python使用pandas处理大数据节省内存技巧(推荐)
一般来说,用pandas处理小于100兆的数据,性能不是问题。当用pandas来处理100兆至几个G的数据时,将会比较耗时,同时会导致程序因内存不足而运行失败。
当然,像Spark这类的工具能够胜任处理100G至几个T的大数据集,但要想充分发挥这些工具的优势,通常需要比较贵的硬件设备。而且,这些工具不像pandas那样具有丰富的进行高质量数据清洗、探索和分析的特性。对于中等规模的数据,我们的愿望是尽量让pandas继续发挥其优势,而不是换用其他工具。
本文我们讨论pandas的内存使用,展示怎样简单地为数据列选择合适的数据类型,就能够减少dataframe近90%的内存占用。
处理棒球比赛记录数据
我们将处理130年的棒球甲级联赛的数据,数据源于
Retrosheet(http://www.retrosheet.org/gamelogs/index.html)
原始数据放在127个csv文件中,我们已经用csvkit
(https://csvkit.readthedocs.io/en/1.0.2/)
(https://data.world/dataquest/mlb-game-logs)
我们从导入数据,并输出前5行开始:

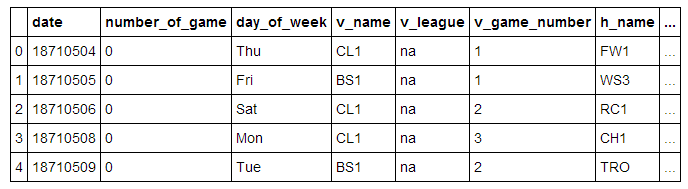
我们将一些重要的字段列在下面:
date- 比赛日期
v_name- 客队名
v_league- 客队联赛
h_name- 主队名
h_league- 主队联赛
v_score- 客队得分
h_score- 主队得分
v_line_score- 客队线得分, 如010000(10)00.
h_line_score- 主队线得分, 如010000(10)0X.
park_id- 主办场地的ID
attendance- 比赛出席人数
我们可以用Dataframe.info()方法来获得我们dataframe的一些高level信息,譬如数据量、数据类型和内存使用量。
这个方法默认情况下返回一个近似的内存使用量,现在我们设置参数memory_usage为‘deep'来获得准确的内存使用量:

我们可以看到它有171907行和161列。pandas已经为我们自动检测了数据类型,其中包括83列数值型数据和78列对象型数据。对象型数据列用于字符串或包含混合数据类型的列。
