浅谈python的深浅拷贝以及fromkeys的用法
1.join()的用法:使用前面的字符串.对后面的列表进行拼接,拼接结果是一个字符串
# lst = ["alex","dsb",'wusir','xsb'] # s = "".join(lst) # print(s) #alexdsbwusirxsb
2.split() 根据你给的参数进行切割,切割的结果就是列表
需要把字符串转换成列表 split
把列表转化为字符串 join
# s = "alex_dsb_wusir_xsb"
# lst = s.split("_") #列表
# print(lst)
3.join的迭代拼接
# print("*".join("周润发")) #用迭代的方式进行拼接
# #周*润*发
4.删除操作
# lst = ["篮球","排球","乒乓球","足球","电子竞技","台球"] # for el in lst: # lst.remove(el) # print(lst)#['排球', '足球', '台球']
会发现删不干净 原因是:删除一个.元素的索引重新排序,for循环向后走一个,就漏掉一个
删掉了索引是0的元素,然后索引是1的元素补充到索引为0的位置上,然后索引指向1,
就漏掉了以前的索引为1的元素 因为索引为一的元素在第二次循环的时候已经掉到了索引0的位置
正确的删除操作:
#lst = ["篮球","排球","乒乓球","足球","电子竞技","台球"] # for i in range(len(lst)): #0,1,2,3,4 # lst.pop(0) # print(lst) #[] #永远删索引是0元素 # for i in range(len(lst)): # lst.pop() # print(lst) #[] #从最后一个删
最合理的删除方法:
1,先把需要删除的元素写在一个新的列表中
2.循环这个新列表,删除老列表
5.fromkeys()用法
fromkeys() 帮我们创建字典用
# 把第一个参数进行迭代 拿到的每一项作为key和后面的value组成字典
# d = dict.fromkeys("张无忌","赵敏") #创建字典
# print(d)#{'张': '赵敏', '无': '赵敏', '忌': '赵敏'}
坑 1
# 返回新字典,和原来的字典没有关系
# dic = {}
# d = dic.fromkeys("风扇哥","很困")
# print(dic)# {}
# print(d)#{'风': '很困', '扇': '很困', '哥': '很困'}
# 坑2
# 如果value是可变的数据类型,
# 那么其中一个key对应的value执行更改操作,其他的也跟着改变
d = dict.fromkeys("胡辣汤",[])
print(d)#{'胡': [], '辣': [], '汤': []}
# print(id(d["胡"]))#1797375051912
# print(id(d["辣"]))#1797375051912
# print(id(d["汤"]))#1797375051912
#说明这几个还是同一个[] 所以对其中一个进行改变别的也进行相应的改变
