Java实现最小生成树MST的两种解法
目录
- 一、prim算法
- 二、kruskal算法
一、prim算法
时间复杂度较之kruskal较高
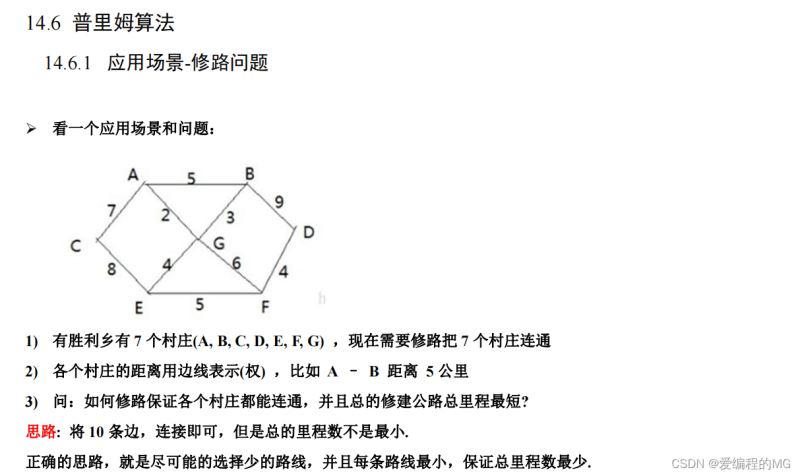

通俗的解释就是:
(1)从哪个点开始生成最小生成树都一样,最后的权值都是相同的
(2)从哪个点开始,先标记这个点是访问过的,用visited数组表示所有节点的访问情况
(3)访问节点开始都每个没访问结点的距离选取形成的边的权值最小值
综合以上三点就是我们prim算法写代码实现的重要思路
代码实现:
package Prim;
import java.util.Arrays;
public class PrimAlgorithm {
public static void main(String[] args) {
//测试看看图是否创建ok
char[] data = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int verxs = data.length;
//邻接矩阵的关系使用二维数组表示,10000这个大数,表示两个点不联通
int[][] weight = new int[][]{
{10000, 5, 7, 10000, 10000, 10000, 2},
{5, 10000, 10000, 9, 10000, 10000, 3},
{7, 10000, 10000, 10000, 8, 10000, 10000},
{10000, 9, 10000, 10000, 10000, 4, 10000},
{10000, 10000, 8, 10000, 10000, 5, 4},
{10000, 10000, 10000, 4, 5, 10000, 6},
{2, 3, 10000, 10000, 4, 6, 10000},};
MGraph mGraph = new MGraph(verxs);
MinTree minTree = new MinTree();
minTree.createGraph(mGraph, verxs, data, weight);
minTree.showGraph(mGraph);
minTree.Prim(mGraph, 0);
}
}
class MinTree {
/**
* 创造图
* @param graph 图对象
* @param verxs 图节点个数
* @param data 图每个顶点的数据值
* @param weight 图的边(邻接矩阵)
*/
public void createGraph(MGraph graph, int verxs, char[] data, int[][] weight) {
int i, j;
for (i = 0; i < verxs; i++) {
graph.data[i] = data[i];
for (j = 0; j < verxs; j++) {
graph.weight[i][j] = weight[i][j];
}
}
}
// 显示图的邻接矩阵
public void showGraph(MGraph graph) {
for (int[] link : graph.weight) {
System.out.println(Arrays.toString(link));
}
}
/**
* 编写prim算法
*
* @param graph 图对象
* @param v 从哪个节点开始生成最小生成树
*/
public void Prim(MGraph graph, int v) {
//定义一个数组,判断节点是不是被访问过了
int[] visited = new int[graph.verxs];
//v这个点已经被访问了,从这个点开始访问
visited[v] = 1;
//找到节点下标
int h1 = -1;
int h2 = -1;
int minWeight = 10000;//定义初始值为最大值,只要出现小的就会替换
int sum = 0;
// 从1开始循环,相当于就是生成graph.verx - 1条边
for (int k = 1; k < graph.verxs; k++) {
for (int i = 0; i < graph.verxs; i++) {//遍历已经访问过的点
if (visited[i] == 1){
for (int j = 0; j < graph.verxs; j++) {//遍历没有访问过的点
//在未访问点中寻找所有与访问过的点相连的边中权值最小值
if (visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {
minWeight = graph.weight[i][j];
h1 = i;
h2 = j;
}
}
}
}
sum += minWeight; // 求最小生成熟的总权值
//此时已经找到一条边是最小了
System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);
//然后标记点
visited[h2] = 1;
//将权值重新变成最大值
minWeight = 10000;
}
System.out.println("最小生成树的权值是:" + sum);
}
}
// 图
class MGraph {
int verxs; // 表示图节点个数
char[] data; // 表示节点数据
int[][] weight; // 表示边
public MGraph(int verxs) {
this.verxs = verxs;
data = new char[verxs];
weight = new int[verxs][verxs];
}
}
二、kruskal算法
时间复杂度低一些,但是代码量会大一些



对克鲁斯卡尔算法的通俗解释:
(1)对每条边的权值进行排序
(2)按照从小到大依次选取边构成最小生成树,但是要注意是否构成回路,树的概念是不能生成回路
(3)此处用的方法比较巧妙使用了getEnd方法来判断两者终点是不是一样,用ends数组保存最小生成树中每个顶点的终点
代码实现:
package Kruskal;
import java.util.Arrays;
public class KruskalCase {
private int edgeNum; //边的个数
private char[] vertexs; //顶点数组
private int[][] matrix; //邻接矩阵
//使用 INF 表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
