scrapy框架携带cookie访问淘宝购物车功能的实现代码
scrapy框架简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
scrapy架构图

- crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)

正文开始
我们知道,有的网页必须要登录才能访问其内容。scrapy登录的实现一般就三种方式。
1.在第一次请求中直接携带用户名和密码。
2.必须要访问一次目标地址,服务器返回一些参数,例如验证码,一些特定的加密字符串等,自己通过相应手段分析与提取,第二次请求时带上这些参数即可。可以参考https://www.cnblogs.com/bertwu/p/13210539.html
3.不必花里胡哨,直接手动登录成功,然后提取出cookie,加入到访问头中即可。
本文以第三种为例,实现scrapy携带cookie访问购物车。
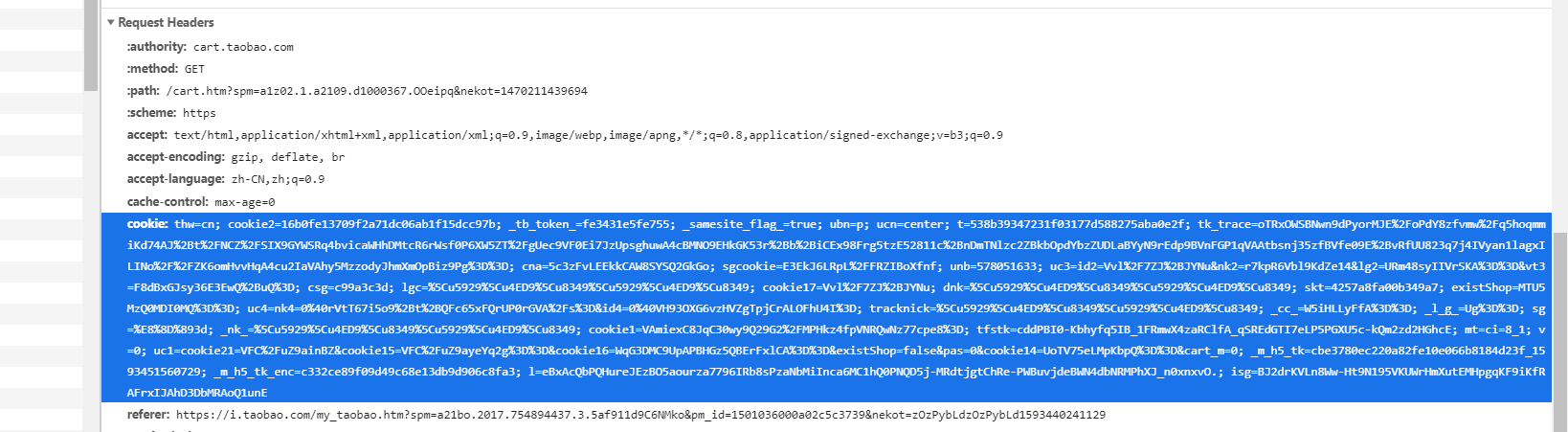
1.先手动登录自己的淘宝账号,从中提取出cookie,如下图中所示。
2.cmd中workon自己的虚拟环境,创建项目 (scrapy startproject taobao)
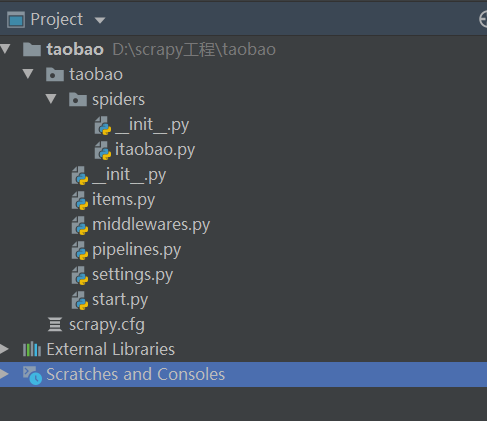
3.pycharm打开项目目录 ,在terminal中输入(scrapy genspider itaobao taobao.com),得到如下的目录结构
4.setting中设置相应配置
5. 在itaobao中写业务代码。我们先不加人cookie直接访问购物车,代码如下:
import scrapy
class ItaobaoSpider(scrapy.Spider):
name = 'itaobao'
allowed_domains = ['taobao.com']
start_urls = [
'https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694'] # 第一次就直接访问购物车
def parse(self, response):
print(response.text)
响应回来信息如下
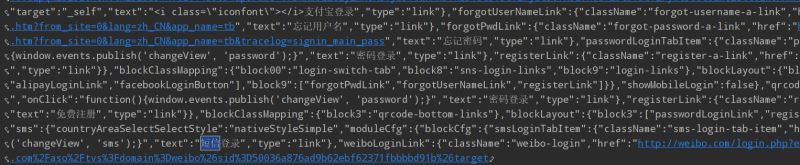
明显是跳转到登录页面的意思。
6.言归正传,正确的代码如下,需要重写start_requests()方法,此方法可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求。
import scrapy
class ItaobaoSpider(scrapy.Spider):
name = 'itaobao'
allowed_domains = ['taobao.com']
# start_urls = ['https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694']
# 需要重写start_requests方法
def start_requests(self):
url = "https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694"
# 此处的cookie为手动登录后从浏览器粘贴下来的值
cookie = "thw=cn; cookie2=16b0fe13709f2a71dc06ab1f15dcc97b; _tb_token_=fe3431e5fe755;" \
" _samesite_flag_=true; ubn=p; ucn=center; t=538b39347231f03177d588275aba0e2f;" \
" tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5hoqmmiKd74AJ%2Bt%2FNCZ%" \
"2FSIX9GYWSRq4bvicaWHhDMtcR6rWsf0P6XW5ZT%2FgUec9VF0Ei7JzUpsghuwA4cBMNO9EHkGK53r%" \
