tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解
1.作用
- dataset.shuffle作用是将数据进行打乱操作,传入参数为buffer_size,改参数为设置“打乱缓存区大小”,也就是说程序会维持一个buffer_size大小的缓存,每次都会随机在这个缓存区抽取一定数量的数据
- dataset.batch作用是将数据打包成batch_size
- dataset.repeat作用就是将数据重复使用多少epoch
2.各种不同顺序的区别
示例代码(以下面代码作为说明):
# -*- coding: utf-8 -*- import tensorflow as tf import numpy as np dataset = tf.data.Dataset.from_tensor_slices(np.arange(20).reshape((4, 5))) dataset = dataset.shuffle(100) dataset = dataset.batch(3) dataset = dataset.repeat(2) sess = tf.Session() iterator = dataset.make_one_shot_iterator() input_x = iterator.get_next() print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x))
1.顺序1(训练过程最常用的顺序)
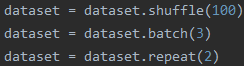
先看结果:
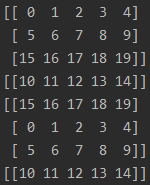
解释:相当于把所有数据先打乱,然后打包成batch输出,整体数据重复2个epoch
特点:1.一个batch中的数据不会重复;2.每个epoch的最后一个batch的尺寸小于等于batch_size
2.顺序2
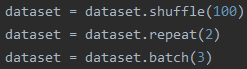
先看结果:
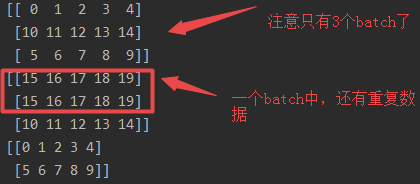
解释:相当于把所有数据先打乱,再把所有数据重复两个epoch,然后将重复两个epoch的数据放在一起,最后打包成batch_size输出
特点:1.因为把数据复制两份,还进行打乱,因此某个batch数据可能会重复,而且出现重复数据的batch只会是两个batch交叉的位置;2.最后一个batch的尺寸小于等于batch_size
3.顺序3
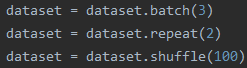
先看结果:
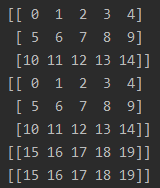
解释:相当于把所有数据先打包成batch,然后把打包成batch的数据重复两遍,最后再将所有batch打乱进行输出
特点:1.打乱的是batch;2.某些batch的尺寸小于等于batch_size,因为是对batch进行打乱,所以这些batch不一定是最后一个
3.其他组合方式
根据上面几种顺序,大家可以自己分析其他顺序的输出结果
到此这篇关于tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解的文章就介绍到这了,更多相关tensorflow dataset.shuffle、dataset.batch、dataset.repeat内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈tensorflow中dataset.shuffle和dataset.batch dataset.repeat注意点
batch很好理解,就是batch size.注意在一个epoch中最后一个batch大小可能小于等于batch size dataset.repeat就是俗称epoch,但在tf中与dataset.shuffle的使用顺序可能会导致个epoch的混合 dataset.shuffle就是说维持一个buffer size 大小的 shuffle buffer,图中所需的每个样本从shuffle buffer中获取,取得一个样本后,就从源数据集中加入一个样本到shuffle buffer中. imp
-
TensorFlow dataset.shuffle、batch、repeat的使用详解
直接看代码例子,有详细注释!! import tensorflow as tf import numpy as np d = np.arange(0,60).reshape([6, 10]) # 将array转化为tensor data = tf.data.Dataset.from_tensor_slices(d) # 从data数据集中按顺序抽取buffer_size个样本放在buffer中,然后打乱buffer中的样本 # buffer中样本个数不足buffer_size,继续从data数据
-
tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解
