详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None,figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
xerr=None,secondary_y=False, sort_columns=False, **kwds)
参数详解如下:
Parameters: x : label or position, default None#指数据框列的标签或位置参数 y : label or position, default None kind : str ‘line' : line plot (default)#折线图 ‘bar' : vertical bar plot#条形图 ‘barh' : horizontal bar plot#横向条形图 ‘hist' : histogram#柱状图 ‘box' : boxplot#箱线图 ‘kde' : Kernel Density Estimation plot#Kernel 的密度估计图,主要对柱状图添加Kernel 概率密度线 ‘density' : same as ‘kde' ‘area' : area plot#不了解此图 ‘pie' : pie plot#饼图 ‘scatter' : scatter plot#散点图 需要传入columns方向的索引 ‘hexbin' : hexbin plot#不了解此图 ax : matplotlib axes object, default None#**子图(axes, 也可以理解成坐标轴) 要在其上进行绘制的matplotlib subplot对象。如果没有设置,则使用当前matplotlib subplot**其中,变量和函数通过改变figure和axes中的元素(例如:title,label,点和线等等)一起描述figure和axes,也就是在画布上绘图。 subplots : boolean, default False#判断图片中是否有子图 Make separate subplots for each column sharex : boolean, default True if ax is None else False#如果有子图,子图共x轴刻度,标签 In case subplots=True, share x axis and set some x axis labels to invisible; defaults to True if ax is None otherwise False if an ax is passed in; Be aware, that passing in both an ax and sharex=True will alter all x axis labels for all axis in a figure! sharey : boolean, default False#如果有子图,子图共y轴刻度,标签 In case subplots=True, share y axis and set some y axis labels to invisible layout : tuple (optional)#子图的行列布局 (rows, columns) for the layout of subplots figsize : a tuple (width, height) in inches#图片尺寸大小 use_index : boolean, default True#默认用索引做x轴 Use index as ticks for x axis title : string#图片的标题用字符串 Title to use for the plot grid : boolean, default None (matlab style default)#图片是否有网格 Axis grid lines legend : False/True/'reverse'#子图的图例,添加一个subplot图例(默认为True) Place legend on axis subplots style : list or dict#对每列折线图设置线的类型 matplotlib line style per column logx : boolean, default False#设置x轴刻度是否取对数 Use log scaling on x axis logy : boolean, default False Use log scaling on y axis loglog : boolean, default False#同时设置x,y轴刻度是否取对数 Use log scaling on both x and y axes xticks : sequence#设置x轴刻度值,序列形式(比如列表) Values to use for the xticks yticks : sequence#设置y轴刻度,序列形式(比如列表) Values to use for the yticks xlim : 2-tuple/list#设置坐标轴的范围,列表或元组形式 ylim : 2-tuple/list rot : int, default None#设置轴标签(轴刻度)的显示旋转度数 Rotation for ticks (xticks for vertical, yticks for horizontal plots) fontsize : int, default None#设置轴刻度的字体大小 Font size for xticks and yticks colormap : str or matplotlib colormap object, default None#设置图的区域颜色 Colormap to select colors from. If string, load colormap with that name from matplotlib. colorbar : boolean, optional #图片柱子 If True, plot colorbar (only relevant for ‘scatter' and ‘hexbin' plots) position : float Specify relative alignments for bar plot layout. From 0 (left/bottom-end) to 1 (right/top-end). Default is 0.5 (center) layout : tuple (optional) #布局 (rows, columns) for the layout of the plot table : boolean, Series or DataFrame, default False #如果为正,则选择DataFrame类型的数据并且转换匹配matplotlib的布局。 If True, draw a table using the data in the DataFrame and the data will be transposed to meet matplotlib's default layout. If a Series or DataFrame is passed, use passed data to draw a table. yerr : DataFrame, Series, array-like, dict and str See Plotting with Error Bars for detail. xerr : same types as yerr. stacked : boolean, default False in line and bar plots, and True in area plot. If True, create stacked plot. sort_columns : boolean, default False # 以字母表顺序绘制各列,默认使用前列顺序 secondary_y : boolean or sequence, default False ##设置第二个y轴(右y轴) Whether to plot on the secondary y-axis If a list/tuple, which columns to plot on secondary y-axis mark_right : boolean, default True When using a secondary_y axis, automatically mark the column labels with “(right)” in the legend kwds : keywords Options to pass to matplotlib plotting method Returns:axes : matplotlib.AxesSubplot or np.array of them
1、画图图形
import pandas as pd
from pandas import DataFrame,Series
df = pd.DataFrame(np.random.randn(4,4),index = list('ABCD'),columns=list('OPKL'))
df
Out[4]:
O P K L
A -1.736654 0.327206 -1.000506 1.235681
B 1.216879 0.506565 0.889197 -1.478165
C 0.091957 -2.677410 -0.973761 0.123733
D -1.114622 -0.600751 -0.159181 1.041668
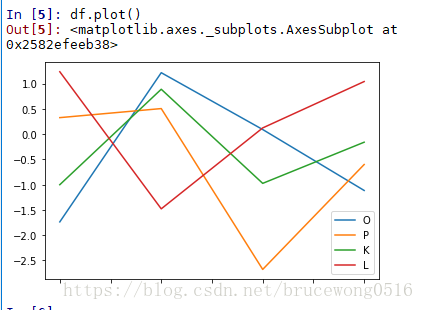
注意一下散点图scatter是需要传入两个Y的columns参数的:
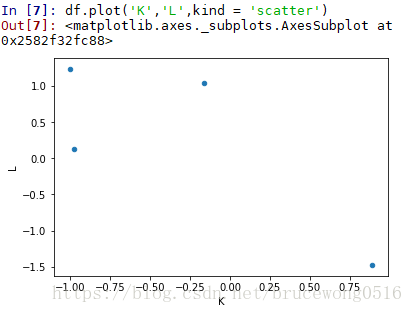
传入x,y参数

