Keras SGD 随机梯度下降优化器参数设置方式
SGD 随机梯度下降
Keras 中包含了各式优化器供我们使用,但通常我会倾向于使用 SGD 验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。
Keras 中文文档中对 SGD 的描述如下:
keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)
随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量
参数:
lr:大或等于0的浮点数,学习率
momentum:大或等于0的浮点数,动量参数
decay:大或等于0的浮点数,每次更新后的学习率衰减值
nesterov:布尔值,确定是否使用Nesterov动量
参数设置
Time-Based Learning Rate Schedule
Keras 已经内置了一个基于时间的学习速率调整表,并通过上述参数中的 decay 来实现,学习速率的调整公式如下:
LearningRate = LearningRate * 1/(1 + decay * epoch)
当我们初始化参数为:
LearningRate = 0.1
decay = 0.001
大致变化曲线如下(非实际曲线,仅示意):
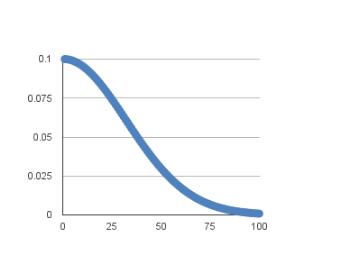
当然,方便起见,我们可以将优化器设置如下,使其学习速率随着训练轮次变化:
sgd = SGD(lr=learning_rate, decay=learning_rate/nb_epoch, momentum=0.9, nesterov=True)
Drop-Based Learning Rate Schedule
另外一种学习速率的调整方法思路是保持一个恒定学习速率一段时间后立即降低,是一种突变的方式。通常整个变化趋势为指数形式。
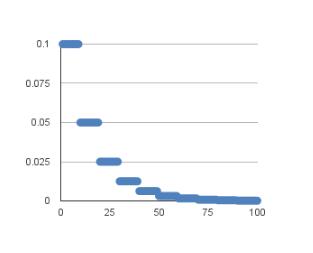
对应的学习速率变化公式如下:
LearningRate = InitialLearningRate * DropRate^floor(Epoch / EpochDrop)
实现需要使用 Keras 中的 LearningRateScheduler 模块:
from keras.callbacks import LearningRateScheduler # learning rate schedule def step_decay(epoch): initial_lrate = 0.1 drop = 0.5 epochs_drop = 10.0 lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop)) return lrate lrate = LearningRateScheduler(step_decay) # Compile model sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False) model.compile(loss=..., optimizer=sgd, metrics=['accuracy']) # Fit the model model.fit(X, Y, ..., callbacks=[lrate])
补充知识:keras中的BGD和SGD
关于BGD和SGD
首先BGD为批梯度下降,即所有样本计算完毕后才进行梯度更新;而SGD为随机梯度下降,随机计算一次样本就进行梯度下降,所以速度快很多但容易陷入局部最优值。
折中的办法是采用小批的梯度下降,即把数据分成若干个批次,一批来进行一次梯度下降,减少随机性,计算量也不是很大。 mini-batch
keras中的batch_size就是小批梯度下降。
以上这篇Keras SGD 随机梯度下降优化器参数设置方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
浅谈keras通过model.fit_generator训练模型(节省内存)
前言 前段时间在训练模型的时候,发现当训练集的数量过大,并且输入的图片维度过大时,很容易就超内存了,举个简单例子,如果我们有20000个样本,输入图片的维度是224x224x3,用float32存储,那么如果我们一次性将全部数据载入内存的话,总共就需要20000x224x224x3x32bit/8=11.2GB 这么大的内存,所以如果一次性要加载全部数据集的话是需要很大内存的. 如果我们直接用keras的fit函数来训练模型的话,是需要传入全部训练数据,但是好在提供了fit_generator,
-
在keras中model.fit_generator()和model.fit()的区别说明
首先Keras中的fit()函数传入的x_train和y_train是被完整的加载进内存的,当然用起来很方便,但是如果我们数据量很大,那么是不可能将所有数据载入内存的,必将导致内存泄漏,这时候我们可以用fit_generator函数来进行训练. keras中文文档 fit fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=N
-
使用Keras中的ImageDataGenerator进行批次读图方式
ImageDataGenerator位于keras.preprocessing.image模块当中,可用于做数据增强,或者仅仅用于一个批次一个批次的读进图片数据.一开始以为ImageDataGenerator是用来做数据增强的,但我的目的只是想一个batch一个batch的读进图片而已,所以一开始没用它,后来发现它是有这个功能的,而且使用起来很方便. ImageDataGenerator类包含了如下参数:(keras中文教程) ImageDataGenerator(featurewise_cen
-
浅谈keras2 predict和fit_generator的坑
1.使用predict时,必须设置batch_size,否则效率奇低. 查看keras文档中,predict函数原型: predict(self, x, batch_size=32, verbose=0) 说明: 只使用batch_size=32,也就是说每次将batch_size=32的数据通过PCI总线传到GPU,然后进行预测.在一些问题中,batch_size=32明显是非常小的.而通过PCI传数据是非常耗时的. 所以,使用的时候会发现预测数据时效率奇低,其原因就是batch_size太小
