pandas DataFrame 根据多列的值做判断,生成新的列值实例
环境:Python3.6.4 + pandas 0.22
主要是DataFrame.apply函数的应用,如果设置axis参数为1则每次函数每次会取出DataFrame的一行来做处理,如果axis为1则每次取一列。
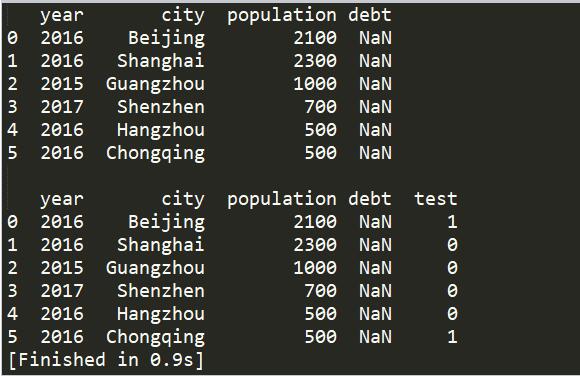
如代码所示,判断如果城市名中含有ing字段且年份为2016,则新列test值赋为1,否则为0.
import numpy as np
import pandas as pd
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],
'year': [2016,2016,2015,2017,2016, 2016],
'population': [2100, 2300, 1000, 700, 500, 500]}
frame = pd.DataFrame(data, columns = ['year', 'city', 'population', 'debt'])
def function(a, b):
if 'ing' in a and b == 2016:
return 1
else:
return 0
print(frame, '\n')
frame['test'] = frame.apply(lambda x: function(x.city, x.year), axis = 1)
print(frame)
运行结果如下:
另外Series类型也有apply函数,用法示例如下:
import numpy as np
import pandas as pd
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],
'year': [2016,2016,2015,2017,2016, 2016],
'population': [2100, 2300, 1000, 700, 500, 500]}
frame = pd.DataFrame(data, columns = ['year', 'city', 'population', 'debt'])
print(frame, '\n')
frame['panduan'] = frame.city.apply(lambda x: 1 if 'ing' in x else 0)
print(frame)
运行结果如下:

以上这篇pandas DataFrame 根据多列的值做判断,生成新的列值实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas 根据列的值选取所有行的示例
如下所示: # 选取等于某些值的行记录 用 == df.loc[df['column_name'] == some_value] # 选取某列是否是某一类型的数值 用 isin df.loc[df['column_name'].isin(some_values)] # 多种条件的选取 用 & df.loc[(df['column'] == some_value) & df['other_column'].isin(some_values)] # 选取不等于某些值的行记录 用 != df.l
-
python中pandas.DataFrame排除特定行方法示例
前言 大家在使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,关于python中pandas.DataFrame的基本操作,大家可以查看这篇文章. pandas.DataFrame排除特定行 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. 但是如果我们只想要所有内容中不包含特定行的内容,却并没有一个isnotin()方法.我今天的工作就遇到了这样的需
-
python pandas库中DataFrame对行和列的操作实例讲解
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
pandas.loc 选取指定列进行操作的实例
今天发现用pandas里面的数据结构可以减少大量的编程工作,从现在开始逐渐积累,记录一下: 使用标签选取数据: df.loc[行标签,列标签] df.loc['a':'b']#选取ab两行数据 df.loc[:,'one']#选取one列的数据 df.loc的第一个参数是行标签,第二个参数为列标签(可选参数,默认为所有列标签),两个参数既可以是列表也可以是单个字符,如果两个参数都为列表则返回的是DataFrame,否则,则为Series. 示例代码: df.loc[ (df.Cabin.notn
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-
pandas DataFrame 根据多列的值做判断,生成新的列值实例
环境:Python3.6.4 + pandas 0.22 主要是DataFrame.apply函数的应用,如果设置axis参数为1则每次函数每次会取出DataFrame的一行来做处理,如果axis为1则每次取一列. 如代码所示,判断如果城市名中含有ing字段且年份为2016,则新列test值赋为1,否则为0. import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'S
-
pandas通过loc生成新的列方法
pandas中一个很便捷的使用方法通过loc.iloc.ix等索引方式,这里记录一下: df.loc[条件,新增列] = 赋初始值 如果新增列名为已有列名,则在原来的数据列上改变 import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(0,100,40).reshape(10,4),columns=list('abcd')) print(data) data.loc[data.d >= 50,'大于
