python爬虫模拟登录之图片验证码实现详解
我们在用爬虫对门户网站进行模拟登录是总会有输入图片验证码的,例如这种
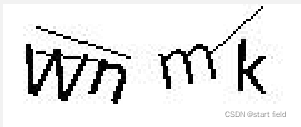
那我们怎么解决这个问题实现全自动的模拟登录呢?只要思想不滑坡,办法总比困难多。我这里使用的是百度智能云里面的文字识别功能,每天好像可以免费使用个几百次,识别效果也还行,对一般人而言是够用了。
接下来说说,怎么使用。
首先,打开百度智能云(https://cloud.baidu.com/)进行登入,再进入人工智能->文字识别里创建应用。

在使用名称和底下应用描述随便写写,然后点立即创建。
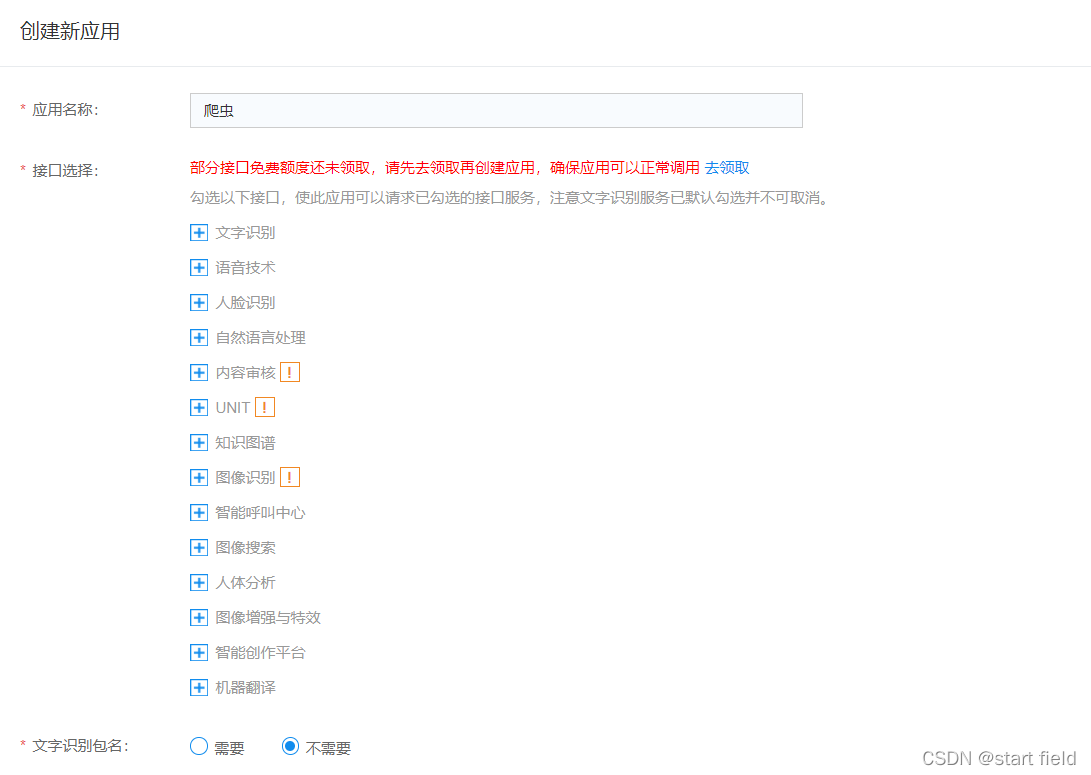
创建完成,就可以拿到 AppID 、API Key 、Secret Key

之后要在pycharm下载baidu-aip,然后导入AipOcr包。
from aip import AipOcr #aip在baidu-aip中
再然后就是初始化百度API
#百度API APP_ID = '你的之前拿到的AppID' API_KEY = '你的之前拿到的API Key' Secret_Key = '你的之前拿到的Secret Key'
我们先要把 图片验证码下载下来进行二值化处理,这样识别的准确率高一些。
这里要下载pillow库,然后导入Image包
from PIL import Image #PIL在pillow库中
#图片处理
# 二值化处理 灰度阈值设为127,高于这个值的点全部填白色
img_old = Image.open('code.jpg')
img_old = img_old.convert('L') # 灰度图 模式“L” 每个像素用8个bit表示,0表示黑,255表示白
threshld = 127 #设置阈值,图片的像素范围(0,255)
table = []
for i in range(256):
if i <threshld:
table.append(0)
else:
table.append(1)
img_old = img_old.point(table,'1') # 对图像像素操作 模式“1” 为二值图像,非黑即白。但是它每个像素用8个bit表示,0表示黑,255表示白
img_old.save('code.jpg')
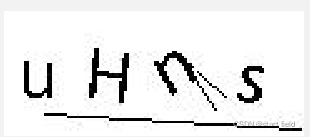
对于那些有干扰线,特别还是明暗交替的图片验证码来说,这样很好的避免了被干扰。
这里的图片中没有太多干扰线且也没有明暗交替所以看起来不明显,只是想让大家看看对比。
处理前 处理后

后面就是调用baidu_aip来读取图片中的内容。baidu_aip.handwriting
#读取处理后的验证码
with open('code.jpg','rb') as fp:
img_new = fp.read()
baidu_aip = AipOcr(APP_ID,API_KEY,Secret_Key)
result = baidu_aip.handwriting(img_new) #使用的是识别手写文字,返回一个字典,其中words_result是一个列表,里面有识别结果也是一个字典
print('验证码是:',result['words_result'][0]['words'])
baidu_aip.handwriting这里面有很多识别文字的方法,我用的是识别手写文字,如果大家使用这个方法感觉效果不好可以选择其他方法。
最后是完整的代码。
# -- coding:UTF-8 --
import requests
from PIL import Image
from aip import AipOcr
if __name__ == "__main__":
#百度API
APP_ID = '你的之前拿到的AppID'
API_KEY = '你的之前拿到的API Key'
Secret_Key = '你的之前拿到的Secret Key'
headers = {
"user-agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 97.0.4692.71Safari / 537.36Edg / 97.0.1072.55"
}
url = 'http://www.hyocr.com/captcha.php'
#下载验证码图片
session = requests.session()