-
Keras SGD 随机梯度下降优化器参数设置方式
SGD 随机梯度下降 Keras 中包含了各式优化器供我们使用,但通常我会倾向于使用 SGD 验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器. Keras 中文文档中对 SGD 的描述如下: keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False) 随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量 参数: lr:大或等于0的浮点数,学习率 momen
-
如何在keras中添加自己的优化器(如adam等)
本文主要讨论windows下基于tensorflow的keras 1.找到tensorflow的根目录 如果安装时使用anaconda且使用默认安装路径,则在 C:\ProgramData\Anaconda3\envs\tensorflow-gpu\Lib\site-packages\tensorflow处可以找到(此处为GPU版本),cpu版本可在C:\ProgramData\Anaconda3\Lib\site-packages\tensorflow处找到.若并非使用默认安装路径,可参照根目
-

人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
PyTorch加载数据集梯度下降优化
目录 一.实现过程 1.准备数据 2.设计模型 3.构造损失函数和优化器 4.训练过程 5.结果展示 二.参考文献 一.实现过程 1.准备数据 与PyTorch实现多维度特征输入的逻辑回归的方法不同的是:本文使用DataLoader方法,并继承DataSet抽象类,可实现对数据集进行mini_batch梯度下降优化. 代码如下: import torch import numpy as np from torch.utils.data import Dataset,DataLoader clas
-
基于随机梯度下降的矩阵分解推荐算法(python)
SVD是矩阵分解常用的方法,其原理为:矩阵M可以写成矩阵A.B与C相乘得到,而B可以与A或者C合并,就变成了两个元素M1与M2的矩阵相乘可以得到M. 矩阵分解推荐的思想就是基于此,将每个user和item的内在feature构成的矩阵分别表示为M1与M2,则内在feature的乘积得到M:因此我们可以利用已有数据(user对item的打分)通过随机梯度下降的方法计算出现有user和item最可能的feature对应到的M1与M2(相当于得到每个user和每个item的内在属性),这样就可以得到通
-
pytorch 实现在一个优化器中设置多个网络参数的例子
我就废话不多说了,直接上代码吧! 其实也不难,使用tertools.chain将参数链接起来即可 import itertools ... self.optimizer = optim.Adam(itertools.chain(self.encoder.parameters(), self.decoder.parameters()), lr=self.opt.lr, betas=(self.opt.beta1, 0.999)) ... 以上这篇pytorch 实现在一个优化器中设置多个网络参数的
-
在pytorch中动态调整优化器的学习率方式
在深度学习中,经常需要动态调整学习率,以达到更好地训练效果,本文纪录在pytorch中的实现方法,其优化器实例为SGD优化器,其他如Adam优化器同样适用. 一般来说,在以SGD优化器作为基本优化器,然后根据epoch实现学习率指数下降,代码如下: step = [10,20,30,40] base_lr = 1e-4 sgd_opt = torch.optim.SGD(model.parameters(), lr=base_lr, nesterov=True, momentum=0.9) de
-
python实现随机梯度下降(SGD)
使用神经网络进行样本训练,要实现随机梯度下降算法.这里我根据麦子学院彭亮老师的讲解,总结如下,(神经网络的结构在另一篇博客中已经定义): def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): if test_data: n_test = len(test_data)#有多少个测试集 n = len(training_data) for j in xrange(epochs): random.shuf
-
Python语言描述随机梯度下降法
1.梯度下降 1)什么是梯度下降? 因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降. 简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方.但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点.如图所示,黑线标注的路线所指的方向并不是真正的地方. 既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走? 先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因. 如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点.
-
python实现梯度下降求解逻辑回归
本文实例为大家分享了python实现梯度下降求解逻辑回归的具体代码,供大家参考,具体内容如下 对比线性回归理解逻辑回归,主要包含回归函数,似然函数,梯度下降求解及代码实现 线性回归 1.线性回归函数 似然函数的定义:给定联合样本值X下关于(未知)参数 的函数 似然函数:什么样的参数跟我们的数据组合后恰好是真实值 2.线性回归似然函数 对数似然: 3.线性回归目标函数 (误差的表达式,我们的目的就是使得真实值与预测值之前的误差最小) (导数为0取得极值,得到函数的参数) 逻辑回归 逻辑回归是在线性