-
pandas apply使用多列计算生成新的列实现示例
在python数据分析中,有时需要根据多列数据生成中间结果,pandas给我们带来了很多方便,通常简短的代码可以实现一些高级功能,灵活掌握一些技巧可以事倍功半 pandas的apply方法用于对指定列的每个元素进行相同的操作,下面生成一个dataFrame用于演示: import pandas as pd a=range(5) b=range(5,10) c=range(10,15) data=pd.DataFrame([a,b,c]).T data.columns=["a",&quo
-
pandas DataFrame的修改方法(值、列、索引)
对于DataFrame的修改操作其实有很多,不单单是某个部分的值的修改,还有一些索引的修改.列名的修改,类型修改等等.我们仅选取部分进行介绍. 一.值的修改 DataFrame的修改方法,其实前面介绍loc方法的时候介绍了一些. 1. loc方法修改 loc方法实际上是定位某个位置的数据的,但是定位完以后就可以对此位置的数据进行修改,使用此方法可以对DataFrame进行的修改如下: 1.对某行.某N行进行修改: 2.对某列.某N列进行修改: 3.对横坐标为某行或某N行,纵坐标为某列或者某N列的
-
Pandas DataFrame数据的更改、插入新增的列和行的方法
一.更改DataFrame的某些值 1.更改DataFrame中的数据,原理是将这部分数据提取出来,重新赋值为新的数据. 2.需要注意的是,数据更改直接针对DataFrame原数据更改,操作无法撤销,如果做出更改,需要对更改条件做确认或对数据进行备份. 代码: import pandas as pd df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['
-
pandas.DataFrame的pivot()和unstack()实现行转列
示例:有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings import filterwarnings # 由于create table if not exists总会抛出warning,因此使用filterwarnings消除 filterwarnings('ignore', category = MySQLdb.Warning) from sqlalchemy im
-
pandas DataFrame 行列索引及值的获取的方法
pandas DataFrame是二维的,所以,它既有列索引,又有行索引 上一篇里只介绍了列索引: import pandas as pd df = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]}) print df # 结果: A B 0 0 3 1 1 4 2 2 5 行索引自动生成了 0,1,2 如果要自己指定行索引和列索引,可以使用 index 和 column 参数: 这个数据是5个车站10天内的客流数据: ridership_df = pd
-
pandas DataFrame实现几列数据合并成为新的一列方法
问题描述 我有一个用于模型训练的DataFrame如下图所示: 其中的country.province.city.county四列其实是位置信息的不同层级,应该合成一列用于模型训练 方法: parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county'] 就
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
pandas选择或添加列生成新的DataFrame操作示例
目录 如何向 pandas.DataFrame 添加新的列或行 选择某些列 选择某些列和行 添加新的列 更改某一列的值 补全缺失值 如何向 pandas.DataFrame 添加新的列或行 通过指定新的列名/行名来添加,或者用pandas.DataFrame的assign().insert().append()方法添加等方法. 这里,将描述以下内容. 将列添加到 pandas.DataFrame 通过指定新列名添加 用assign()方法添加/分配 用insert()方法添加到任意位置 使用 c
随机推荐
- 使用 Iisext.vbs 删除应用程序依存关系的实现方法
- php如何实现只替换一次或N次
- linux下的tar命令详细解释
- Android微信端的下拉刷新功能
- 浅谈JavaScript中的apply/call/bind和this的使用
- js 作用域和变量详解
- 全面解析JavaScript里的循环方法之forEach,for-in,for-of
- php如何执行非缓冲查询API
- 高性能JavaScript DOM编程(1)
- jQuery选择器之基本选择器与层次选择器
- javascript获取鼠标点击元素对象(示例代码)
- Java concurrency之AtomicLongArray原子类_动力节点Java学院整理
- Android编程获取地理位置的经度和纬度实例
- Django实现组合搜索的方法示例
- Vue 中使用vue2-highcharts实现top功能的示例
- C#如何操作Excel数据透视表
- PHP从零开始打造自己的MVC框架之类的自动加载实现方法详解
- python实现大文件分割与合并
- MySQL8新特性:自增主键的持久化详解
- redis基本类型和使用方法详解