public static void main(String[] args) {
char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ {0, 12, INF, INF, INF, 16, 14},
/*B*/ {12, 0, 10, INF, INF, 7, INF},
/*C*/ {INF, 10, 0, 3, 5, 6, INF},
/*D*/ {INF, INF, 3, 0, 4, INF, INF},
/*E*/ {INF, INF, 5, 4, 0, 2, 8},
/*F*/ {16, 7, 6, INF, 2, 0, 9},
/*G*/ {14, INF, INF, INF, 8, 9, 0}};
//大家可以在去测试其它的邻接矩阵,结果都可以得到最小生成树.
//创建KruskalCase 对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出构建的
kruskalCase.print();
kruskalCase.kruskal();
}
//构造器
public KruskalCase(char[] vertexs, int[][] matrix) {
//初始化顶点数和边的个数
int vlen = vertexs.length;
//初始化顶点, 复制拷贝的方式
this.vertexs = new char[vlen];
for (int i = 0; i < vertexs.length; i++) {
this.vertexs[i] = vertexs[i];
}
//初始化边, 使用的是复制拷贝的方式
this.matrix = new int[vlen][vlen];
for (int i = 0; i < vlen; i++) {
for (int j = 0; j < vlen; j++) {
this.matrix[i][j] = matrix[i][j];
}
}
//统计边的条数
for (int i = 0; i < vlen; i++) {
for (int j = i + 1; j < vlen; j++) {
if (this.matrix[i][j] != INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index = 0; //表示最后结果数组的索引
int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
//创建结果数组, 保存最后的最小生成树
EData[] rets = new EData[edgeNum];
//获取图中 所有的边的集合 , 一共有12边
EData[] edges = getEdges();
System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共" + edges.length); //12
//按照边的权值大小进行排序(从小到大)
sortEdges(edges);
//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入
for (int i = 0; i < edgeNum; i++) {
//获取到第i条边的第一个顶点(起点)
int p1 = getPosition(edges[i].start); //p1=4
//获取到第i条边的第2个顶点
int p2 = getPosition(edges[i].end); //p2 = 5
//获取p1这个顶点在已有最小生成树中的终点
int m = getEnd(ends, p1); //m = 4
//获取p2这个顶点在已有最小生成树中的终点
int n = getEnd(ends, p2); // n = 5
//是否构成回路
if (m != n) { //没有构成回路
ends[m] = n; // 设置m 在"已有最小生成树"中的终点 <E,F> [0,0,0,0,5,0,0,0,0,0,0,0]
rets[index++] = edges[i]; //有一条边加入到rets数组
}
}
//<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
//统计并打印 "最小生成树", 输出 rets
System.out.println("最小生成树为");
for (int i = 0; i < index; i++) {
System.out.println(rets[i]);
}
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为: \n");
for (int i = 0; i < vertexs.length; i++) {
for (int j = 0; j < vertexs.length; j++) {
System.out.printf("%12d", matrix[i][j]);
}
System.out.println();//换行
}
}
/**
* 功能:对边进行排序处理, 冒泡排序
*
* @param edges 边的集合
*/
private void sortEdges(EData[] edges) {
for (int i = 0; i < edges.length - 1; i++) {
for (int j = 0; j < edges.length - 1 - i; j++) {
if (edges[j].weight > edges[j + 1].weight) {//交换
EData tmp = edges[j];
edges[j] = edges[j + 1];
edges[j + 1] = tmp;
}
}
}
}
/**
* @param ch 顶点的值,比如'A','B'
* @return 返回ch顶点对应的下标,如果找不到,返回-1
*/
private int getPosition(char ch) {
for (int i = 0; i < vertexs.length; i++) {
if (vertexs[i] == ch) {//找到
return i;
}
}
//找不到,返回-1
return -1;
}
/**
* 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组
* 是通过matrix 邻接矩阵来获取
* EData[] 形式 [['A','B', 12], ['B','F',7], .....]