"2Bb%2BiCEx98Frg5tzE52811c%2BnDmTNlzc2ZBkbOpdYbzZUDLaBYyN9rEdp9BVnFGP1qVAAtbsnj35zfBVfe09E%" \
"2BvRfUU823q7j4IVyan1lagxILINo%2F%2FZK6omHvvHqA4cu2IaVAhy5MzzodyJhmXmOpBiz9Pg%3D%3D; " \
"cna=5c3zFvLEEkkCAW8SYSQ2GkGo; sgcookie=E3EkJ6LRpL%2FFRZIBoXfnf; unb=578051633; " \
"uc3=id2=Vvl%2F7ZJ%2BJYNu&nk2=r7kpR6Vbl9KdZe14&lg2=URm48syIIVrSKA%3D%3D&vt3=F8dBxGJsy36E3EwQ%2BuQ%3D;" \
" csg=c99a3c3d; lgc=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; cookie17=Vvl%2F7ZJ%2BJYNu;" \
" dnk=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; skt=4257a8fa00b349a7; existShop=MTU5MzQ0MDI0MQ%3D%3D;" \
" uc4=nk4=0%40rVtT67i5o9%2Bt%2BQFc65xFQrUP0rGVA%2Fs%3D&id4=0%40VH93OXG6vzHVZgTpjCrALOFhU4I%3D;" \
" tracknick=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; _cc_=W5iHLLyFfA%3D%3D; " \
"_l_g_=Ug%3D%3D; sg=%E8%8D%893d; _nk_=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349;" \
" cookie1=VAmiexC8JqC30wy9Q29G2%2FMPHkz4fpVNRQwNz77cpe8%3D; tfstk=cddPBI0-Kbhyfq5IB_1FRmwX4zaRClfA" \
"_qSREdGTI7eLP5PGXU5c-kQm2zd2HGhcE; mt=ci=8_1; v=0; uc1=cookie21=VFC%2FuZ9ainBZ&cookie15=VFC%2FuZ9ayeYq2g%3D%3D&cookie" \
"16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&existShop=false&pas=0&cookie14=UoTV75eLMpKbpQ%3D%3D&cart_m=0;" \
" _m_h5_tk=cbe3780ec220a82fe10e066b8184d23f_1593451560729; _m_h5_tk_enc=c332ce89f09d49c68e13db9d906c8fa3; " \
"l=eBxAcQbPQHureJEzBO5aourza7796IRb8sPzaNbMiInca6MC1hQ0PNQD5j-MRdtjgtChRe-PWBuvjdeBWN4dbNRMPhXJ_n0xnxvO.; " \
"isg=BJ2drKVLn8Ww-Ht9N195VKUWrHmXutEMHpgqKF9iKfRAFrxIJAhD3DbMRAoQ1unE"
cookies = {}
# 提取键值对 请求头中携带cookie必须是一个字典,所以要把原生的cookie字符串转换成cookie字典
for cookie in cookie.split(';'):
key, value = cookie.split("=", 1)
cookies[key] = value
yield scrapy.Request(url=url, cookies=cookies, callback=self.parse)
def parse(self, response):
print(response.text)
响应信息如下(部分片段):
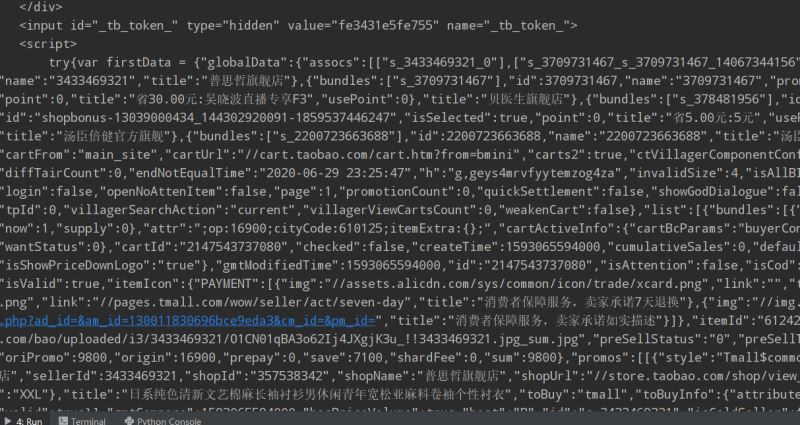