由此我们可以进一步了解我们应该如何减少内存占用,下面我们来看一看pandas如何在内存中存储数据。
Dataframe对象的内部表示
在底层,pandas会按照数据类型将列分组形成数据块(blocks)。下图所示为pandas如何存储我们数据表的前十二列:

可以注意到,这些数据块没有保持对列名的引用,这是由于为了存储dataframe中的真实数据,这些数据块都经过了优化。有个BlockManager类
会用于保持行列索引与真实数据块的映射关系。他扮演一个API,提供对底层数据的访问。每当我们查询、编辑或删除数据时,dataframe类会利用BlockManager类接口将我们的请求转换为函数和方法的调用。
每种数据类型在pandas.core.internals模块中都有一个特定的类。pandas使用ObjectBlock类来表示包含字符串列的数据块,用FloatBlock类来表示包含浮点型列的数据块。对于包含数值型数据(比如整型和浮点型)的数据块,pandas会合并这些列,并把它们存储为一个Numpy数组(ndarray)。Numpy数组是在C数组的基础上创建的,其值在内存中是连续存储的。基于这种存储机制,对其切片的访问是相当快的。
由于不同类型的数据是分开存放的,我们将检查不同数据类型的内存使用情况,我们先看看各数据类型的平均内存使用量:
由于不同类型的数据是分开存放的,我们将检查不同数据类型的内存使用情况,我们先看看各数据类型的平均内存使用量:

我们可以看到内存使用最多的是78个object列,我们待会再来看它们,我们先来看看我们能否提高数值型列的内存使用效率。
选理解子类(Subtypes)
刚才我们提到,pandas在底层将数值型数据表示成Numpy数组,并在内存中连续存储。这种存储方式消耗较少的空间,并允许我们较快速地访问数据。由于pandas使用相同数量的字节来表示同一类型的每一个值,并且numpy数组存储了这些值的数量,所以pandas能够快速准确地返回数值型列所消耗的字节量。
pandas中的许多数据类型具有多个子类型,它们可以使用较少的字节去表示不同数据,比如,float型就有float16、float32和float64这些子类型。这些类型名称的数字部分表明了这种类型使用了多少比特来表示数据,比如刚才列出的子类型分别使用了2、4、8个字节。下面这张表列出了pandas中常用类型的子类型:
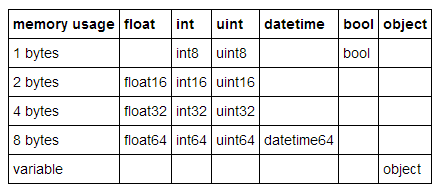