# d["胡"] .append("湖南特色")
# print(d)#{'胡': ['湖南特色'], '辣': ['湖南特色'], '汤': ['湖南特色']}
6.深浅拷贝
先来看一下这个问题
从上到下只有一个列表创建
# lst1 = ["胡辣汤","麻辣香锅","灌汤包","油泼面"]
# lst2 = lst1 #并没有产生新对象.只是一个指向(内存地址)的赋值
# print(id(lst1))#2253612239048
# print(id(lst2))#2253612239048
# lst1.append("葫芦娃")
# print(lst1)#['胡辣汤', '麻辣香锅', '灌汤包', '油泼面', '葫芦娃']
# print(lst2)#['胡辣汤', '麻辣香锅', '灌汤包', '油泼面', '葫芦娃']
用图来解释

# lst1 = ["胡辣汤","麻辣香锅","灌汤包","油泼面"]
# lst2 = lst1.copy() #拷贝,抄作业,可以帮我们创建新的对象,和原来一模一样,浅拷贝
# print(id(lst1))#2232732993736
# print(id(lst2))#2232732993672
#
# lst1.append("葫芦娃")
# print(lst1)
# print(lst2)
用图来解释

# lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅", ["长白山", "白洋淀", "黄鹤楼"]]
# lst2 = lst1.copy() #浅拷贝,只拷贝第一层内容
#
# print(id(lst1))#1199044806792
# print(id(lst2))#1199044806984
# print(lst1)
# print(lst2)
#
# lst1[4].append("葫芦娃")
# print(lst1)
# print(lst2)
用图来解释

#深拷贝 需要引入一个模块
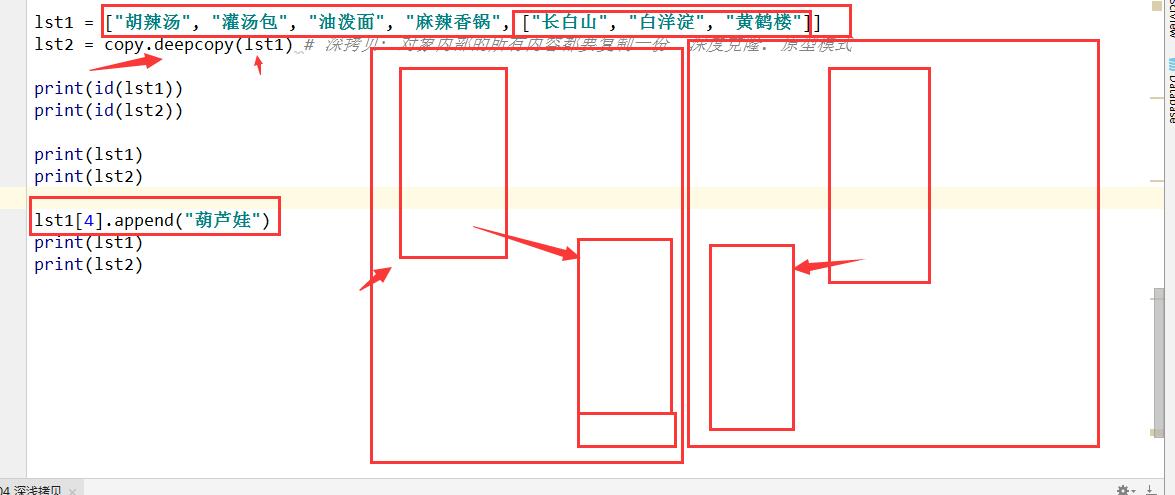
import copy
lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅", ["长白山", "白洋淀", "黄鹤楼"]]
lst2 = copy.deepcopy(lst1)#深拷贝 对象内部的所有内容都要复制一份.深度克隆 原型模式
print(id(lst1))#2150506176840
print(id(lst2))#2150506178120
print(lst1)#['胡辣汤', '灌汤包', '油泼面', '麻辣香锅', ['长白山', '白洋淀', '黄鹤楼']]
print(lst2)#['胡辣汤', '灌汤包', '油泼面', '麻辣香锅', ['长白山', '白洋淀', '黄鹤楼']]
lst1[4].append("葫芦娃")
print(lst1)#['胡辣汤', '灌汤包', '油泼面', '麻辣香锅', ['长白山', '白洋淀', '黄鹤楼', '葫芦娃']]
print(lst2)#['胡辣汤', '灌汤包', '油泼面', '麻辣香锅', ['长白山', '白洋淀', '黄鹤楼']]
用图来解释
为什么要有深浅拷贝?
