受一下正则表达式的用法. 我们打开开源中国提供的正则表达式测试工具http://tool.oschina.net/regex/,打开之后我们可以输入待匹配的文本,然后选择常用的
-
Python3中map(),reduce(),filter()的详细用法
目录 前言 1.map() 2.filter() 3.reduce() 前言 Python3中的map().reduce().filter() 这3个一般是用于对序列进行操作的内置函数,它们经常需要与 匿名函数 lambda 联合起来使用,我们今天就来学习下. 1.map() map() 可以用于在函数中对指定序列做映射,返回值是一个迭代器,其使用语法如下: map(function, *iterables) 上面的第一个参数 function 指一个函数,第二个参数 iterable 指一个或
-
Python2和Python3中print的用法示例总结
前言 最近在学习python,对于python的print一直很恼火,老是不按照预期输出.在python2中print是一种输出语句,和if语句,while语句一样的东西,在python3中为了填补python2的各种坑,将print变为函数,因此导致python3中print的一些使用和python2很不一样.下面就来给大家详细的总结了关于Python2和Python3中print的用法,话不多说了,来一起看看详细的介绍吧. 一.Python2中的print用法 在Python2 中 prin
-
正则表达式详细介绍(下)
本文是前一片文章<正则表达式详细介绍(上)>的续篇,在本文中讲述了正则表达式中的组与向后引用,先前向后查看,条件测试,单词边界,选择符等表达式及例子,并分析了正则引擎在执行匹配时的内部机理. 9. 单词边界 元字符<<\b>>也是一种对位置进行匹配的"锚".这种匹配是0长度匹配. 有4种位置被认为是"单词边界": 1) 在字符串的第一个字符前的位置(如果字符串的第一个字符是一个"单词字符") 2) 在字符串的最
-
正则表达式详细介绍(上)
本文是Jan Goyvaerts为RegexBuddy写的教程的译文,下面来看吧! 1. 什么是正则表达式 基本说来,正则表达式是一种用来描述一定数量文本的模式.Regex代表Regular Express.本文将用<<regex>>来表示一段具体的正则表达式. 一段文本就是最基本的模式,简单的匹配相同的文本. 2. 不同的正则表达式引擎 正则表达式引擎是一种可以处理正则表达式的软件.通常,引擎是更大的应用程序的一部分.在软件世界,不同的正则表达式并不互相兼容.本教程会集中讨论Pe
-
python3中int(整型)的使用教程
Python3支持三种不同的数值类型: 整型(int)--通常被称为是整型或整数,可以是正整数或负整数,不带小数点.Python3整型是没有限制大小的,可以当做long类型使用, 但实际上由于机器内存的有限,我们使用的整数是不可能无限大的. 浮点型(float)--浮点型数字由整数部分和小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250) 复数(complex)--复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示,复数的
-
详解Python3中字符串中的数字提取方法
逛到一个有意思的博客在里面看到一篇关于ValueError: invalid literal for int() with base 10错误的解析,针对这个错误,博主已经给出解决办法,使用的是re.sub 方法 totalCount = '100abc' totalCount = re.sub("\D", "", totalCount) 但是没有说明什么含义,于是去查了其他的资料,做一下记录: 在Python3.5.2 官方文档re模块中sub函数的定义是: re
-
python3中str(字符串)的使用教程
本文主要介绍的是python3中对str(字符串)的使用操作总结,文中介绍的非常详细,需要的朋友们下面来一起看看吧. __add__函数 (在后面追加字符串) s1 ='Hello' s2 = s1.__add__(' boy!') print(s2) #输出:Hello boy! __contains__(判断是否包含某字符串,包含则返回True) s1 = 'Hello' result = s1.__contains__('He') print(result) #输出:True __eq__