一个int8类型的数据使用1个字节(8位比特)存储一个值,可以表示256(2^8)个二进制数值。这意味着我们可以用这种子类型去表示从-128到127(包括0)的数值。
我们可以用numpy.iinfo类来确认每一个整型子类型的最小和最大值,如下:

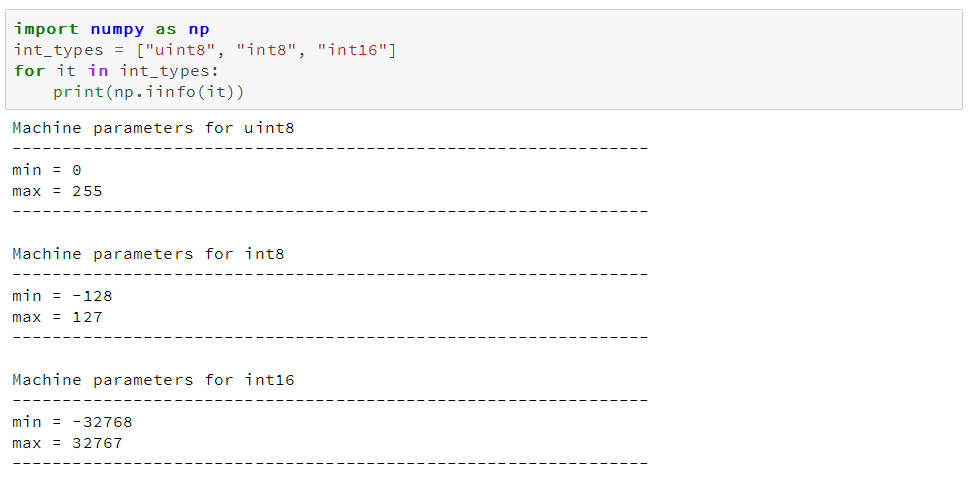
这里我们还可以看到uint(无符号整型)和int(有符号整型)的区别。两者都占用相同的内存存储量,但无符号整型由于只存正数,所以可以更高效的存储只含正数的列。
用子类型优化数值型列
我们可以用函数pd.to_numeric()来对数值型进行向下类型转换。我们用DataFrame.select_dtypes来只选择整型列,然后我们优化这种类型,并比较内存使用量。
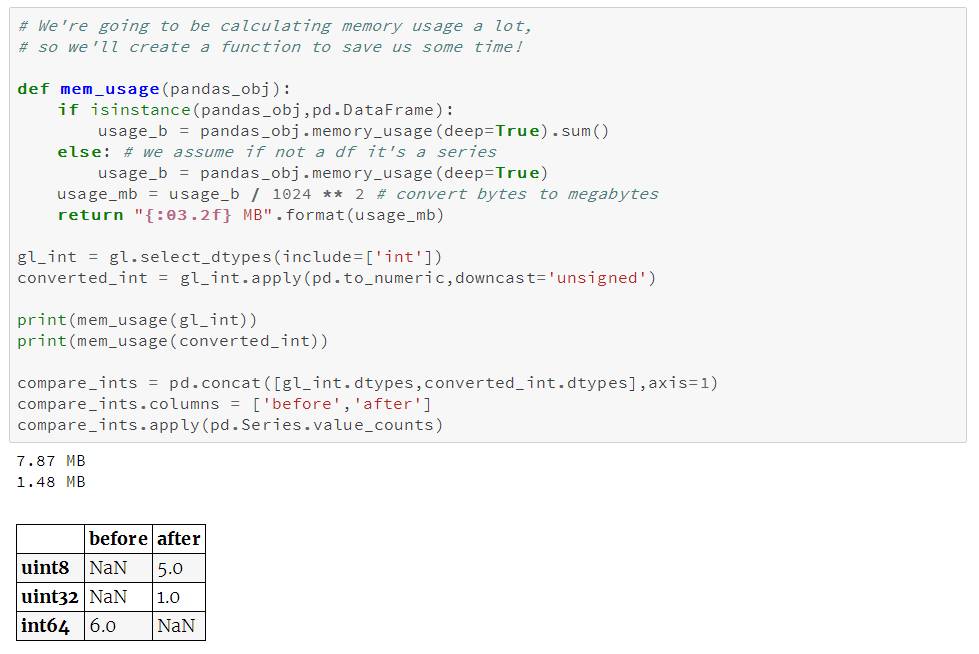
我们看到内存用量从7.9兆下降到1.5兆,降幅达80%。这对我们原始dataframe的影响有限,这是由于它只包含很少的整型列。
同理,我们再对浮点型列进行相应处理:
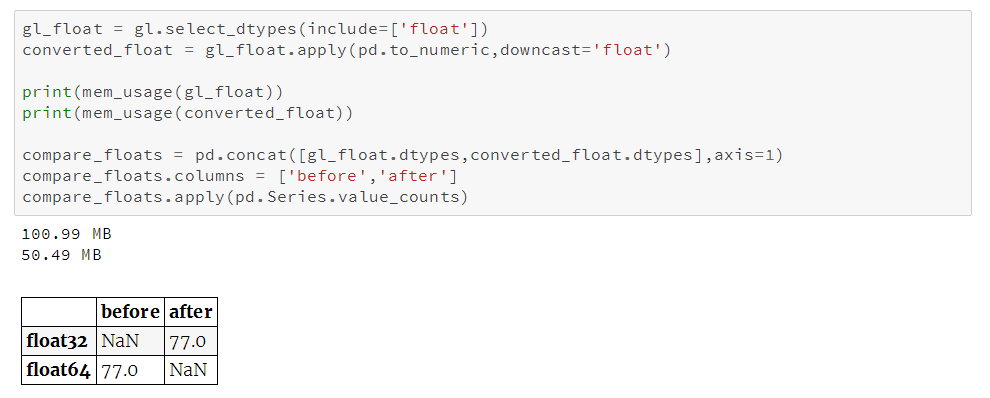
我们可以看到所有的浮点型列都从float64转换为float32,内存用量减少50%。
我们再创建一个原始dataframe的副本,将其数值列赋值为优化后的类型,再看看内存用量的整体优化效果。

可以看到通过我们显著缩减数值型列的内存用量,我们的dataframe的整体内存用量减少了7%。余下的大部分优化将针对object类型进行。
在这之前,我们先来研究下与数值型相比,pandas如何存储字符串。
选对比数值与字符的储存
object类型用来表示用到了Python字符串对象的值,有一部分原因是Numpy缺少对缺失字符串值的支持。因为Python是一种高层、解析型语言,它没有提供很好的对内存中数据如何存储的细粒度控制。
这一限制导致了字符串以一种碎片化方式进行存储,消耗更多的内存,并且访问速度低下。在object列中的每一个元素实际上都是存放内存中真实数据位置的指针。
下图对比展示了数值型数据怎样以Numpy数据类型存储,和字符串怎样以Python内置类型进行存储的。
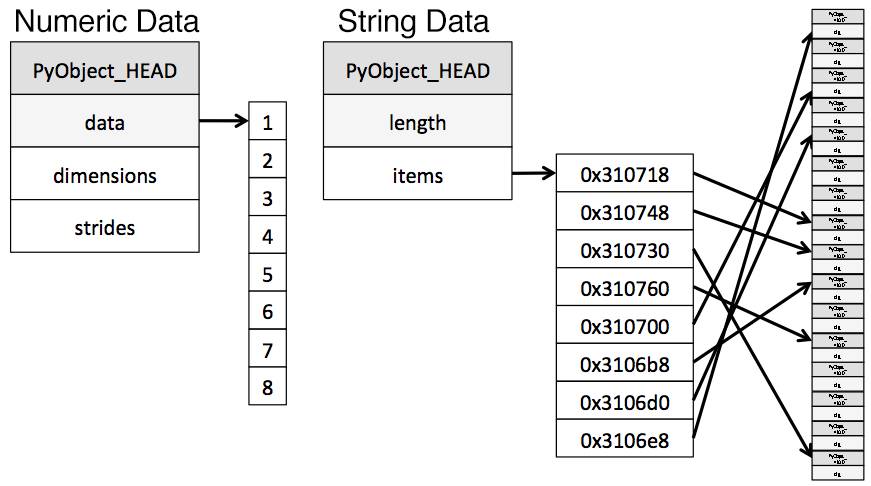
图示来源并改编自Why Python Is Slow