*
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for (int i = 0; i < vertexs.length; i++) {
for (int j = i + 1; j < vertexs.length; j++) {
if (matrix[i][j] != INF) {
edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
*
* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
* @param i : 表示传入的顶点对应的下标
* @return 返回的就是 下标为i的这个顶点对应的终点的下标, 一会回头还有来理解
*/
private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]
while (ends[i] != 0) {
i = ends[i];
}
return i;
}
}
//创建一个类EData ,它的对象实例就表示一条边
class EData {
char start; //边的一个点
char end; //边的另外一个点
int weight; //边的权值
//构造器
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
//重写toString, 便于输出边信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + ">= " + weight + "]";
}
}
到此这篇关于Java实现最小生成树MST的两种解法的文章就介绍到这了,更多相关Java最小生成树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java实现最小生成树算法详解
目录 定义 带权图的实现 Kruskal 算法 二叉堆 并查集 实现算法 Prim 算法 定义 在一幅无向图G=(V,E) 中,(u,v) 为连接顶点u和顶点v的边,w(u,v)为边的权重,若存在边的子集T⊆E且(V,T) 为树,使得 最小,这称 T 为图 G 的最小生成树. 说的通俗点,最小生成树就是带权无向图中权值和最小的树.下图中黑色边所标识的就是一棵最小生成树(图片来自<算法第四版>),对于权值各不相同的连通图来说最小生成树只会有一棵: 带权图的实现 在 <如何在 Java 中实
-
java图论普利姆及克鲁斯卡算法解决最小生成树问题详解
目录 什么是最小生成树? 普利姆算法 算法介绍 应用 --> 修路问题 图解分析 克鲁斯卡尔算法 算法介绍 应用场景 -- 公交站问题 算法图解 算法分析 如何判断是否构成回路 什么是最小生成树? 最小生成树(Minimum Cost Spanning Tree),简称MST. 最小生成树要求图是连通图.连通图指图中任意两个顶点都有路径相通,通常指无向图.理论上如果图是有向.多重边的,也能求最小生成树,只是不太常见. 普利姆算法 算法介绍 应用 --> 修路问题 图解分析
-
Java求最小生成树的两种算法详解
目录 1 最小生成树的概述 2 普里姆算法(Prim) 2.1 原理 2.2 案例分析 3 克鲁斯卡尔算法(Kruskal) 3.1 原理 3.2 案例分析 4 邻接矩阵加权图实现 5 邻接表加权图实现 6 总结 介绍了图的最小生成树的概念,然后介绍了求最小生成树的两种算法:Prim算法和Kruskal算法的原理,最后提供了基于邻接矩阵和邻接链表的图对两种算法的Java实现. 阅读本文需要一定的图的基础,如果对于图不是太明白的可以看看这篇文章:Java数据结构之图的原理与实现. 1 最小生成树的
-
Java实现最小生成树MST的两种解法
目录 一.prim算法 二.kruskal算法 一.prim算法 时间复杂度较之kruskal较高 通俗的解释就是: (1)从哪个点开始生成最小生成树都一样,最后的权值都是相同的 (2)从哪个点开始,先标记这个点是访问过的,用visited数组表示所有节点的访问情况 (3)访问节点开始都每个没访问结点的距离选取形成的边的权值最小值 综合以上三点就是我们prim算法写代码实现的重要思路 代码实现: package Prim; import java.util.Arrays; public clas
-
Java 连接Access数据库的两种方式
java连接MS Access的两种方式: 1.JDBC-ODBC Java连接Access可以使用MS自带的管理工具-->数据源(ODBC)设置建立连接,这样就不需要导入jar.但是,如此一来程序部署的每个机器上都要进行设置不方面.所以现在不会使用啦. 2.JDBC java也可以和连接其他数据库一样连接MS Access,导入数据库相应的jar包,进行连接. 复制代码 代码如下: java Access JDBC jar包:Access_JDBC30.jar 具体连接,参考下面代码: 复制代