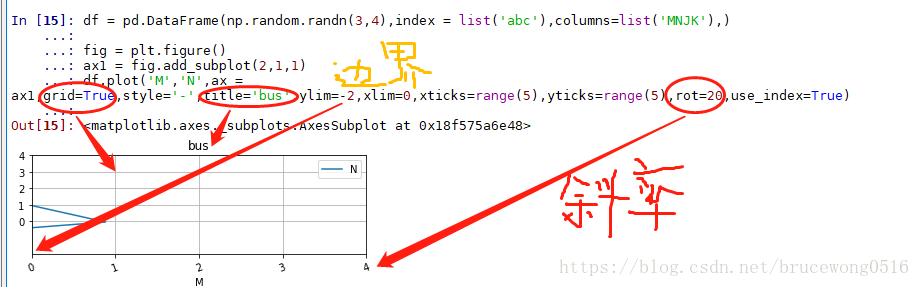
同时画多个子图,可以设置 subplot = True

2、注意事项:
- 在画图时,要注意首先定义画图的画布:fig = plt.figure( )
- 然后定义子图ax ,使用 ax= fig.add_subplot( 行,列,位置标)
- 当上述步骤完成后,可以用 ax.plot()函数或者 df.plot(ax = ax)
- 在jupternotebook 需要用%定义:%matplotlib notebook;如果是在脚本编译器上则不用,但是需要一次性按流程把代码写完;
- 结尾时都注意记录上plt.show()

到此这篇关于详解pandas.DataFrame.plot() 画图函数的文章就介绍到这了,更多相关pandas.DataFrame.plot( )画图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用pandas的DataFrame的plot方法绘制图像的实例
使用了pandas的Series方法绘制图像体验之后感觉直接用matplotlib的功能好用了不少,又试用了DataFrame的方法之后发现这个更加人性化. 写代码如下: from pandas import Series,DataFrame from numpy.random import randn import numpy as np import matplotlib.pyplot as plt df = DataFrame(randn(10,5),columns=['A','B','C
-
详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数 DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False,
-

详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧. 首先,还是列出一个我们用的DataFrame,注意index一列,如下: 接下来,介绍下各个函数的用法: 1.loc函数 愿意看官方文档的,请戳这里,这里一般最权威. loc函数是基于"标签"选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例: 1.1 单个label 接受一个"标签"(
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解pandas中缺失数据处理的函数
目录 一.缺失值类型 1.np.nan 2.None 3.NA标量 二.缺失值判断 1.对整个dataframe判断缺失 2.对某个列判断缺失 三.缺失值统计 1.列缺失 2.行缺失 3.缺失率 四.缺失值筛选 五.缺失值填充 六.缺失值删除 1.全部直接删除 2.行缺失删除 3.列缺失删除 4.按缺失率删除 七.缺失值参与计算 1.加法 2.累加 3.计数 4.聚合分组 五.源码 今天分享一篇pandas缺失值处理的操作指南! 一.缺失值类型 在pandas中,缺失数据显示为NaN.缺失值有3
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd
-
详解pandas获取Dataframe元素值的几种方法
可以通过遍历的方法: pandas按行按列遍历Dataframe的几种方式:https://www.jb51.net/article/172623.htm 选择列 使用类字典属性,返回的是Series类型 data['w'] 遍历Series for index in data['w'] .index: time_dis = data['w'] .get(index) pandas.DataFrame.at 根据行索引和列名,获取一个元素的值 >>> df = pd.DataFrame(
-
详解pandas绘制矩阵散点图(scatter_matrix)的方法
使用散点图矩阵图,可以两两发现特征之间的联系 pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds) 1.frame,pandas dataframe对象 2.alpha, 图像透明度,一般取(0,1] 3.figsize,以英寸为单
-
详解Pandas 处理缺失值指令大全
前言 运用pandas 库对所得到的数据进行数据清洗,复习一下相关的知识. 1 数据清洗 1.1 处理缺失数据 对于数值型数据,分为缺失值(NAN)和非缺失值,对于缺失值的检测,可以通过Python中pandas库的Series类对象的isnull方法进行检测. import pandas as pd import numpy as np string_data = pd.Series(['Benzema', 'Messi', np.nan, 'Ronaldo']) string_data.is
-
详解pandas映射与数据转换
在 pandas 中提供了利用映射关系来实现某些操作的函数,具体如下: replace() 函数:替换元素: map() 函数:新建一列: rename() 函数:替换索引. 一.replace() 用映射替换元素 在数据处理时,经常会遇到需要将数据结构中原来的元素根据实际需求替换成新元素的情况.要想用新元素替换原来元素,就需要定义一组映射关系.在映射关系中,将旧元素作为键,新元素作为值. 例如,创建字典 fruits 用于指明水果标识和水果名称的映射关系. fruits={101:'orang