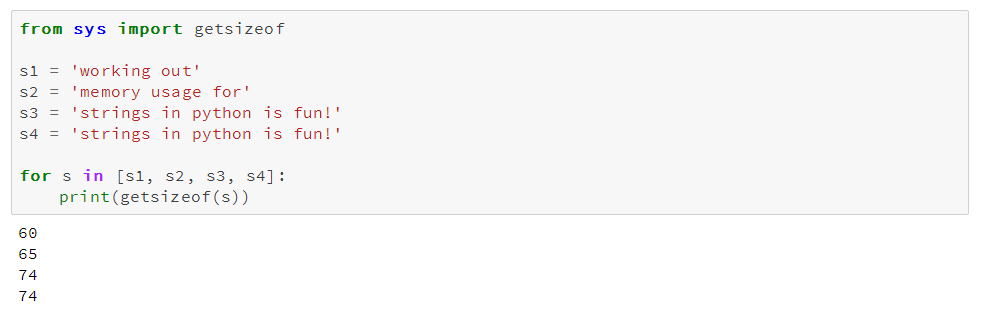
你可能注意到上文表中提到object类型数据使用可变(variable)大小的内存。由于一个指针占用1字节,因此每一个字符串占用的内存量与它在Python中单独存储所占用的内存量相等。我们用sys.getsizeof()来证明这一点,先来看看在Python单独存储字符串,再来看看使用pandas的series的情况。
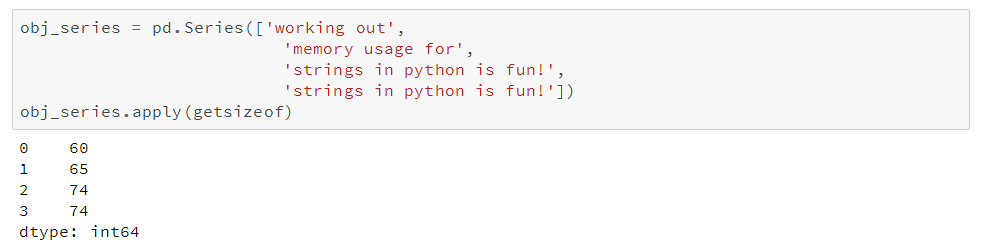
你可以看到这些字符串的大小在pandas的series中与在Python的单独字符串中是一样的。
选用类别(categoricalas)类型优化object类型
Pandas在0.15版本中引入类别类型。category类型在底层使用整型数值来表示该列的值,而不是用原值。Pandas用一个字典来构建这些整型数据到原数据的映射关系。当一列只包含有限种值时,这种设计是很不错的。当我们把一列转换成category类型时,pandas会用一种最省空间的int子类型去表示这一列中所有的唯一值。
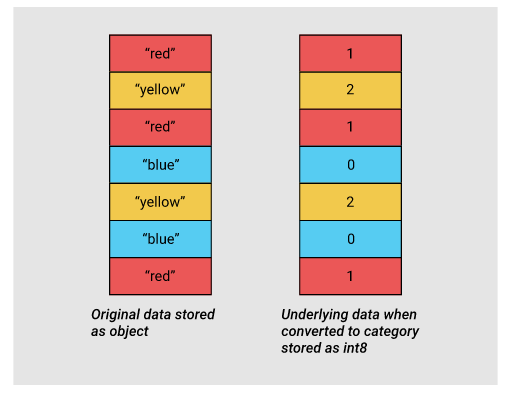
为了介绍我们何处会用到这种类型去减少内存消耗,让我们来看看我们数据中每一个object类型列中的唯一值个数。
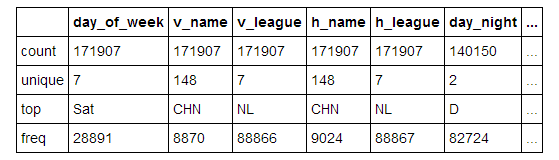
可以看到在我们包含了近172000场比赛的数据集中,很多列只包含了少数几个唯一值。
我们先选择其中一个object列,开看看将其转换成类别类型会发生什么。这里我们选用第二列:day_of_week。
我们从上表中可以看到,它只包含了7个唯一值。我们用.astype()方法将其转换为类别类型。
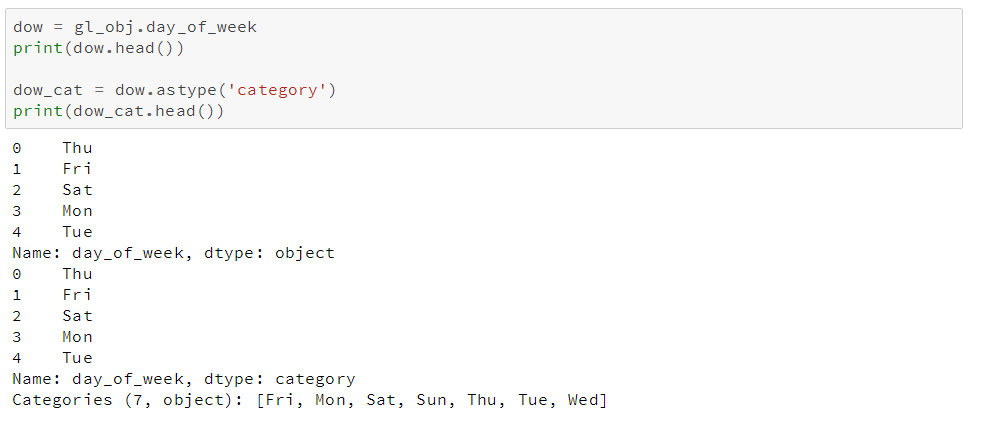
可以看到,虽然列的类型改变了,但数据看上去好像没什么变化。我们来看看底层发生了什么。
下面的代码中,我们用Series.cat.codes属性来返回category类型用以表示每个值的整型数字。

可以看到,每一个值都被赋值为一个整数,而且这一列在底层是int8类型。这一列没有任何缺失数据,但是如果有,category子类型会将缺失数据设为-1。
最后,我们来看看这一列在转换为category类型前后的内存使用量。

