汇编基础程序编写教程示例
目录
- 源程序
- 1.1 构成
- 寄存器与段的关联假设
- 标号
- 定义一个段
- 程序结束标记
- 程序返回
- 程序运行
- 1.2 源程序中的“程序”
- 1.3 段结束、程序结束、程序返回
- 1.4 语法错误和逻辑错误
- 2 程序执行的过程
- 2.1 一个汇编语言程序从写出到最终执行的简要过程:
- 2.2 连接
- 2.3 可执行文件
- 2.4 程序执行过程的跟踪
- 总结
- 3 程序编写
- 3.1 两个基本的问题
- 3.2 数据在哪里
- 立即数(idata)
- 寄存器
- 段地址(SA)和偏移地址(EA)
- 3.3 指令处理的数据有多长
- 3.4 数据处理
- 在代码段中使用数据
- 在代码段中使用栈
- 将数据、代码、栈放入不同的段
- CPU如何知道去执行它们?
- 3.5 模块化实现:call 和 ret 指令
- ret
- retf
- 示例
- 主要应用格式

源程序
1.1 构成
寄存器与段的关联假设
assume:含义为“假设”。
它假设某一段寄存器和程序中的某一个用 segment … ends 定义的段相关联。
通过assume说明这种关联,在需要的情况下 ,编译程序可以将段寄存器和某一个具体的段相联系。
标号
一个标号指代了一个地址。
codesg:放在segment的前面,作为一个段的名称,这个段的名称最终将被编译、连接程序处理为一个段的段地址。
定义一个段
segment和ends的功能是定义一个段,segment说明一个段开始,ends 说明一个段结束。
segment和ends是一对成对使用的伪指令
一个段必须有一个名称来标识,使用格式为:
段名 segment
段名 ends
一个汇编程序是由多个段组成的,这些段被用来存放代码、数据或当作栈空间来使用。
一个有意义的汇编程序中至少要有一个段,这个段用来存放代码。
程序结束标记
End 是一个汇编程序的结束标记,编译器在编译汇编程序的过程中,如果碰到了伪指令 end,就结束对源程序的编译。
如果程序写完了,要在结尾处加上伪指令end 。否则,编译器在编译程序时,无法知道程序在何处结束。
注意:不要搞混了end和ends。
程序返回
一个程序结束后,将CPU的控制权交还给使它得以运行的程序,我们称这个过程为:程序返回。
如何返回
应该在程序的末尾添加返回的程序段。
mov ax,4c00H
int 21H
程序运行
DOS是一个单任务操作系统。
一个程序P2在可执行文件中,则必须有一个正在运行的程序P1,将P2从可执行文件中加载入内存后,将CPU的控制权交给P2,P2才能得以运行。P2开始运行后,P1暂停运行。
而当P2运行完毕后,应该将CPU的控制权交还给使它得以运行的程序P1,此后,P1继续运行。
1.2 源程序中的“程序”
汇编源程序:
伪指令 (编译器处理)
汇编指令(编译为机器码)
程序:源程序中最终由计算机执行、处理的指令或数据。
注意
我们可以将源程序文件中的所有内容称为源程序,将源程序中最终由计算机执行处理的指令或数据 ,成为程序。
程序最先以汇编指令的形式存在源程序中,经编译、连接后转变为机器码,存储在可执行文件中,

1.3 段结束、程序结束、程序返回

1.4 语法错误和逻辑错误
语法错误
程序在编译时被编译器发现的错误
逻辑错误
程序在编译时不能表现出来的、在运行时发生的错误
2 程序执行的过程
2.1 一个汇编语言程序从写出到最终执行的简要过程:

