python爬取梨视频生活板块最热视频

完整代码如下:
import requests
from lxml import etree
import random
import os
from multiprocessing.dummy import Pool
if not os.path.exists('./视频'):
os.mkdir('./视频')
urls=[]
url='https://www.pearvideo.com/category_5'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@id="listvideoListUl"]/li')
for li in li_list:
a_url='https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
old=video_url.split('/')[-1].split('-')[0]
new='cont-'+str(code)
true_video_url=video_url.replace(old,new)
dic={'name':name,
'my_url':true_video_url}
urls.append(dic)
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
说明:
当前日期(2021/3/14)版本的梨视频的视频伪url由ajax获取。
部分代码解释:
1:模块
import requests #网路爬虫标准库(代替urllib) from lxml import etree #用于解析页面信息 import random #梨视频的url中有一段需要随机数 import os #主要用于生成文件夹存放视频 from multiprocessing.dummy import Pool #导入线程池对应类
2:获取视频伪url
#参数准备
mrd=random.random()
code=li.xpath('./div/a/@href')[0][-7:]
new_headers={
'Referer': a_url,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50'
}
#获取url
new_url='https://www.pearvideo.com/videoStatus.jsp?contId='+str(code)+'&mrd='+str(mrd)
r=requests.get(url=new_url,headers=new_headers)
video_url=eval(r.text)['videoInfo']['videos']['srcUrl']
3:获取真正url
经本人实验,使用上文获得的url爬取视频下载内容为空。
由于本人也是菜鸟,所以百思不得其解,恰巧看到B站用户”_千户”的留言才得知真伪url的差异:
此处视频地址做了加密即ajax中得到的地址需要加上cont-,并且修改一段数字为id才是真地址
真地址:"https://video.pearvideo.com/mp4/third/20201120/cont-1708144-10305425-222728-hd.mp4"
伪地址:"https://video.pearvideo.com/mp4/third/20201120/1606132035863-10305425-222728-hd.mp4"
#仅需要做几个简单的截取切片操作就可以替换相关内容
old=video_url.split('/')[-1].split('-')[0]
new='cont-'+str(code)
true_video_url=video_url.replace(old,new)
4:存储
#使用线程池对数据视频进行请求
def get_video_data(dic):
print(dic['name']+'开始下载'+'\n')
data_url=dic['my_url']
data=requests.get(url=data_url,headers=headers).content