存用量从9.8兆降到0.16兆,近乎98%的降幅!注意这一特殊列可能代表了我们一个极好的例子——一个包含近172000个数据的列只有7个唯一值。
这样的话,我们把所有这种类型的列都转换成类别类型应该会很不错,但这里面也要权衡利弊。首要问题是转变为类别类型会丧失数值计算能力,在将类别类型转换成真实的数值类型前,我们不能对category列做算术运算,也不能使用诸如Series.min()和Series.max()等方法。
对于唯一值数量少于50%的object列,我们应该坚持首先使用category类型。如果某一列全都是唯一值,category类型将会占用更多内存。这是因为这样做不仅要存储全部的原始字符串数据,还要存储整型类别标识。有关category类型的更多限制,参看pandas文档。
下面我们写一个循环,对每一个object列进行迭代,检查其唯一值是否少于50%,如果是,则转换成类别类型。

更之前一样进行比较:
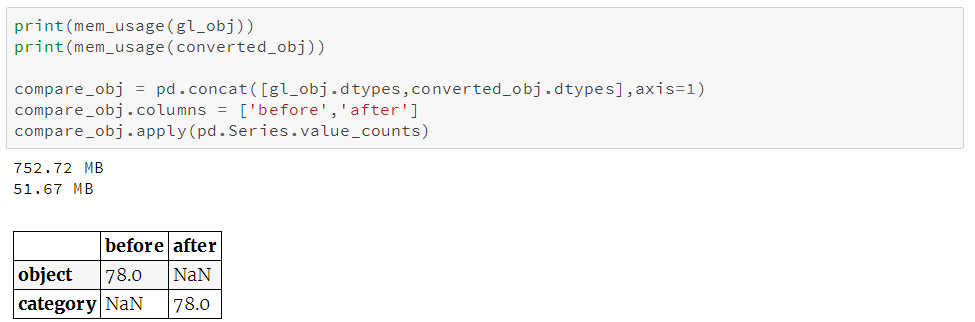
这本例中,所有的object列都被转换成了category类型,但其他数据集就不一定了,所以你最好还是得使用刚才的检查过程。
本例的亮点是内存用量从752.72兆降为51.667兆,降幅达93%。我们将其与我们dataframe的剩下部分合并,看看初始的861兆数据降到了多少。

耶,看来我们的进展还不错!我们还有一招可以做优化,如果你记得我们刚才那张类型表,会发现我们数据集第一列还可以用datetime类型来表示。
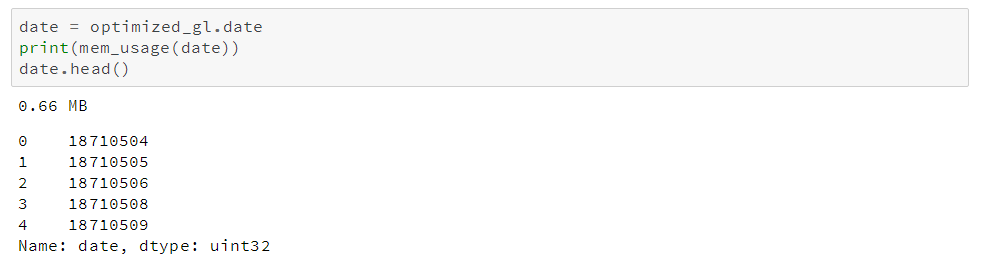
你可能还记得这一列之前是作为整型读入的,并优化成了uint32。因此,将其转换成datetime会占用原来两倍的内存,因为datetime类型是64位比特的。将其转换为datetime的意义在于它可以便于我们进行时间序列分析。
转换使用pandas.to_datetime()函数,并使用format参数告之日期数据存储为YYYY-MM-DD格式。
在数据读入的时候设定数据类型
目前为止,我们探索了一些方法,用来减少现有dataframe的内存占用。通过首先读入dataframe,再对其一步步进行内存优化,我们可以更好地了解这些优化方法能节省多少内存。然而,正如我们之前谈到,我们通常没有足够的内存去表达数据集中的所有数据。如果不能在一开始就创建dataframe,我们怎样才能应用内存节省技术呢?
