Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路:
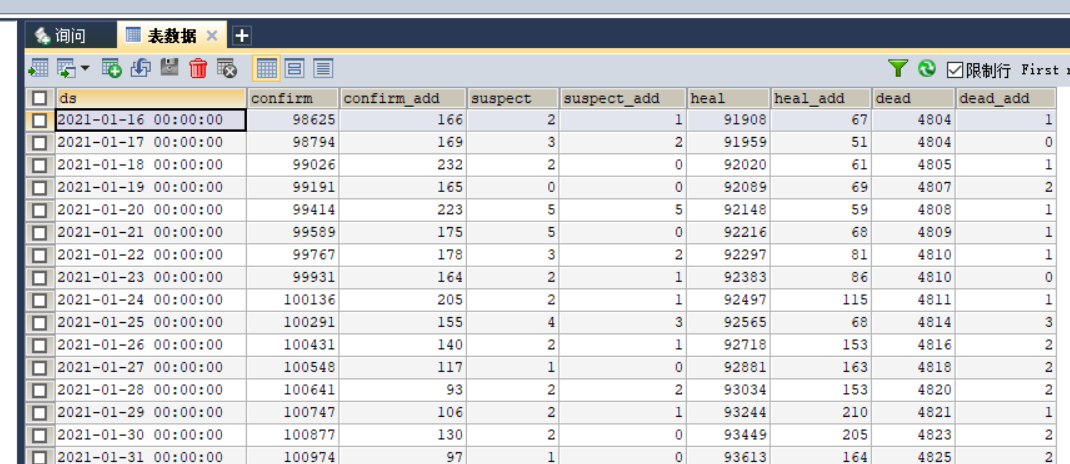
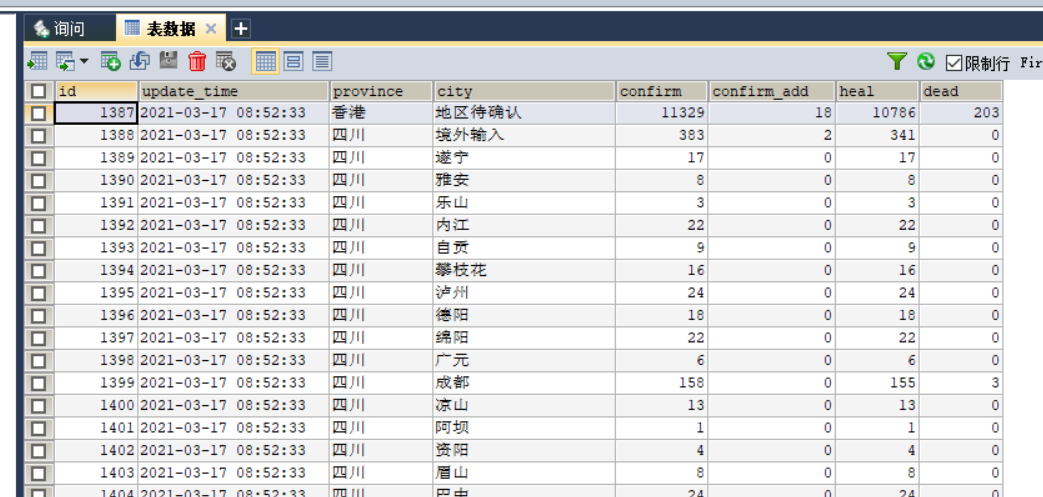
在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表。
①此方法用于爬取每日详细疫情数据
import requests
import json
import time
def get_details():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery34102848205531413024_1584924641755&_=1584924641756'
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
}
res = requests.get(url,headers=headers)
#输出全部信息
# print(res.text)
response_data = json.loads(res.text.replace('jQuery34102848205531413024_1584924641755(','')[:-1])
#输出这个字典的键值 dict_keys(['ret', 'data'])ret是响应值,0代表请求成功,data里是我们需要的数据
# print(response_data.keys())
"""上面已经转化过一次字典,然后获取里面的data,因为data是字符串,所以需要再次转化字典
print(json.loads(reponse_data['data']).keys())
结果:
dict_keys(['lastUpdateTime', 'chinaTotal', 'chinaAdd', 'isShowAdd', 'showAddSwitch',
'areaTree', 'chinaDayList', 'chinaDayAddList', 'dailyNewAddHistory', 'dailyHistory',
'wuhanDayList', 'articleList'])
lastUpdateTime是最新更新时间,chinaTotal是全国疫情总数,chinaAdd是全国新增数据,
isShowAdd代表是否展示新增数据,showAddSwitch是显示哪些数据,areaTree中有全国疫情数据
"""
areaTree_data = json.loads(response_data['data'])['areaTree']
temp=json.loads(response_data['data'])
# print(temp.keys())
# print(areaTree_data[0].keys())
"""
获取上一级字典里的areaTree
然后查看里面中国键值
print(areaTree_data[0].keys())
dict_keys(['name', 'today', 'total', 'children'])
name代表国家名称,today代表今日数据,total代表总数,children里有全国各地数据,我们需要获取全国各地数据,查看children数据
print(areaTree_data[0]['children'])
这里面是
name是地区名称,today是今日数据,total是总数,children是市级数据,
我们通过这个接口可以获取每个地区的总数据。我们遍历这个列表,取出name,这个是省级的数据,还需要获取市级数据,
需要取出name,children(市级数据)下的name、total(历史总数)下的confirm、heal、dead,today(今日数据)下的confirm(增加数),
这些就是我们需要的数据
"""
# print(areaTree_data[0]['children'])
# for province_data in areaTree_data[0]['children']:
# print(province_data)
ds= temp['lastUpdateTime']
details=[]
for pro_infos in areaTree_data[0]['children']:
province_name = pro_infos['name'] # 省名
for city_infos in pro_infos['children']:
city_name = city_infos['name'] # 市名
confirm = city_infos['total']['confirm']#历史总数
confirm_add = city_infos['today']['confirm']#今日增加数
heal = city_infos['total']['heal']#治愈
dead = city_infos['total']['dead']#死亡
# print(ds,province_name,city_name,confirm,confirm_add,heal,dead)
details.append([ds,province_name,city_name,confirm,confirm_add,heal,dead])
return details
单独测试方法:
# d=get_details() # print(d)
②此方法用于爬取历史详细数据
import requests
import json
import time
def get_history():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other&callback=jQuery341026745307075030955_1584946267054&_=1584946267055'
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
}
res = requests.get(url,headers=headers)
# print(res.text)
response_data = json.loads(res.text.replace('jQuery341026745307075030955_1584946267054(','')[:-1])
# print(response_data)
data = json.loads(response_data['data'])
# print(data.keys())
chinaDayList = data['chinaDayList']#历史记录
chinaDayAddList = data['chinaDayAddList']#历史新增记录
history = {}
for i in chinaDayList:
ds = '2021.' + i['date']#时间
tup = time.strptime(ds,'%Y.%m.%d')
ds = time.strftime('%Y-%m-%d',tup)#改变时间格式,插入数据库
confirm = i['confirm']
suspect = i['suspect']
heal = i['heal']
dead = i['dead']