2.2 连接
作用
当源程序很大时,可以将它分为多个源程序文件来编译,每个源程序编译成为目标文件后,再用连接程序将它们连接到一起,生成一个可执行文件;
程序中调用了某个库文件中的子程序,需要将这个库文件和该程序生成的目标文件连接到一起,生成一个可执行文件;
一个源程序编译后,得到了存有机器码的目标文件,目标文件中的有些内容还不能直接用来生成可执行文件,连接程序将这此内容处理为最终的可执行信息。
所以,在只有一个源程序文件,而又不需要调用某个库中的子程序的情况下,也必须用连接程序对目标文件进行处理,生成可执行文件。
注意,对于连接的过程,可执行文件是我们要得到的最终结果。
使用汇编语言编译程序对源程序文件中的源程序进行编译,产生目标文件;再用连接程序对目标文件进行连接,生成可在操作系统中直接运行的可执行文件。
2.3 可执行文件
可执行文件中包含两部分内容:
- 程序(从原程序中的汇编指令翻译过来的机器码)和数据(源程序中定义的数据)
- 相关的描述信息(比如:程序有多大、要占多少内存空间等)
执行可执行文件中的程序
- 在操作系统中,执行可执行文件中的程序。
- 操作系统依照可执行文件中的描述信息,将可执行文件中的机器码和数据加载入内存,并进行相关的初始化(比如:设置CS:IP指向第一条要执行的指令),然后由CPU执行程序。

可执行文件中的程序装入内存并运行的原理
- 在DOS中,可执行文件中的程序P1若要运行,必须有一个正在运行的程序P2 ,将 P1 从可执行文件中加载入内存,将CPU的控制权交给它,P1才能得以运行;
- 当P1运行完毕后,应该将CPU的控制权交还给使它得以运行的程序P2
exe的执行过程
实际过程
(1)我们在提示符“C:\masm”后面输入可执行文件的名字“1”,按Enter键。
(2)1.exe中的程序运行;
(3)运行结束,返回,再次显示提示符“C:\masm”。
操作过程
操作系统是由多个功能模块组成的庞大 、复杂的软件系统。任何通用的操作系统 ,都要提供一个称为shell(外壳)的程序 ,用户(操作人员)使用这个程序来操作计算机系统工作。
DOS中有一个程序command.com ,这个程序在 DOS 中称为命令解释器,也就是DOS系统的shell。
(1)我们在DOS中直接执行 1.exe 时,是正在运行的command将1.exe中的程序加载入内存。
(2)command设置CPU的CS:IP指向程序的第一条指令(即程序的入口),从而使程序得以运行。
(3)程序运行结束后,返回到command中,CPU继续运行command。
2.4 程序执行过程的跟踪
Debug 可以将程序加载入内存,设置CS:IP指向程序的入口,但Debug并不放弃对CPU 的控制,这样,我们就可以使用Debug 的相关命令来单步执行程序 ,查看每条指令指令的执行结果。
我们在 DOS中用 “Debug 1.exe” 运行Debug对1.exe进行跟踪时,程序加载的顺序是:command加载Debug,Debug加载1.exe。
返回的顺序是:从1.exe中的程序返回到Debug,从Debug返回到command。
EXE文件中的程序的加载过程

总结
程序加载后,ds中存放着程序所在内存区的段地址,这个内存区的偏移地址为 0 ,则程序所在的内存区的地址为:ds:0;
这个内存区的前256 个字节中存放的是PSP,dos用来和程序进行通信。
从 256字节处向后的空间存放的是程序。
所以,我们从ds中可以得到PSP的段地址SA,PSP的偏移地址为 0,则物理地址为SA×16+0。
因为PSP占256(100H)字节,所以程序的物理地址是:
SA×16+0+256= SA×16+16×16=(SA+16)×16+0
可用段地址和偏移地址表示为:SA+10:0。
3 程序编写
3.1 两个基本的问题
计算机是进行数据处理、运算的机器,那么有两个基本的问题就包含在其中:
(1)处理的数据在什么地方?
(2)要处理的数据有多长?这两个问题,在机器指令中必须给以明确或隐含的说明,否则计算机就无法工作。
为了描述上的简洁,在以后的课程中,我们将使用两个描述性的符号 reg来表示一个寄存器,用sreg表示一个段寄存器。
reg的集合包括:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di;
sreg的集合包括:ds、ss、cs、es。
3.2 数据在哪里
机器指令处理的数据所在位置
- 绝大部分机器指令都是进行数据处理的指令,处理大致可分为三类:读取、写入、运算
- 在机器指令这一层来讲,并不关心数据的值是多少,而关心指令执行前一刻,它将要处理的数据所在的位置。
- 指令在执行前,所要处理的数据可以在三个地方:CPU内部、内存、端口
- 指令举例