幸运的是,我们可以在读入数据集的时候指定列的最优数据类型。pandas.read_csv()函数有一些参数可以做到这一点。dtype参数接受一个以列名(string型)为键字典、以Numpy类型对象为值的字典。
首先,我们将每一列的目标类型存储在以列名为键的字典中,开始前先删除日期列,因为它需要分开单独处理。
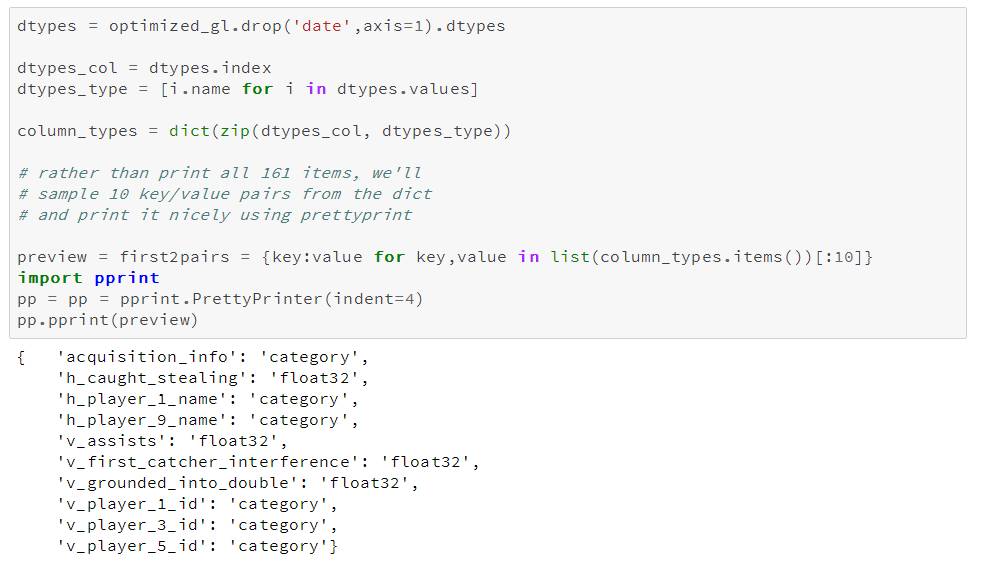
现在我们使用这个字典,同时传入一些处理日期的参数,让日期以正确的格式读入。


通过对列的优化,我们是pandas的内存用量从861.6兆降到104.28兆,有效降低88%。
分析棒球比赛
现在我们有了优化后的数据,可以进行一些分析。我们先看看比赛日的分布情况。
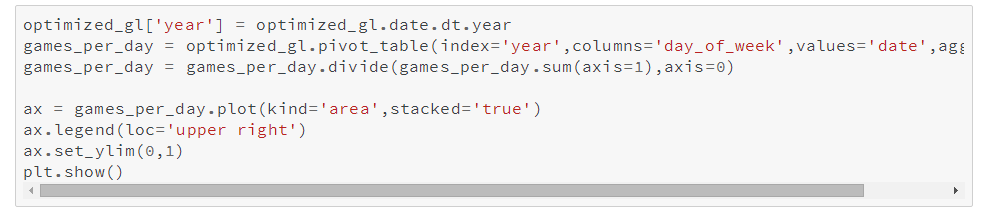
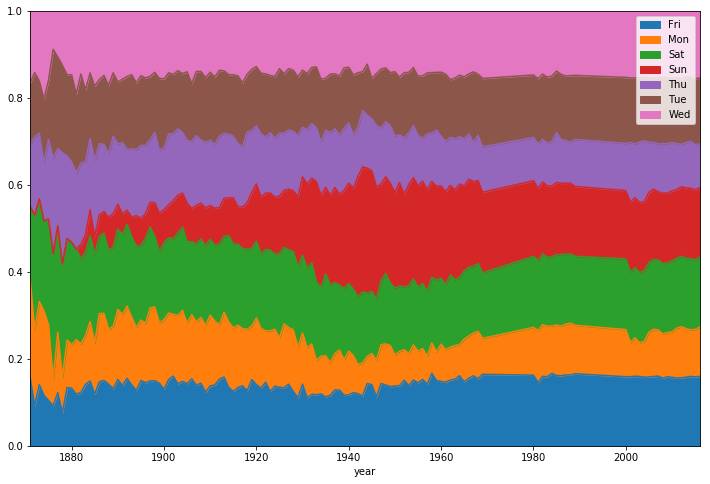
我们可以看到,1920年代之前,周日棒球赛很少是在周日的,随后半个世纪才逐渐增多。
我们也看到最后50年的比赛日分布变化相对比较平稳。
我们来看看比赛时长的逐年变化。

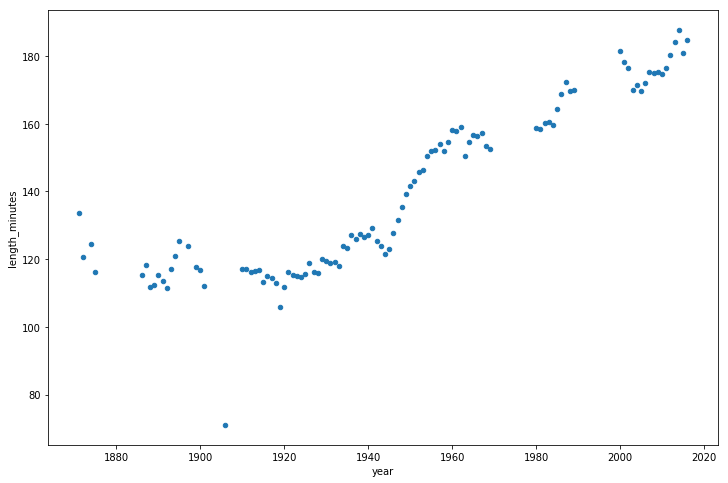
看来棒球比赛时长从1940年代之后逐渐变长。
总结
我们学习了pandas如何存储不同的数据类型,并利用学到的知识将我们的pandas dataframe的内存用量降低了近90%,仅仅只用了一点简单的技巧:
将数值型列降级到更高效的类型
将字符串列转换为类别类型
通过对列的优化,我们是pandas的内存用量从861.6兆降到104.28兆,有效降低88%。
以上所述是小编给大家介绍的python使用pandas处理大数据节省内存技巧详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

python内存管理机制原理详解
python内存管理机制: 引用计数 垃圾回收 内存池 1. 引用计数 当一个python对象被引用时 其引用计数增加 1 ; 当其不再被变量引用时 引用计数减 1 ; 当对象引用计数等于 0 时, 对象被删除(引用计数是一种非常高效的内存管理机制) 2. 垃圾回收 垃圾回收机制: ① 引用计数 , ②标记清除 , ③分带回收 引用计数 : 引用计数也是一种垃圾收集机制, 而且也是一种最直观, 最简单的垃圾收集技术.当python某个对象的引用计数降为 0 时, 说明没有任何引用指向该对象, 该
-
python的内存管理和垃圾回收机制详解
简单来说python的内存管理机制有三种 1)引用计数 2)垃圾回收 3)内存池 接下来我们来详细讲解这三种管理机制 1,引用计数: 引用计数是一种非常高效的内存管理手段,当一个pyhton对象被引用时其引用计数增加1,当其不再被引用时引用计数减1,当引用计数等于0的时候,对象就被删除了. 2,垃圾回收(这是一个很重要知识点): ① 引用计数 引用计数也是一种垃圾回收机制,而且是一种最直观,最简单的垃圾回收技术. 在Python中每一个对象的核心就是一个结构体PyObject,它的内部有一个引
-
python分块读取大数据,避免内存不足的方法