1.作用 dataset.shuffle作用是将数据进行打乱操作,传入参数为buffer_size,改参数为设置"打乱缓存区大小",也就是说程序会维持一个buffer_size大小的缓存,每次都会随机在这个缓存区抽取一定数量的数据 dataset.batch作用是将数据打包成batch_size dataset.repeat作用就是将数据重复使用多少epoch 2.各种不同顺序的区别 示例代码(以下面代码作为说明): # -*- coding: utf-8 -*- import ten
-
pytorch torch.expand和torch.repeat的区别详解
1.torch.expand 函数返回张量在某一个维度扩展之后的张量,就是将张量广播到新形状.函数对返回的张量不会分配新内存,即在原始张量上返回只读视图,返回的张量内存是不连续的.类似于numpy中的broadcast_to函数的作用.如果希望张量内存连续,可以调用contiguous函数. 例子: import torch x = torch.tensor([1, 2, 3, 4]) xnew = x.expand(2, 4) print(xnew) 输出: tensor([[1, 2, 3,
-
关于win10在tensorflow的安装及在pycharm中运行步骤详解
本文介绍在win10中安装tensorflow的步骤: 1.安装anaconda3 2.新建conda环境变量,可建多个环境在内部安装多个tensorflow版本,1.x和2.x版本功能差别太大,代码也很大区别 3.环境中安装python和fensorflow 4.用tensorflow运行一段测试程序 安装anaconda下载地址(清华镜像): https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/选择最新版本 开始安装anaconda 选
-
对Tensorflow中权值和feature map的可视化详解
前言 Tensorflow中可以使用tensorboard这个强大的工具对计算图.loss.网络参数等进行可视化.本文并不涉及对tensorboard使用的介绍,而是旨在说明如何通过代码对网络权值和feature map做更灵活的处理.显示和存储.本文的相关代码主要参考了github上的一个小项目,但是对其进行了改进. 原项目地址为(https://github.com/grishasergei/conviz). 本文将从以下两个方面进行介绍: 卷积知识补充 网络权值和feature map的可
-
对tensorflow中tf.nn.conv1d和layers.conv1d的区别详解
在用tensorflow做一维的卷积神经网络的时候会遇到tf.nn.conv1d和layers.conv1d这两个函数,但是这两个函数有什么区别呢,通过计算得到一些规律. 1.关于tf.nn.conv1d的解释,以下是Tensor Flow中关于tf.nn.conv1d的API注解: Computes a 1-D convolution given 3-D input and filter tensors. Given an input tensor of shape [batch, in_wi
-

C++ 成员变量的初始化顺序问题详解
C++ 成员变量的初始化顺序问题详解 问题来源: 由于面试题中,考官出了一道简单的程序输出结果值的题:如下, class A { private: int n1; int n2; public: A():n2(0),n1(n2+2){} void Print(){ cout << "n1:" << n1 << ", n2: " << n2 <<endl; } }; int main() { A a; a.P
-
DOM事件阶段以及事件捕获与事件冒泡先后执行顺序(图文详解)
俗话说的好,好记性不如个烂笔头,这么多技术文章如果不去吃透,技术点很快就容易忘掉,下面是小编平时浏览的技术文章,整理的笔记,分享给大家. 开发过程中我们都希望使用别人成熟的框架,因为站在巨人的肩膀上会使得我们开发的效率大幅度提升.不过,我们也应该.必须了解其基本原理.比如DOM事件,jquery框架帮我们为我们封装和抽象了各浏览器的差异行为,为事件处理带来了极大的便利.不过浏览器逐步走向统一和标准化,我们可以更加安全地使用官方规范的接口.因为只有获得众多开发者的芳心,浏览器才会走得更远.正如我们
-
tensorflow: variable的值与variable.read_value()的值区别详解
问题 查看 tensorflow api manual 时,看到关于 variable.read_value() 的注解如图: 那么在 tensorflow 中,variable的值 与 variable.read_value()的值 到底有何区别? 实验代码 # coding=utf-8 import tensorflow as tf # Create a variable. w = tf.Variable(initial_value=10., dtype=tf.float32) sess =
-
对java for 循环执行顺序的详解
如下所示: for(表达式1;表达式2;表达式3) { //循环体 } 先执行"表达式1",再进行"表达式2"的判断,判断为真则执行 "循环体",循环体执行完以后执行表达式3. 例如 for(int i=0;i<2;i++){ //TODO } 先执行 int i = 0; 然后 判断 i<2 然后执行函数体 最后执行i++ 然后轮回到判断i<2 int[] arr = new int[3]; int j; arr[0] = 1