提高创建速度 计算机中最慢的就是创建对象,需要分配内存各种事情
最快的方式就是以二进制流的方式进行复制 速度最快
以上所述是小编给大家介绍的python的深浅拷贝以及fromkeys的用法详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
浅谈Python对内存的使用(深浅拷贝)
本文主要研究的是Python对内存的使用(深浅拷贝)的相关问题,具体介绍如下. 浅拷贝就是对引用的拷贝(只拷贝父对象) 深拷贝就是对对象的资源的拷贝 >>> a=[1,2,3,'a','b'] >>> b=a >>> b [1, 2, 3, 'a', 'b'] >>> a [1, 2, 3, 'a', 'b'] >>> id(a) 3021737547592 >>> id(b) 3021737547
-

浅析Python中的赋值和深浅拷贝
python中,A object = B object 是一种赋值操作,赋的值不是一个对象在内存中的空间,而只是这个对象在内存中的位置 . 此时当B对象里面的内容发生更改的时候,A对象也自然而然的会跟着更改. name = ["root","admin"] cp_name = name # 对cp_name进行赋值操作 # 对name列表进行插入 name.append('root_temp') print(name,cp_name) # ['root', 'a
-
浅述python中深浅拷贝原理
前言 在c++中参数传递有两种形式:值传递和引用传递.这两种方式的区别我不在此说,自行补上,如果你不知道的话.我先上python代码,看完我们总结一下,代码如下: # copy module import import copy # number and string a = 12 a1 = a a2 = copy.copy(a) a3 = copy.deepcopy(a) # look addr print("==========number=======") print(id(a)
-
详解python深浅拷贝区别
在Python中对象的赋值其实就是对象的引用.当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已. 浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已.也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制 深拷贝:外围和内部元素都进行了拷贝对象本身,而不是引用.也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制. 深浅拷贝的作用 1,减少内存的使用 2,以后在做数据的清洗.修改或者入库的时候,对原数据进行复制一份
-
浅谈python的深浅拷贝以及fromkeys的用法
1.join()的用法:使用前面的字符串.对后面的列表进行拼接,拼接结果是一个字符串 # lst = ["alex","dsb",'wusir','xsb'] # s = "".join(lst) # print(s) #alexdsbwusirxsb 2.split() 根据你给的参数进行切割,切割的结果就是列表 需要把字符串转换成列表 split 把列表转化为字符串 join # s = "alex_dsb_wusir_xsb&q
-
浅谈Python 列表字典赋值的陷阱
今天在用python刷leetcode 3Sum problem时,调入到了一个大坑中,检查半天并没有任何逻辑错误,但输出结果却总是不对,最终通过调试发现原来python中list和dict类型直接赋值竟然是浅拷贝!!!因此,在实际实验中,若要实现深拷贝,建立新list或dict,使新建的list或dict变量和以前的变量只是具有相同的值,但是却具有不同的存储地址,保证在改变以前的list变量的时候,不会对新的list产生任何影响. python中的深拷贝的实现需要通过copy.deepcopy
-
浅谈Python基础之I/O模型
一.I/O模型 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口. 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别? 这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blockin
-
浅谈Python中的可变对象和不可变对象
什么是可变/不可变对象 不可变对象,该对象所指向的内存中的值不能被改变.当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址. 可变对象,该对象所指向的内存中的值可以被改变.变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变. Python中,数值类型(int和float).字符串str.元组tuple都是不可变类型.而列表list.字典dict.集合
-
浅谈Python实现2种文件复制的方法
本文实例主要实现Python中的文件复制操作,有两种方法,具体实现代码如下所示: #coding:utf-8 # 方法1:使用read()和write()模拟实现文件拷贝 # 创建文件hello.txt src = file("hello.txt", "w") li = ["Hello world \n", "Hello China \n"] src.writelines(li) src.close() #把hello.txt
-
浅谈python连续赋值可能引发的错误
今天写的代码片段: X = Y = [] .. X.append(x) Y.append(y) 其中x和y是读取的每一个数据的xy值,打算将其归入列表之后绘散点图,但是绘图出来却是一条直线,数据本身并不是这样分布的. 反复检查后,发现是X = Y =[]这一句的错误. 在python中,形如X = Y的拷贝都是浅拷贝,X和Y是公用同一块空间的,一旦对它们其中的任意一个进行数据操作,都会改变该空间的内容,除非重新赋一块空间,改变其指向的位置. 因此只需要改成: X = [] Y = [] 就可以运
-
Python字典深浅拷贝与循环方式方法详解
本节内容 深浅拷贝 循环方式 字典常用方法总结 一.深浅拷贝 列表.元组.字典(以及其他) 对于列表.元组和字典而言,进行赋值(=).浅拷贝(copy).深拷贝(deepcopy)而言,其内存地址是变化不通的. 赋值(=) 赋值只是创建一个变量,该变量指向原来的内存地址 >>> name1 = ['a','b',['m','n'],'c'] >>> name2 = name1 #输出结果,两个内存地址是一样的 >>> print(id(name1),'
-
浅谈Python中os模块及shutil模块的常规操作
如下所示: #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表.这个列表以字母顺序. 它不包括 '.' 和'..' 即使它在文件夹中. #只支持在 Unix, Windows 下使用 import os, sys # 打开文件 path=r'C:\Users\Administrator.SKY-20180518VHY\Desktop\rx\ore' dirs = os.listdir( path ) print(dirs) # 输出所有文件和文件夹 for fil