汇编语言中数据位置的表达
汇编语言中用三个概念来表达数据的位置。
立即数(idata)
对于直接包含在机器指令中的数据(执行前在cpu 的指令缓冲器中),在汇编语言中称为:立即数(idata ) ,在汇编指令中直接给出。例如:
mov ax,1
add bx,2000h
or bx,00010000b
mov al,'a'

寄存器
指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名。例如:
mov ax,bx
mov ds,ax
push bx
mov ds:[0],bx
push ds
mov ss,ax
mov sp,ax
mov ax,bx
对应机器码:89D8
执行结果:(ax) = (bx)
段地址(SA)和偏移地址(EA)
指令要处理的数据在内存中,在汇编指令中可用[X]的格式给出EA,SA在某个段寄存器中。
存放段地址的寄存器可以是默认的。
mov ax,[0]
mov ax,[bx]
mov ax,[bx+8]
mov ax,[bx+si]
mov ax,[bx+si+8]
段地址默认在ds中
存放段地址的寄存器也可以显性的给出。
mov ax,[bp]
mov ax,[bp+8]
mov ax,[bp+si]
mov ax,[bp+si+8]
段地址默认在ss中
显性的给出存放段地址的寄存器

寻址方式
当数据存放在内存中的时候,我们可以用多种方式来给定这个内存单元的偏移地址,这种定位内存单元的方法一般被称为寻址方式。
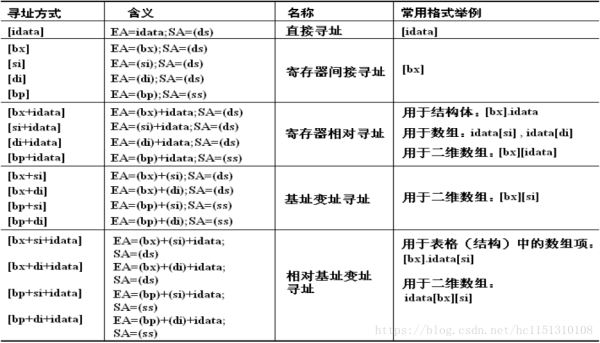
3.3 指令处理的数据有多长
8086CPU的指令,可以处理两种尺寸的数据,byte和word。所以在机器指令中要指明,指令进行的是字操作还是字节操作
对于这个问题,汇编语言中用以下方法处理。
(1)通过寄存器名指明要处理的数据的尺寸。
(2)在没有寄存器名存在的情况下,用操作符X ptr指明内存单元的长度,X在汇编指令中可以为word或byte。
(3)其他方法
下面的指令中,寄存器指明了指令进行的是字节操作:
mov al,1
mov al,bl
mov al,ds:[0]
mov ds:[0],al
inc al
add al,100
下面的指令中,寄存器指明了指令进行的是字操作:
mov ax,1
mov bx,ds:[0]
mov ds,ax
mov ds:[0],ax
inc ax add ax,1000
在没有寄存器参与的内存单元访问指令中,用word ptr或byte ptr显性地指明所要访问的内存单元的长度是很必要的。
否则,CPU无法得知所要访问的单元是字单元,还是字节单元
下面的指令中,用word ptr指明了指令访问的内存单元是一个字单元:
mov word ptr ds:[0],1
inc word ptr [bx]
inc word ptr ds:[0]
add word ptr [bx],2
下面的指令中,用byte ptr指明了指令访问的内存单元是一个字节单元:
mov byte ptr ds:[0],1
inc byte ptr [bx]
inc byte ptr ds:[0]
add byte ptr [bx],2
有些指令默认了访问的是字单元还是字节单元,
比如:push [1000H]就不用指明访问的是字单元还是字节单元
因为push指令只进行字操作
3.4 数据处理
在代码段中使用数据
考虑这样一个问题,编程计算以下8个数据的和,结果存在ax 寄存器中:
0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H。
在前面的课程中,我们都是累加某些内存单元中的数据,并不关心数据本身。
可现在我们要累加的就是已经给定了数值的数据。