如下所示: def read_data(file_name): ''' file_name:文件地址 ''' inputfile = open(file_name, 'rb') #可打开含有中文的地址 data = pd.read_csv(inputfile, iterator=True) loop = True chunkSize = 1000 #一千行一块 chunks = [] while loop: try: chunk = dcs.get_chunk(chunkSize) chunks
-
简单了解python的内存管理机制
Python引入了一个机制:引用计数. 引用计数 python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收. 总结一下对象会在一下情况下引用计数加1: 1.对象被创建:x=4 2.另外的别人被创建:y=x 3.被作为参数传递给函数:foo(x) 4.作为容器对象的一个元素:a=[1,x,'33'] 引用计数减少情况 1.一个本地引用离开了它的作用域.比如上
-
Python内存读写操作示例
本文实例讲述了Python内存读写操作.分享给大家供大家参考,具体如下: Python中的读写不一定只是文件,还有可能是内存,所以下面实在内存中的读写操作 示例1: # -*- coding:utf-8 -*- #! python3 from io import StringIO f=StringIO() f.write('everything') f.write('is') f.write('possible') print(f.getvalue()) 运行结果: everythingispo
-
python使用pandas处理大数据节省内存技巧(推荐)
一般来说,用pandas处理小于100兆的数据,性能不是问题.当用pandas来处理100兆至几个G的数据时,将会比较耗时,同时会导致程序因内存不足而运行失败. 当然,像Spark这类的工具能够胜任处理100G至几个T的大数据集,但要想充分发挥这些工具的优势,通常需要比较贵的硬件设备.而且,这些工具不像pandas那样具有丰富的进行高质量数据清洗.探索和分析的特性.对于中等规模的数据,我们的愿望是尽量让pandas继续发挥其优势,而不是换用其他工具. 本文我们讨论pandas的内存使用,展示怎样
-
python如何为创建大量实例节省内存
python如何为创建大量实例节省内存,具体内容如下 案例: 某网络游戏中,定义了玩家类Player(id, name, status,....),每有一个在线玩家,在服务器程序内有一个Player的实例,当在线人数很多时,将产生大量实例(百万级别) 需求: 如何降低这些大量实例的内存开销? 如何做? 首先要明白,python中的类可以动态的添加属性,实则在内存中有个__dict__方法维护了这种动态添加属性,它占有内存,把它关掉,不就达到省内存要求了? #!/usr/bin/python3 i
-
python使用pandas抽样训练数据中某个类别实例