-
java 中ArrayList迭代的两种实现方法
java 中ArrayList迭代的两种实现方法 Iterator与for语句的结合来实现,代码很简单,大家参考下. 实现代码: package cn.us; import java.util.ArrayList; import java.util.Iterator; //ArrayList迭代的两种方法 //Iterator与for语句的结合 public class Test1 { public static void main(String[] args) { ArrayList arra
-
java 获取mac地址的两种方法(推荐)
我在网上找了一下获取mac地址的方法,找了两种比较不太一样的方法. 第一种 public static void main(String[] args) throws Exception { InetAddress ia = InetAddress.getLocalHost(); System.out.println(getMACAddress(ia)); } private static String getMACAddress(InetAddress ia) throws Exception
-
Java之递归求和的两种简单方法(推荐)
方法一: package com.smbea.demo; public class Student { private int sum = 0; /** * 递归求和 * @param num */ public void sum(int num) { this.sum += num--; if(0 < num){ sum(num); } else { System.out.println("sum = " + sum); } } } 方法二: package com.smbea
-
java实现遍历树形菜单两种实现代码分享
文本主要向大家分享了java实现遍历树形菜单的实例代码,具体如下. OpenSessionView实现: package org.web; import java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.se
-
java检查服务器的连通两种方法代码分享
首先要了解一下ping的内容. 概述 PING (Packet Internet Groper),因特网包探索器,用于测试网络连接量的程序.Ping发送一个ICMP(Internet Control Messages Protocol)即因特网信报控制协议:回声请求消息给目的地并报告是否收到所希望的ICMPecho (ICMP回声应答).它是用来检查网络是否通畅或者网络连接速度的命令.作为一个生活在网络上的管理员或者黑客来说,ping命令是第一个必须掌握的DOS命令,它所利用的原理是这样的:利用
-
Java获取磁盘空间的两种代码示例
本文分享了两段获取磁盘空间的代码,参考下. 代码1: import java.io.File; public class DiskSpaceDetail { public static void main(String[] args) { File diskPartition = new File("C:"); long totalCapacity = diskPartition.getTotalSpace(); long freePartitionSpace = diskPartit
-
Java基于递归和循环两种方式实现未知维度集合的笛卡尔积算法示例
本文实例讲述了Java基于递归和循环两种方式实现未知维度集合的笛卡尔积.分享给大家供大家参考,具体如下: 什么是笛卡尔积? 在数学中,两个集合X和Y的笛卡儿积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员. 假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}. 如何用程序算法实现笛卡尔积? 如果编程前已知集合的数量
-
Java多线程中线程的两种创建方式及比较代码示例
1.线程的概念:线程(thread)是指一个任务从头至尾的执行流,线程提供一个运行任务的机制,对于java而言,一个程序中可以并发的执行多个线程,这些线程可以在多处理器系统上同时运行.当程序作为一个应用程序运行时,java解释器为main()方法启动一个线程. 2.并行与并发: (1)并发:在单处理器系统中,多个线程共享CPU时间,而操作系统负责调度及分配资源给它们. (2)并行:在多处理器系统中,多个处理器可以同时运行多个线程,这些线程在同一时间可以同时运行,而不同于并发,只能多个线程共享CP