程序第一行中的 “dw”的含义是定义字型数据。dw即define word。
在这里,我们使用dw定义了8个字型数据(数据之间以逗号分隔),它们所占的内存空间的大小为16个字节。
程序中的指令就要对这8个数据进行累加,可这8个数据在哪里呢?
由于它们在代码段中,程序在运行的时候CS中存放代码段的段地址,所以我们可以从CS中得到它们的段地址
这8个数据的偏移地址是多少呢?
- 因为用dw定义的数据处于代码段的最开始,所以偏移地址为0,这8 个数据就在代码段的偏移0、2、4、6、8、A、C、E处。
- 程序运行时,它们的地址就是CS:0、CS:2、CS:4、CS:6、CS:8、CS:A、CS:C、CS:E。
程序中,我们用bx存放加2递增的偏移地址,用循环来进行累加。
在循环开始前,设置(bx)=0,cs:bx指向第一个数据所在的字单元。
每次循环中(bx)=(bx)+2,cs:bx指向下一个数据所在的字单元。
如何让这个程序在编译后可以存系统中直接运行呢?我们可以在源程序中指明界序的入口所在

探讨end的作用:
end 除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。
有了这种方法,我们就可以这样来安排程序的框架:

在代码段中使用栈
完成下面的程序,利用栈,将程序中定义的数据逆序存放
assume cs:codesg
codesgsegment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
?
code ends end
程序的思路大致如下:
程序运行时,定义的数据存放在cs:0~cs:15单元中,共8个字单元。依次将这8个字单元中的数据入栈,然后再依次出栈到这 8 个字单元中,从而实现数据的逆序存放。
问题是,我们首先要有一段可当作栈的内存空间。如前所述,这段空间应该由系统来分配。我们可以在程序中通过定义数据来取得一段空间,然后将这段空间当作栈空间来用
mov ax,cs
mov ss,ax
mov sp,32
我们要讲 cs:16 ~ cs:31 的内存空间当作栈来用,初始状态下栈为空,所以 ss:sp要指向栈底,则设置ss:sp指向cs:32。
比如对于:
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
我们可以说,定义了8个字型数据,也可以说,开辟了8个字的内存空间,这段空间中每个字单元中的数据依次是:
0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H。
因为它们最终的效果是一样的
将数据、代码、栈放入不同的段
在前面的内容中,我们在程序中用到了数据和栈,我们将数据、栈和代码都放到了一个段里面。我们在编程的时候要注意何处是数据,何处是栈,何处是代码。这样做显然有两个问题:
(1)把它们放到一个段中使程序显得混乱;
(2)前面程序中处理的数据很少,用到的栈空间也小,加上没有多长的代码,放到一个段里面没有问题。
但如果数据、栈和代码需要的空间超过64KB,就不能放在一个段中(一个段的容量不能大于64 KB,是我们在学习中所用的8086模式的限制,并不是所有的处理器都这样)。
所以,我们应该考虑用多个段来存放数据、代码和栈。
我们用和定义代码段一样的方法来定义多个段,然后在这些段里面定义需要的数据,或通过定义数据来取得栈空间。
程序中“data”段中的数据“0abch”的地址就是:data:6。
我们要将它送入bx中,就要用如下的代码:
mov ax,data
mov ds,ax
mov bx,ds:[6]
我们不能用下面的指令:
mov ds,data
mov ax,ds:[6]
其中指令“mov ds,data” 是错误的,因为8086CPU不允许将一个数值直接送入段寄存器中。
程序中对段名的引用,如指令“mov ds,data”中的“data”,将被编译器处理为一个表示段地址的数值。
“代码段”、“数据段”、“栈段”完全是我们的安排
我们在源程序中用伪指令
“assume cs:code,ds:data,ss:stack”将cs、ds和ss分别和code、data、stack段相连。
这样做了之后,CPU是否就会将 cs指向 code,ds 指向 data,ss 指向stack,从而按照我们的意图来处理这些段呢?
当然也不是,要知道 assume 是伪指令,是由编译器执行的,也是仅在源程序中存在的信息,CPU并不知道它们。
若要CPU按照我们的安排行事,就要用机器指令控制它,源程序中的汇编指令是CPU要执行的内容
CPU如何知道去执行它们?
我们在源程序的最后用“end start”说明了程序的入口,这个入口将被写入可执行文件的描述信息,可执行文件中的程序被加载入内存后,CPU的CS:IP被设置指向这个入口,从而开始执行程序中的第一条指令。
标号“start”在“code”段中,这样CPU就将code段中的内容当作指令来执行了。
我们在code段中,使用指令:
mov ax,stack
mov ss,ax
mov sp,16 设置ss指向stack,设置ss:sp指向stack:16, CPU 执行这些指令后,将把stack段当做栈空间来用。 CPU若要访问data段中的数据,则可用 ds 指向 data 段,用其他的寄存器(如:bx)来存放 data段中数据的偏移地址
总之,CPU到底如何处理我们定义的段中的内容,是当作指令执行,当作数据访问,还是当作栈空间,完全是靠程序中具体的汇编指令,和汇编指令对CS:IP、SS:SP、DS等寄存器的设置来决定的。
3.5 模块化实现:call 和 ret 指令
功能:call和ret 指令都是转移指令,它们都修改IP,或同时修改CS和IP。
ret
ret指令用栈中的数据,修改IP的内容,从而实现近转移;
CPU执行ret指令时,进行下面两步操作:
(1)(IP)=((ss)*16+(sp))
(2)(sp)=(sp)+2
retf
retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移;
CPU执行retf指令时,进行下面两步操作:
(1)(IP)=((ss)*16+(sp))
(2)(sp)=(sp)+2
(3)(CS)=((ss)*16+(sp))
(4)(sp)=(sp)+2
可以看出,如果我们用汇编语法来解释ret和retf指令,则:
CPU执行ret指令时,相当于进行:
pop IP
CPU执行retf指令时,相当于进行:
pop IP
pop CS
示例
ret指令
程序中ret指令执行后,(IP)=0,CS:IP指向代码段的第一条指令。
retf指令
程序中retf指令执行后,CS:IP指向代码段的第一条指令。
call 指令
CPU执行call指令,进行两步操作:
(1)将当前的 IP 或 CS和IP 压入栈中
(2)转移
主要应用格式
call 指令不能实现短转移,除此之外,call指令实现转移的方法和 jmp 指令的原理相同
依据位移进行转移的call指令
call 标号(将当前的 IP 压栈后,转到标号处执行指令)
CPU执行此种格式的call指令时,进行如下的操作:
(1) (sp) = (sp) – 2 ((ss)*16+(sp)) = (IP)
(2) (IP) = (IP) + 16位位移
call 标号
16位位移=“标号”处的地址-call指令后的第一个字节的地址;
16位位移的范围为 -32768~32767,用补码表示;
16位位移由编译程序在编译时算出。
从上面的描述中,可以看出,如果我们用汇编语法来解释此种格式的 call指令,则: CPU 执行指令“call 标号”时,相当于进行: push IP jmp near ptr 标号
转移的目的地址在指令中的call指令
前面讲解的call指令,其对应的机器指令中并没有转移的目的地址 ,而是相对于当前IP的转移位移。
指令“call far ptr 标号”实现的是段间转移。
CPU执行“call far ptr 标号”这种格式的call指令时的操作:
(1) (sp) = (sp) – 2 ((ss) ×16+(sp)) = (CS) (sp) = (sp) – 2 ((ss) ×16+(sp)) = (IP)
(2) (CS) = 标号所在的段地址 (IP) = 标号所在的偏移地址
从上面的描述中可以看出,如果我们用汇编语法来解释此种格式的 call 指令,则: CPU 执行指令 “call far ptr 标号” 时,相当于进行: push CS push IP jmp far ptr 标号
转移地址在寄存器中的call指令
指令格式:call 16位寄存器
功能:
(sp) = (sp) – 2
((ss)*16+(sp)) = (IP)
(IP) = (16位寄存器)
汇编语法解释此种格式的 call 指令,CPU执行call 16位reg时,相当于进行: push IP jmp 16位寄存器
转移地址在内存中的call指令
转移地址在内存中的call指令有两种格式:
(1) call word ptr 内存单元地址
汇编语法解释: push IP jmp word ptr 内存单元地址 比如下面的指令: mov sp,10h mov ax,0123h mov ds:[0],ax call word ptr ds:[0] 执行后,(IP)=0123H,(sp)=0EH
(2) call dword ptr 内存单元地址
汇编语法解释: push CS push IP jmp dword ptr 内存单元地址 比如,下面的指令: mov sp,10h mov ax,0123h mov ds:[0],ax mov word ptr ds:[2],0 call dword ptr ds:[0] 执行后,(CS)=0,(IP)=0123H,(sp)=0CH
call 和 ret 的配合使用
我们看一下程序的主要执行过程:

(1)前三条指令执行后,栈的情况如下:

(2)call 指令读入后,(IP) =000EH,CPU指令缓冲器中的代码为 B8 05 00; CPU执行B8 05 00,首先,栈中的情况变为:

然后,(IP)=(IP)+0005=0013H。
(3)CPU从cs:0013H处(即标号s处)开始执行。
(4)ret指令读入后:(IP)=0016H,CPU指令缓冲器中的代码为 C3;CPU执行C3,相当于进行pop IP,执行后,栈中的情况为:

(IP)=000EH;
(5)CPU回到 cs:000EH处(即call指令后面的指令处)继续执行。
我们发现,可以写一个具有一定功能的程序段,我们称其为子程序,在需要的时候,用call指令转去执行
call指令转去执行子程序之前,call指令后面的指令的地址将存储在栈中,所以可以在子程序的后面使用 ret 指令,用栈中的数据设置IP的值,从而转到 call 指令后面的代码处继续执行。
这样,我们可以利用call和ret来实现子程序的机制。
子程序的框架
标号: 指令 ret 具有子程序的源程序的框架:

参数和结果传递的问题
子程序一般都要根据提供的参数处理一定的事务,处理后,将结果(返回值)提供给调用者。
其实,我们讨论参数和返回值传递的问题,实际上就是在探讨,应该如何存储子程序需要的参数和产生的返回值。
我们设计一个子程序,可以根据提供的N,来计算N的3次方。
这里有两个问题:
(1)我们将参数N存储在什么地方?
(2)计算得到的数值,我们存储在什么地方?
很显然,我们可以用寄存器来存储,可以将参数放到 bx 中 ;
因为子程序中要计算 N×N×N ,可以使用多个 mul 指令,为了方便,可将结果放到 dx 和 ax中。
子程序
说明:计算N的3次方
参数: (bx)=N
结果: (dx:ax)=N∧3
cube:mov ax,bx
mul bx ;用ax与bx相乘
mul bx
ret
用寄存器来存储参数和结果是最常使用的方法。对于存放参数的寄存器和存放结果的寄存器,调用者和子程序的读写操作恰恰相反:
调用者将参数送入参数寄存器,从结果寄存器中取到返回值;
子程序从参数寄存器中取到参数,将返回值送入结果寄存器。
以上就是汇编基础程序编写教程示例的详细内容,更多关于汇编语言基础程序编写的资料请关注我们其它相关文章!
相关推荐
-
汇编语言功能字符串大小写转换实现实例详解
目录 问题1:将data段中的第一个字符串转换成大写,第二个字符串转换成小写 问题2:将data段中每个单词的头一个字母改成大写字母 问题3:将data段中每个单词改为大写字母 问题4:将data段中每个单词的前4个字母改为大写字母 问题5:设计一个子程序,将一个全是字母的字符串转化成大写 问题6:设计一个子程序,将一个全是字母,以0结尾的字符串,转化成大写 复杂一点的对结构化数据的版本 问题1:将data段中的第一个字符串转换成大写,第二个字符串转换成小写 分析: 如何转换成大小写 如果利用A
-