img_data = session.get(url=url,headers=headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
#图片处理
# 二值化处理 灰度阈值设为127,高于这个值的点全部填白色
img_old = Image.open('code.jpg')
img_old = img_old.convert('L') # 灰度图 模式“L” 每个像素用8个bit表示,0表示黑,255表示白
threshld = 127 #设置阈值,图片的像素范围(0,255)
table = []
for i in range(256):
if i <threshld:
table.append(0)
else:
table.append(1)
img_old = img_old.point(table,'1') # 对图像像素操作 模式“1” 为二值图像,非黑即白。但是它每个像素用8个bit表示,0表示黑,255表示白
img_old.save('code.jpg')
#读取处理后的验证码
with open('code.jpg','rb') as fp:
img_new = fp.read()
baidu_aip = AipOcr(APP_ID,API_KEY,Secret_Key)
result = baidu_aip.handwriting(img_new) #使用的是识别手写文字,返回一个字典,其中words_result是一个列表,里面有识别结果也是一个字典
print('验证码是:',result['words_result'][0]['words'])

这只是百度智能云里面的一个小功能,还有很多其他的功能,大家感兴趣可以去看看百度智能云里面的官方文档 ,还有视频教程。
总结
到此这篇关于python爬虫模拟登录之图片验证码实现的文章就介绍到这了,更多相关python爬虫图片验证码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
python网络爬虫实现发送短信验证码的方法
前言:今天要总结的是如何用程序来实现短信发送功能.但是呢,可能需要我们调用一些api接口,我会详细介绍.都是自己学到的,害怕忘记,所以要总结一下,让写博客成为一种坚持的信仰.废话不多说,我们开始吧! 网络爬虫实现发送短信验证码 在实现我们目标的功能之前,我们要有自己的思路,否则你没有方向,又如何实现自己的代码功能呢? 我们要发送短信,那么我们其实是需要分析的.我们可以去分析一个可以发送短信的网站页面. 我们来到这里如下: 可以看到这是一个注册界面,我们在注册时会被要求需要填写手机号码的·,其实还
-
python爬虫之自动登录与验证码识别
在用爬虫爬取网站数据时,有些站点的一些关键数据的获取需要使用账号登录,这里可以使用requests发送登录请求,并用Session对象来自动处理相关Cookie. 另外在登录时,有些网站有时会要求输入验证码,比较简单的验证码可以直接用pytesser来识别,复杂的验证码可以依据相应的特征自己采集数据训练分类器. 以CSDN网站的登录为例,这里用Python的requests库与pytesser库写了一个登录函数.如果需要输入验证码,函数会首先下载验证码到本地,然后用pytesser识别验证码后登
-
python爬虫如何解决图片验证码
之前刚开始做爬虫的时候遇到过登录验证码问题,看过很多帖子都没有解决我的问题,发现大多数帖子都是治标不治本,于是想分享一下自己的解决方案.本次采用的网站是古诗文网,使用百度API,因为百度API免费!免费!免费!适合自己学习的时候使用.如果还没有使用过百度API识别验证码的朋友可以看一下我的这个帖子. 以下案例采用的时古诗文网:登录古诗文网, 1.selenium处理图片验证码 先定位到验证码图片,在获取验证码图片在页面中的位置,使用save_screenshot截取页面,再根据图片的位置去截取验
-
python爬虫解决验证码的思路及示例
如果直接从生成验证码的页面把验证码下载到本地后识别,再构造表单数据发送的话,会有一个验证码同步的问题,即请求了两次验证码,而识别出来的验证码并不是实际需要发送的验证码.有如下几种方法解决. 法1: 用session: mysession = requests.Session() login_url = 'http://xxx.com' checkcode_url='http://yyy.com' html = mysession.get(login_url,timeout=60*4) #....