很明显这是自己购物车的真实源代码。
好了,大功告成啦,接下来就可以按照业务需求用xpath(自己喜欢用这种方式)提取自己想要的信息了。
总结
到此这篇关于scrapy框架携带cookie访问淘宝购物车的文章就介绍到这了,更多相关scrapy框架cookie内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
深入剖析Python的爬虫框架Scrapy的结构与运作流程
网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人.当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个"机器人"其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且在爬行的时候会搜集一些信息.例如 Google 就有一大堆爬虫会在 Internet 上搜集网页内容以及它们之间的链接等信息:又比如一些别有用心的爬虫会在 Internet 上搜集诸如 foo@bar.com 或者 foo [at] bar [dot] com 之类的东
-
Python3安装Scrapy的方法步骤
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Pytho
-
python使用scrapy发送post请求的坑
使用requests发送post请求 先来看看使用requests来发送post请求是多少好用,发送请求 Requests 简便的 API 意味着所有 HTTP 请求类型都是显而易见的.例如,你可以这样发送一个 HTTP POST 请求: >>>r = requests.post('http://httpbin.org/post', data = {'key':'value'}) 使用data可以传递字典作为参数,同时也可以传递元祖 >>>payload = (('ke
-
详解Python安装scrapy的正确姿势
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手底下有了千军万马.Scr
-
使用Python的Scrapy框架编写web爬虫的简单示例
在这个教材中,我们假定你已经安装了Scrapy.假如你没有安装,你可以参考这个安装指南. 我们将会用开放目录项目(dmoz)作为我们例子去抓取. 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项目 定义您将提取的Item 编写一个蜘蛛去抓取网站并提取Items. 编写一个Item Pipeline用来存储提出出来的Items Scrapy由Python写成.假如你刚刚接触Python这门语言,你可能想要了解这门语言起,怎么最好的利用这门语言.假如你已经熟悉其它类似的语言,想要快速
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
scrapy框架携带cookie访问淘宝购物车功能的实现代码
scrapy框架简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便 scrapy架构图 crapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整
-
vue实现的仿淘宝购物车功能详解
本文实例讲述了vue实现的仿淘宝购物车功能.分享给大家供大家参考,具体如下: 下面是一张众所周知的淘宝购物车页面,今天要讲解的案例就是用vue.js做一个类似的页面 首先简单介绍一下可能会用到的一些vue.js的用法: v-bind,绑定属性:例如v-bind:class="{'class1':flag}",这是常用的绑定样式的方法,如果flag为true则class=class1:v-bind:src="image",image就是图像的路径; v-if=&quo
-
vue实现淘宝购物车功能
本文实例为大家分享了vue实现淘宝购物车的具体代码,供大家参考,具体内容如下 淘宝购物车功能,效果如下图 非常简单的逻辑,没有做代码的封装,代码如下 <div class="list-container"> <div class="top-ops"> <div> <img src="../../../static/images/HomeRecommendShopInfoAdress@2x.png" alt
-
Python实现淘宝秒杀功能的示例代码
1.安装 Selenium 模块 Selenium支持很多浏览器,我选择的是Firefox浏览器. 安装方法: ①打开cmd: ②输入命令 pip install selenium: ③回车,等待自动安装: ④当最后一行代码出现Successfully install selenium-XX时,表示安装成功. 2. 插件 FireBug FireBug 是火狐浏览器的一款查看代码元素的插件,可以快速的定位元素,selenium的重点就是元素定位,只有定到位了,才能进行下一步操作. 测试安装成功,
-
原生js实现淘宝购物车功能
js淘宝购物车功能描述: 1.点击"+",单个商品数量加1,总数量加1:单个商品价格添加,总价也添加. 2.点击"-",单个商品数量减1,总数量减1:单个商品价格减少,总价也减少. 当该商品数量为0时,点击依然为0: 3.显示出总价,总数量和其中最贵的那个商品的价格. 瞄一眼效果图: 废话不多说,LU代码 <html> <head> <meta http-equiv="Content-Type" content
-
jQuery模拟淘宝购物车功能
首先我们要实现的内容的需求有如下几点: 1.在购物车页面中,当选中"全选"复选框时,所有商品前的复选框被选中,否则所有商品的复选框取消选中. 2.当所有商品前的复选框选中时,"全选"复选框被选中,否则"全选"复选框取消选中. 3.单击图标-的时候数量减一而且不能让物品小于0并且商品总价与积分随之改变. 4.单击图标+的时候数量增加并且商品总价与积分随之改变. 5.单击删除所选将删除用户选中商品,单击删除则删除该商品即可并达到商品总价与积分随之改变
-
原生js模拟淘宝购物车项目实战
本文实例讲述了原生js模拟淘宝购物车实现代码.分享给大家供大家参考.具体如下: 通过JavaScript实现类似与淘宝的购物车效果,包括商品的单选.全选.删除.修改数量.价格计算.数目计算.预览等功能的实现.实现的效果图: 相应的代码: shoppingCart.html <!DOCTYPE html> <html> <head> <meta charset = "UTF-8"> <title>JavaScript实现购物车项
-
js实现百度淘宝搜索功能
本文实例为大家分享了js实现百度淘宝搜索功能的具体代码,供大家参考,具体内容如下 由于没有后台数据,用数组模拟一下后台返回的数据 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=
-
Android实现的仿淘宝购物车demo示例
本文实例讲述了Android实现的仿淘宝购物车.分享给大家供大家参考,具体如下: 夏的热情渐渐退去,秋如期而至,丰收的季节,小编继续着实习之路,走着走着,就走到了购物车,逛过淘宝或者是京东的小伙伴都知道购物车里面的宝贝可不止一件,对于爱购物的姑娘来说,购物车里面的商品恐怕是爆满,添加不进去了,以前逛淘宝的时候,小编没有想过要怎么样实现购物车,就知道在哪儿一个劲儿的逛,但是现在不一样了,小编做为一个开发者,想的就是该如何实现,捣鼓了两天的时间,用listview来实现,已经有模有样了,现在小编就来
-
Android实现仿淘宝购物车增加和减少商品数量功能demo示例
本文实例讲述了Android实现仿淘宝购物车增加和减少商品数量功能.分享给大家供大家参考,具体如下: 在前面一篇<Android实现的仿淘宝购物车demo示例>中,小编简单的介绍了如何使用listview来实现购物车,但是仅仅是简单的实现了列表的功能,随之而来一个新的问题,买商品的时候,我们可能不止想买一件商品,想买多个,或许有因为某种原因点错了,本来想买一件来着,小手不小心抖了一下,把数量错点成了三个,这个时候就涉及到一个新的功能,那就是增加和减少商品的数量,今天这篇博文,小编就来和小伙伴们