汇编基础教程段的定义应用详解
目录 段 种类 代码段 数据段 DS和[address] 栈段 栈 操作方式 8086CPU提供入栈和出栈指令 栈顶超界的问题 push.pop指令 PUSH(入栈) POP(出栈) 栈段定义 思考 访问 段前缀 场景1 场景2 段 将一段内存定义为一个段,用一个段地址指示段,用偏移地址访问段内的单元 种类 代码段 定义 对于8086PC机,在编程时,可以根据需要,将一组内存单元定义为一个段. 可以将长度为 N( N≤64KB )的一组代码,存在一组地址连续.起始地址为 16的倍数的内存单元中,
-
汇编语言功能实现数据复制实例详解
目录 问题1:将内存ffff:0~ffff:b单元中的数据复制到0:200~0:20b单元中 问题2:将"mov ax,4c00h"之前的指令复制到内存0:200处 问题3:将程序中定义的数据逆序存放 问题4:将字符串"welcome to masm"复制到它后面的数据区中 问题1:将内存ffff:0~ffff:b单元中的数据复制到0:200~0:20b单元中 分析 1.0:200~0:20b单元如何表示 0020:0~0020:b可以等同于以上单元,而且单元的偏移
-
汇编语言超浓缩教程
所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样).某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了.为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ--).但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP.WINRAR-依次压迫,嘿嘿!
-
王爽 汇编语言学习笔记(详细)
王爽汇编语言第三版是一款高清完整版的专业编程图书,该书结构设计合理,内容全面涵盖知识点丰富,适合自学者使用,有需要者快来 一.基础知识 1.指令 机器指令:CPU能直接识别并执行的二进制编码 汇编指令:汇编指令是机器指令的助记符,同机器指令一一对应. 指令:指令通常由操作码和地址码(操作数)两部分组成 指令集:每种CPU都有自己的汇编指令集. 汇编语言由3类指令组成. 汇编指令 伪指令:没有对应的机器码,由编译器执行,计算机并不执行 其他符号:如+.-.*./等,由编译器识别,没有对应的机器码.
-
springboot启动类如何剔除扫描某个包
启动类剔除扫描某个包 排除api中不引数据库导致的报错包 @ComponentScan(excludeFilters = { @ComponentScan.Filter(type = FilterType.REGEX,pattern = "com.integration.aop.log.service.*") }) 通过该注解配置,可以实现剔除某个包,让Spring不自动扫描该包下的内容. 适用于依赖api或者其他包时,一些不必要或不支持的对象被扫描到,引发的报错或内存占用等问题.通过
-
汇编基础程序编写教程示例
目录 源程序 1.1 构成 寄存器与段的关联假设 标号 定义一个段 程序结束标记 程序返回 程序运行 1.2 源程序中的"程序" 1.3 段结束.程序结束.程序返回 1.4 语法错误和逻辑错误 2 程序执行的过程 2.1 一个汇编语言程序从写出到最终执行的简要过程: 2.2 连接 2.3 可执行文件 2.4 程序执行过程的跟踪 总结 3 程序编写 3.1 两个基本的问题 3.2 数据在哪里 立即数(idata) 寄存器 段地址(SA)和偏移地址(EA) 3.3 指令处理的数据有多长 3
-
使用 EasyCode生成springboot+mybatis基础程序的实现示例
目录 一.前言 二.正文 2.1 基础前提 2.1.1springboot配置 2.1.1 基础工具类 2.2 模板设置 2.2.1安装idea插件:EasyCode 2.2.2 设置模板 2.3 生成方法 一.前言 此文将分享我个人使用的一个easycode生成方法,生成之后可以直接运行,这也就意味着,生成的代码会更加规范化.规范化就意味着会有更多的约束. 二.正文 2.1 基础前提 2.1.1springboot配置 引入所需jar包pom.xml加入一下依赖 <dependency> &
-
TypeScript基础class类教程示例
目录 class类 示例 构造函数 继承 class 类 类是面向对象语言的程序设计中的概念,是面向对象编程的基础. 类是创建对象的模板,是对现实生活中一类具有共同特征的事物的抽象 类的内部封装了属性和方法,用于操作自身的成员 示例 将每条狗看做一个对象,那他的属性就有 品种.颜色,方法(行为)舔.叫.吃. class Dog { breed: string; color: string; lick(): void { console.log(` 我仍认为我们作为一个舔狗的真正目的是为了拥有一份
-
javascript基础数据类型转换教程示例
目录 数值型转换为字符串类型 字符串类型转换为数值型 转换为布尔型 结语 数值型转换为字符串类型 方式 说明 案例 toString() 转成字符串 var num =1; alert ( num.toString()); String() 强制转换 转成字符串 var num =1; alert ( String ( num )); 加号拼接字符串 和字符串拼接的结果都是字符串 var num =1; alert ( num +"我是字符串"); // 1.将数字型转换为字符串类型 var n
-
python深度学习tensorflow入门基础教程示例
目录 正文 1.编辑器 2.常量 3.变量 4.占位符 5.图(graph) 例子1:hello world 例子2:加法和乘法 例子3: 矩阵乘法 正文 TensorFlow用张量这种数据结构来表示所有的数据. 用一阶张量来表示向量,如:v = [1.2, 2.3, 3.5] ,如二阶张量表示矩阵,如:m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]],可以看成是方括号嵌套的层数. 1.编辑器 编写tensorflow代码,实际上就是编写py文件,最好找一个好用的编辑器
-
Python Flask基础教程示例代码
本文研究的主要是Python Flask基础教程,具体介绍如下. 安装:pip install flask即可 一个简单的Flask from flask import Flask #导入Flask app = Flask(__name__) #创建一个Flask实例 #设置路由,即url @app.route('/') #url对应的函数 def hello_world(): #返回的页面 return 'Hello World!' #这个不是作为模块导入的时候运行,比如这个文件为aa.py,
-
vue实例成员 插值表达式 过滤器基础教程示例详解
目录 一. 什么是Vue 二.为什么学Vue 三.如何使用Vue 下载安装? 插值表达式 四.vue特点 1.虚拟DOM 2.数据的双向绑定 3.单页面应用 4.数据驱动 五.Vue实例 六.实例成员 - 挂载点 | el - 自定义插值表达式括号| delimiters - 数据 | data - 过滤器 | filters - 方法 | methods - js对象(即字典)补充 - 插值表达式转义 | delimters - 计算属性 | computed - 监听属性 | watch 一
-
Leaflet 基础入门教程示例
目录 什么是Webgis? 什么是Leaflet? 在Vue中安装Leaflet,与其他依赖 在App.vue中使用 初始化地图 chinaProvider地图瓦片 addControls使用工具集 attribution创建自定义版权 Marker创建点 创建线 Polygon创建三角形 Popup弹窗&Tooltip提示 Geojson区域描边 总结 什么是Webgis? webGis又称之为网络地理信息系统,GIS的全名是Geographic Information System,它是在计
-
iOS汇编入门教程之ARM64汇编基础教程
前言 对于应用层开发人员而言,仅仅掌握Objective-C和系统框架即可较好的完成开发,但在涉及到应用加固.逆向分析等内容时仅有应用层开发技能就会显得非常的无力,因此掌握汇编对于突破iOS开发水平的瓶颈十分有效. 一个例子 以反调试为例,我们知道,通过调用ptrace函数可以阻止调试器依附. ptrace(31, 0, 0, 0) 这种方式能够被函数hook轻易破解,例如使用facebook的fishhook.为了防止函数被hook,我们可以将函数调用转为通过汇编发起系统调用,即使用下面的代码