-
Python3爬虫中识别图形验证码的实例讲解
本节我们首先来尝试识别最简单的一种验证码,图形验证码,这种验证码出现的最早,现在也很常见,一般是四位字母或者数字组成的,例如中国知网的注册页面就有类似的验证码,链接为:http://my.cnki.net/elibregister/commonRegister.aspx,页面: 表单的最后一项就是图形验证码,我们必须完全输入正确图中的字符才可以完成注册. 1.本节目标 本节我们就以知网的验证码为例,讲解一下利用 OCR 技术识别此种图形验证码的方法. 2. 准备工作 识别图形验证码需要的库有 T
-
Python爬虫实现验证码登录代码实例
很多网站为了避免被恶意访问,需要设置验证码登录,避免非人类的访问,Python爬虫实现验证码登录的原理则是先到登录页面将生成的验证码保存下来,然后人为输入后,包装后再POST给服务器,实现验证,这里还涉及到了Cookie,其实Cookie保存在本地主机上,避免用户重复输入用户名和密码,在连接服务器的时候将访问连接和Cookie组装起来POST给服务器. 这里涉及到了两次向服务器POST,一次是Cookie,这里还自行设计想要Cookie的内容,由于是要登录,Cookie中存放的则是用户名和密码.
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python爬虫模拟登录之图片验证码实现详解
我们在用爬虫对门户网站进行模拟登录是总会有输入图片验证码的,例如这种 那我们怎么解决这个问题实现全自动的模拟登录呢?只要思想不滑坡,办法总比困难多.我这里使用的是百度智能云里面的文字识别功能,每天好像可以免费使用个几百次,识别效果也还行,对一般人而言是够用了. 接下来说说,怎么使用. 首先,打开百度智能云(https://cloud.baidu.com/)进行登入,再进入人工智能->文字识别里创建应用. 在使用名称和底下应用描述随便写写,然后点立即创建. 创建完成,就可以拿到 AppID .AP
-
python自动化实现登录获取图片验证码功能
主要记录一下:图片验证码 1.获取登录界面的图片 2.获取验证码位置 3.在登录页面截取验证码保存 4.调用百度api识别(目前准确率较高的识别图片api) 本次登录的系统页面,可以看到图片验证码的位置 from selenium import webdriver import time from PIL import Image base_url = '***********' browser = webdriver.Chrome() browser.maximize_window() bro
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
python产生模拟数据faker库的使用详解
简介 使用faker可以获取很多模拟数据,如:姓名.电话.地址.银行.汽车.条形码.公司.信用卡.email.user_agen等等 学会使用这个库,再也不用为制造假数据发愁了...... 同时,使用起来非常简单,只需要安装,导入库,并创建实例,即可使用,如下: 主要的方法分类 如上面例子,每次调用 fake 实例的 name()方法时,都会产生不同随机姓名.fake 实例还有很多方法可用,这些方法分为以下几类: address 地址 person 人物类:性别.姓名等 barcode 条码类
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
python爬虫使用requests发送post请求示例详解
简介 HTTP协议规定post提交的数据必须放在消息主体中,但是协议并没有规定必须使用什么编码方式.服务端通过是根据请求头中的Content-Type字段来获知请求中的消息主体是用何种方式进行编码,再对消息主体进行解析.具体的编码方式包括: application/x-www-form-urlencoded 最常见post提交数据的方式,以form表单形式提交数据. application/json 以json串提交数据. multipart/form-data 一般使用来上传文件. 一. 以f
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
python爬虫之异常捕获及标签过滤详解
增加异常捕获,更容易现问题的解决方向 import ssl import urllib.request from bs4 import BeautifulSoup from urllib.error import HTTPError, URLError def get_data(url): headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10: