elasticsearch索引index之Translog数据功能分析
目录
跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。本篇就主要分析translog的结构及写入方式。
这一部分主要包括两部分translog和tanslogFile,前者对外提供了对translogFile操作的相关接口,后者则是具体的translogFile,它是具体的文件。首先看一下translogFile的继承关系,如下图所示:
实现了两种translogFile,它们的最大区别如名字所示就是写入时是否缓存。FsTranslogFile的接口如下所示:
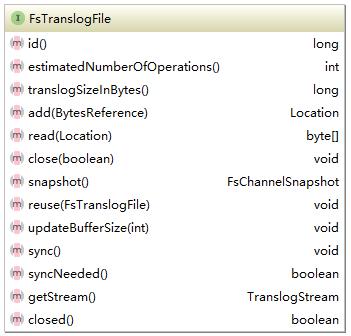
每一个translogFile都会有一个唯一Id,两个非常重要的方法add和write。add是添加对应的操作,这些操作都是在translog中定义,这里写入的只是byte类型的文件,不关注是何种操作。所有的操作都是顺序写入,因此读取的时候需要一个位置信息。add方法代码如下所示:

public Translog.Location add(BytesReference data) throws IOException {
rwl.writeLock().lock();//获取读写锁,每个文件的写入都是顺序的。
try {
operationCounter++;
long position = lastPosition;
if (data.length() >= buffer.length) {
flushBuffer();
// we use the channel to write, since on windows, writing to the RAF might not be reflected
// when reading through the channel
data.writeTo(raf.channel());//写入数据
lastWrittenPosition += data.length();
lastPosition += data.length();//记录位置
return new Translog.Location(id, position, data.length());//返回由id,位置及长度确定的操作位置信息。
}
if (data.length() > buffer.length - bufferCount) {
flushBuffer();
}
data.writeTo(bufferOs);
lastPosition += data.length();
return new Translog.Location(id, position, data.length());
} finally {
rwl.writeLock().unlock();
}
}
这是SimpleTranslogFile写入操作,BufferedTransLogFile写入逻辑基本相同,只是它不会立刻写入到硬盘,先进行缓存。另外TranslogFile还提供了一个快照的方法,该方法返回一个FileChannelSnapshot,可以通过它next方法将translogFile中所有的操作都读出来,写入到一个shapshot文件中。代码如下:
public FsChannelSnapshot snapshot() throws TranslogException {
if (raf.increaseRefCount()) {
boolean success = false;
try {
rwl.writeLock().lock();
try {
FsChannelSnapshot snapshot = new FsChannelSnapshot(this.id, raf, lastWrittenPosition, operationCounter);
snapshot.seekTo(this.headsuccess = true;
returnerSize);
snapshot;
} finally {
rwl.writeLock().unlock();
}
} catch (FileNotFoundException e) {
throw new TranslogException(shardId, "failed to create snapshot", e);
} finally {
if (!success) {
raf.decreaseRefCount(false);
}
}
}
return null;
}
TransLogFile是具体文件的抽象,它只是负责写入和读取,并不关心读取和写入的操作类型。各种操作的定义及对TransLogFile的定义到在Translog中。它的接口如下所示:

这里的写入(add)就是一个具体的操作,这是一个外部调用接口,索引、删除等修改索引的操作都会构造一个对应的Operation在对索引进行相关操作的同时调用该方法。这里还要着重说明一下makeTransientCurrent方法。操作的写入时刻进行,但是根据配置TransLogFile超过限度时需要删除重新开始一个新的文件。因此在transLog中存在两个TransLogFile,current和transient。当需要更换时需要通过读写锁确保单线程操作,将current切换到transient上来,然后删除之前的current。代码如下所示:
public void revertTransient() {
FsTranslogFile tmpTransient;
rwl.writeLock().lock();
try {
tmpTransient = trans;//交换
this.trans = null;
} finally {
rwl.writeLock().unlock();
}
logger.trace("revert transient {}", tmpTransient);
// previous transient might be null because it was failed on its creation
// for example
if (tmpTransient != null) {
tmpTransient.close(true);
}
}
translog中定义了index,create,delete及deletebyquery四种操作它们都继承自Operation。这四种操作也是四种能够改变索引数据的操作。operation代码如下所示:
static interface Operation extends Streamable {
static enum Type {
CREATE((byte) 1),
SAVE((byte) 2),
DELETE((byte) 3),
DELETE_BY_QUERY((byte) 4);
private final byte id;
private Type(byte id) {
this.id = id;
}
public byte id() {
return this.id;
}
public static Type fromId(byte id) {
switch (id) {
case 1:
return CREATE;
case 2:
return SAVE;
case 3:
return DELETE;
case 4:
return DELETE_BY_QUERY;
default:
throw new ElasticsearchIllegalArgumentException("No type mapped for [" + id + "]");
}
}
}
Type opType();
long estimateSize();
Source getSource();
}
tanslog部分就是实时记录所有的修改索引操作确保数据不丢失,因此它的实现上不上非常复杂。
总结:TransLog主要作用是实时记录对于索引的修改操作,确保在索引写入磁盘前出现系统故障不丢失数据。tanslog的主要作用就是索引恢复,正常情况下需要恢复索引的时候非常少,它以stream的形式顺序写入,不会消耗太多资源,不会成为性能瓶颈。它的实现上,translog提供了对外的接口,translogFile是具体的文件抽象,提供了对于文件的具体操作。
以上就是elasticsearch索引index之Translog数据功能分析的详细内容,更多关于elasticsearch索引index Translog数据功能的资料请关注我们其它相关文章!
相关推荐
-
Elasticsearch文档索引基本操作增删改查示例
接口幂等性 接口幂等性:数学概念,多次请求,相当于一次请求 get,put,delete都是幂等性的接口 post 存在幂等性的问题 前端速度很快,点了两次,会生成两个订单 用户在访问新增页面时(提交订单)--->接口返回一个唯一id,提交订单,携带唯一id过来,后端判断这个唯一id是否被用过--->没用过,创建订单 你在项目中碰到的问题和如何解决(项目收获)下订单,经常重复订单,点得快,幂等性问题,如何解决的 倒排索引 1.es介绍10个点 2.安装 -jdk :java开发环境 官网下载e
-
Elasticsearch索引的分片分配Recovery使用讲解
目录 什么是recovery? 减少集群full restart造成的数据来回拷贝 减少主副本之间的数据复制 特大热索引为何恢复慢 什么是recovery? 在elasticsearch中,recovery指的是一个索引的分片分配到另外一个节点的过程,一般在快照恢复.索引复制分片的变更.节点故障或重启时发生,由于master节点保存整个集群相关的状态信息,因此可以判断哪些分片需要再分配及分配到哪个节点,例如: 如果某个主分片在,而复制分片所在的节点挂掉了,那么master需要另行选择一个可用节点
-

elasticsearch索引index数据功能源码示例
从本篇开始,对elasticsearch的介绍将进入数据功能部分(index),这一部分包括索引的创建,管理,数据索引及搜索等相关功能.对于这一部分的介绍,首先对各个功能模块的分析,然后详细分析数据索引和搜索的整个流程. 这一部分从代码包结构上可以分为:index, indices及lucene(common)几个部分.index包中的代码主要是各个功能对应于lucene的底层操作,它们的操作对象是index的shard,是elasticsearch对lucene各个功能的扩展和封装.indic
-
Elasticsearch之倒排索引及索引操作
目录 倒排索引 一 倒排索引是什么 二 举例 三 倒排索引待解决的问题 索引操作 一 索引初始化 二 查询索引配置 三 更新索引 四 删除索引 倒排索引 一 倒排索引是什么 倒排索引源于实际应用中需要根据属性的值来查找记录,这种索引表中的每一个项都包括一个属性值和具有该属性值的各记录的地址.由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而成为倒排索引.带有倒排索引的文件我们称之为倒排索引文件,简称倒排文件 二 举例 例如有如下三个文件: 文件A:通过Python django搭建网
-
elasticsearch数据信息索引操作action support示例分析
目录 抽象类分析 doExecute方法 performOperation代码 master的相关操作 总结 抽象类分析 Action这一部分主要是数据(索引)的操作和部分集群信息操作. 所有的请求通过client转发到对应的action上然后再由对应的TransportAction来执行相关请求.如果请求能在本机上执行则在本机上执行,否则使用Transport进行转发到对应的节点.action support部分是对action的抽象,所有的具体action都继承了support action
-
elasticsearch源码分析index action实现方式
目录 action的作用 TransportAction的类图 OperationTransportHandler的代码 primary操作的方法 总结 action的作用 上一篇从结构上分析了action的,本篇将以index action为例仔分析一下action的实现方式. 再概括一下action的作用:对于每种功能(如index)action都会包括两个基本的类*action(IndexAction)和Transport*action(TransportIndexAction),前者类中
-
Elasticsearch Recovery索引分片分配详解
目录 基础知识点 减少集群Full Restart造成的数据来回拷贝 减少主副本之间的数据复制 特大热索引为何恢复慢 其他Recovery相关的专家级设置 基础知识点 在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程:一般在快照恢复.索引副本数变更.节点故障.节点重启时发生.由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如: 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用
-
elasticsearch索引index之Translog数据功能分析
目录 跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全.因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘.这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失.es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取.本篇就主要分析translog的结构及写入方式. 这一部分主要包括两部分translog和tanslogF
-
elasticsearch索引index之engine读写控制结构实现
目录 engine的实现结构 Engine类的方法: 如index方法的实现: 总结 engine的实现结构 elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engine的实现结构如下所示: engine接口有三个实现类,主要逻辑都在InternalEngine中. ShadowEngine之实现了engine接口的部分读方法,主要用于对于索引的读操作.