废话真的一句也不想多说,直接看代码吧! # -*- coding: utf-8 -*- import numpy from sklearn import metrics from sklearn.svm import LinearSVC from sklearn.naive_bayes import MultinomialNB from sklearn import linear_model from sklearn.datasets import load_iris from sklearn.
-
完美解决TensorFlow和Keras大数据量内存溢出的问题
内存溢出问题是参加kaggle比赛或者做大数据量实验的第一个拦路虎. 以前做的练手小项目导致新手产生一个惯性思维--读取训练集图片的时候把所有图读到内存中,然后分批训练. 其实这是有问题的,很容易导致OOM.现在内存一般16G,而训练集图片通常是上万张,而且RGB图,还很大,VGG16的图片一般是224x224x3,上万张图片,16G内存根本不够用.这时候又会想起--设置batch,但是那个batch的输入参数却又是图片,它只是把传进去的图片分批送到显卡,而我OOM的地方恰是那个"传进去&quo
-
Python使用pandas将表格数据进行处理
目录 前言 一.构建es库中的数据 1.1 创建索引 1.2 插入数据 1.3 查询数据 二.对excel表格中的数据处理操作 2.1 导出es查询的数据 前言 任务描述: 当前有一份excel表格数据,里面存在缺失值,需要对缺失的数据到es数据库中进行查找并对其进行把缺失的数据进行补全. excel表格数据如下所示: 一.构建es库中的数据 1.1 创建索引 # 创建physical_examination索引 PUT /physical_examination { "settings&quo
-
Go语言中节省内存技巧方法示例
目录 引言 预先分配切片 结果 结构体中的字段顺序 极端情况 使用 map[string]struct{} 而不是 map[string]bool 结果 引言 GO虽然不消耗大量内存,但是仍有一些小技巧可以节省内存,良好的编码习惯是每一个程序员都应该具备的素质. 预先分配切片 数组是具有连续内存的相同类型的集合.数组类型定义时要指定长度和元素类型. 因为数组的长度是它们类型的一部分,数组的主要问题是它们大小固定,不能调整. 与数组类型不同,切片类型无需指定长度.切片的声明方式与数组相同,但没有数
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
30个mysql千万级大数据SQL查询优化技巧详解
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用
-
mysql大数据查询优化经验分享(推荐)
正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒. 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化. 实验环境:MacBook Pro MJLQ2CH/A,mysql5.7,数据量:212万+ ONE: select * from article INNER JOIN ( SELECT id FROM article WHERE length(content_url) > 0 an