history[ds] = {'confirm':confirm,'suspect':suspect,'heal':heal,'dead':dead}
for i in chinaDayAddList:
ds = '2021.' + i['date']#时间
tup = time.strptime(ds,'%Y.%m.%d')
ds = time.strftime('%Y-%m-%d',tup)#改变时间格式,插入数据库
confirm_add = i['confirm']
suspect_add = i['suspect']
heal_add = i['heal']
dead_add = i['dead']
history[ds].update({'confirm_add':confirm_add,'suspect_add':suspect_add,'heal_add':heal_add,'dead_add':dead_add})
return history
单独测试此方法:
# h=get_history() # print(h)
③此方法用于数据库的连接与关闭:
import time
import pymysql
import traceback
def get_conn():
"""
:return: 连接,游标
"""
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="000429",
db="mydb",
charset="utf8")
# 创建游标
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
④此方法用于更新并插入每日详细数据到数据库表:
def update_details():
"""
更新 details 表
:return:
"""
cursor = None
conn = None
try:
li = get_details()
conn, cursor = get_conn()
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = 'select %s=(select update_time from details order by id desc limit 1)' #对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新最新数据")
for item in li:
cursor.execute(sql, item)
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}更新最新数据完毕")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
单独测试能否插入数据到details表:
update_details()

⑤此方法用于插入历史数据到history表
def insert_history():
"""
插入历史数据
:return:
"""
cursor = None
conn = None
try:
dic = get_history()
print(f"{time.asctime()}开始插入历史数据")
conn, cursor = get_conn()
sql = "insert into history values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
for k, v in dic.items():
# item 格式 {'2021-01-13': {'confirm': 41, 'suspect': 0, 'heal': 0, 'dead': 1}
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
单独测试能否插入数据到history表:
# insert_history()
⑥此方法用于根据时间来更新历史数据表的内容:
def update_history():
"""
更新历史数据
:return:
"""
cursor = None
conn = None
try:
dic = get_history()
print(f"{time.asctime()}开始更新历史数据")
conn, cursor = get_conn()
sql = "insert into history values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k, v in dic.items():
# item 格式 {'2020-01-13': {'confirm': 41, 'suspect': 0, 'heal': 0, 'dead': 1}
if not cursor.execute(sql_query, k):
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
单独测试更新历史数据表的方法:
# update_history()
最后是两个数据表的详细建立代码(也可以使用mysql可视化工具直接建立):
create table history( ds datetime not null comment '日期', confirm int(11) default null comment '累计确诊', confirm_add int(11) default null comment '当日新增确诊', suspect int(11) default null comment '剩余疑似', suspect_add int(11) default null comment '当日新增疑似', heal int(11) default null comment '累计治愈', heal_add int(11) default null comment '当日新增治愈', dead int(11) default null comment '累计死亡', dead_add int(11) default null comment '当日新增死亡', primary key(ds) using btree )engine=InnoDB DEFAULT charset=utf8mb4; create table details( id int(11) not null auto_increment, update_time datetime default null comment '数据最后更新时间', province varchar(50) default null comment '省', city varchar(50) default null comment '市', confirm int(11) default null comment '累计确诊', confirm_add int(11) default null comment '新增确诊', heal int(11) default null comment '累计治愈', dead int(11) default null comment '累计死亡', primary key(id) )engine=InnoDB default charset=utf8mb4;
Tomorrowthe birds will singing.