-
elasticsearch索引index之merge底层机制的合并讲解
merge是lucene的底层机制,merge过程会将index中的segment进行合并,生成更大的segment,提高搜索效率.segment是lucene索引的一种存储结构,每个segment都是一部分数据的完整索引,它是lucene每次flush或merge时候形成.每次flush就是将内存中的索引写出一个独立segment的过程.所以随着数据的不断增加,会形成越来越多的segment.因为segment是不可变的,删除操作不会改变segment内部数据,只是会在另外的地方记录某些数据删
-
elasticsearch索引index之Mapping实现关系结构示例
目录 Mapping的实现关系结构 parse方法 部分Field Mapping的实现关系结构 Lucene索引的一个特点就filed,索引以field组合.这一特点为索引和搜索提供了很大的灵活性.elasticsearch则在Lucene的基础上更近一步,它可以是 no scheme.实现这一功能的秘密就Mapping.Mapping是对索引各个字段的一种预设,包括索引与分词方式,是否存储等,数据根据字段名在Mapping中找到对应的配置,建立索引.这里将对Mapping的实现结构简单分析,
-
elasticsearch索引index之put mapping的设置分析
目录 mapping的设置过程 put mapping updateTask响应 总结 mapping的设置过程 mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设置,也可以在后期设置. 后期设置可以是修改mapping(无法对已有的field属性进行修改,一般来说只是增加新的field)或者对没有mapping的索引设置mapping. put mapping操作必须是master节点来完成,因为它涉及到集群mate
-
elasticsearch索引的创建过程index create逻辑分析
目录 索引的创建过程 materOperation方法实现 clusterservice处理 建立索引 修改配置 总结 索引的创建过程 从本篇开始,就进入了Index的核心代码部分.这里首先分析一下索引的创建过程.elasticsearch中的索引是多个分片的集合,它只是逻辑上的索引,并不具备实际的索引功能,所有对数据的操作最终还是由每个分片完成. 创建索引的过程,从elasticsearch集群上来说就是写入索引元数据的过程,这一操作只能在master节点上完成.这是一个阻塞式动作,在加上分配
-
python Elasticsearch索引建立和数据的上传详解
今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch. ok,先来介绍一下Elaticsearch,它是一款基于lucene的实时分布式搜索和分析引擎,是后台系统,用来存储数据,检索数据,属于完全命令行交互. 那为什么选择python作为脚本进行命令的写入和数据的上传呢?那是因为Python里面有固定的模板,可以上传数据到Elasticsearch. 接下来就聊一聊该如何编写代码: 我们上传数据之后,数据到哪里去了呢? 存在索引里面了. 那
-
elasticsearch索引创建create index集群matedata更新
目录 创建索引更新集群index matedata 首先创建index的create方法 从indice中获取对应的IndexService 总结 创建索引更新集群index matedata 创建索引需要创建索引并且更新集群index matedata,这一过程在MetaDataCreateIndexService的createIndex方法中完成.这里会提交一个高优先级,AckedClusterStateUpdateTask类型的task.索引创建需要即时得到反馈,异常这个task需要返回,