with open('./视频/'+dic['name'],'wb') as f:
f.write(data)
print(dic['name']+'下载成功')
pool=Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()
5:结果
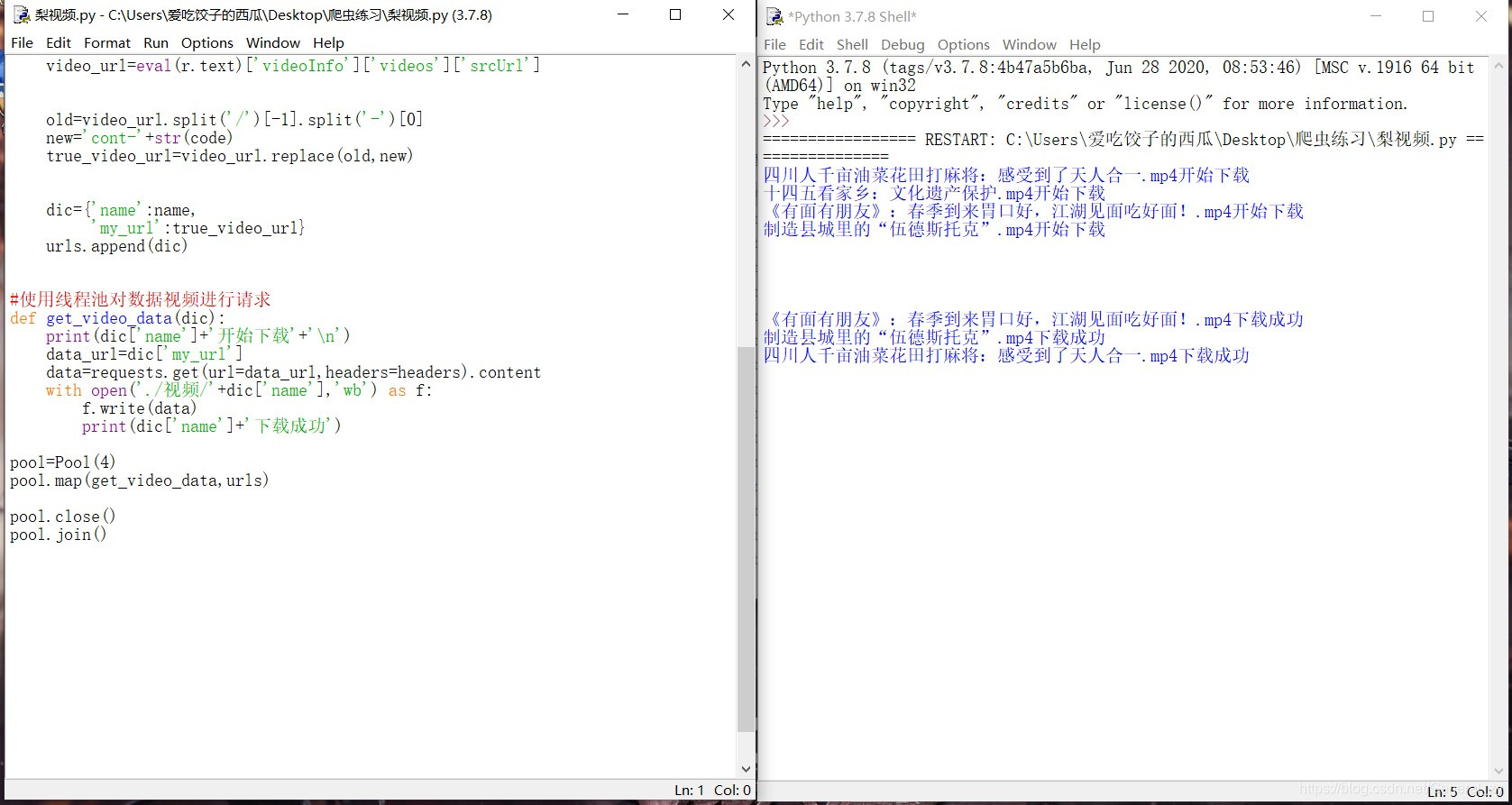
到此这篇关于python爬取梨视频生活板块最热视频的文章就介绍到这了,更多相关python爬取梨视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-

Python爬取梨视频的示例
爬取流程(美食区最热标签下的三个视频) 在首页获取视频的编号和名字 拼接成正确的url 保存视频 思路 1.从网页中获取视频的url 发现视频的url在id为"JprismPlayer"的div标签下的video标签src属性中,xpath解析网页 video_url = tree.xpath("//div[@id='JprismPlayer']/video/@src") 但得到的返回值为空,也就是说这个video标签在原网页中并不存在,很可能是动态加载出来的 2.
-
基于python爬取梨视频实现过程解析
目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8.其实你要哪一页都行,你喜欢就行.嘿嘿- 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0 这个就是我们要找的目标网址啦,后面的0就代表页数,让
-
python爬取梨视频生活板块最热视频
完整代码如下: import requests from lxml import etree import random import os from multiprocessing.dummy import Pool if not os.path.exists('./视频'): os.mkdir('./视频') urls=[] url='https://www.pearvideo.com/category_5' headers={'user-agent':'Mozilla/5.0 (Windo
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
使用python爬取抖音视频列表信息
如果看到特别感兴趣的抖音vlogger的视频,想全部dump下来,如何操作呢?下面介绍介绍如何使用python导出特定用户所有视频信息 抓包分析 Chrome Deveploer Tools Chrome 浏览器开发者工具 在抖音APP端,复制vlogger主页地址, 比如: http://v.douyin.com/kGcU4y/ , 在PC端用chrome浏览器打卡,并模拟手机,这里选择iPhone, 然后把复制的主页地址,放到浏览器进行访问,页面跳转到 https://www.iesdouy
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)
-
Python爬取腾讯视频评论的思路详解
一.前提条件 安装了Fiddler了(用于抓包分析) 谷歌或火狐浏览器 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器 有Python的编译环境,一般选择Python3.0及以上 声明:本次爬取腾讯视频里 <最美公里>纪录片的评论.本次爬取使用的浏览器是谷歌浏览器 二.分析思路 1.分析评论页面 根据上图,我们可以知道:评论使用了Ajax异步刷新技术.这样就不能使用以前分析当前页面找出规律的手段了.因为展示的页面只有部分评论,还有大量的评论没有被刷新出
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
使用python爬取抖音app视频的实例代码
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并