到此这篇关于Python爬取腾讯疫情实时数据并存储到mysql数据库的文章就介绍到这了,更多相关Python爬取数据存储到mysql数据库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python3爬虫学习之MySQL数据库存储爬取的信息详解
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息.分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用. 这里,数据库选择MySQL,采用pymysql 这个第三方库来处理python和mysql数据库的存取,python连接mysql数据库的配置信息 db_
-
python利用xpath爬取网上数据并存储到django模型中
帮朋友制作一个网站,需要一些产品数据信息,因为是代理其他公司产品,直接爬取代理公司产品数据 1.设计数据库 from django.db import models from uuslug import slugify import uuid import os def products_directory_path(instance, filename): ext = filename.split('.')[-1] filename = '{}.{}'.format(uuid.uuid4().
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中
爬取TOP500的音乐信息,包括排名情况.歌曲名.歌曲时间. 网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL: http://www.kugou.com/yy/rank/home/1-8888.html 这里尝试将1改为2,再进行浏览,恰好是第二页的信息,再改为3,恰好是第三页的信息,多次尝试发现不同的数字即为不同的页面.因此只需更改home/后面的数字即可.由于每页显示的为22首歌曲,所以总共需要23个URL. import requests from bs4 import B
-
基于Python爬取股票数据过程详解
基本环境配置 python 3.6 pycharm requests csv time 相关模块pip安装即可 目标网页 分析网页 一切的一切都在图里 找到数据了,直接请求网页,解析数据,保存数据 请求网页 import requests url = 'https://xueqiu.com/service/v5/stock/screener/quote/list' response = requests.get(url=url, params=params, headers=headers, c
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python爬取腾讯视频评论的思路详解
一.前提条件 安装了Fiddler了(用于抓包分析) 谷歌或火狐浏览器 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器 有Python的编译环境,一般选择Python3.0及以上 声明:本次爬取腾讯视频里 <最美公里>纪录片的评论.本次爬取使用的浏览器是谷歌浏览器 二.分析思路 1.分析评论页面 根据上图,我们可以知道:评论使用了Ajax异步刷新技术.这样就不能使用以前分析当前页面找出规律的手段了.因为展示的页面只有部分评论,还有大量的评论没有被刷新出
-
python 爬取腾讯视频评论的实现步骤
一.网址分析 查阅了网上的大部分资料,大概都是通过抓包获取.但是抓包有点麻烦,尝试了F12,也可以获取到评论.以电视剧<在一起>为例子.评论最底端有个查看更多评论猜测过去应该是 Ajax 的异步加载. 网上的大部分都是构建评论的网址,通过 requests 获取,正则表达式进行数据处理.本文也利用该方法进行数据处理,其实利用 scrapy 会更简单. 根据前辈给出的经验,顺利找到了评论所在的链接. 在新标签中打开,该网址的链接. 评论都在"content":"xx
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
python爬取链家二手房的数据
一.查找数据所在位置: 打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据. 二.确定数据存放位置: 某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中: 三.获取html数据: 通过requests请求页面,获取每页的html数据 # 爬取的url,默认爬取的南京的链家房产信息 url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page) #
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
用Python爬取某乎手机APP数据
目录 一.配置抓包工具 二.配置手机代理 三.抓取数据 四.总结 一.配置抓包工具 1.安装软件 本文选择的抓包工具:Fiddler 具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了! 2.配置Fiddler 安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!) 配置Connections 打开Fiddler后,点击Tools->Options 点击Connections 勾选上对应的选项 配置HTTPS 由于目
-
python读取word文档,插入mysql数据库的示例代码
表格内容如下: 1.实现批量导入word文档,取文档标题中的数字作为编号 2.除取上面打钩的内容需要匹配出来入库入库,其他内容全部直接入库mysql # wuyanfeng # -*- coding:utf-8 -*- # 读取docx中的文本代码示例 import docx import pymysql import re import os # 创建数据库链接 conn = pymysql.connect( host='rm-bp1vu5d84dg12c6d59o.mysql.rds.ali