java导出dbf文件生僻汉字处理方式
java导出dbf文件生僻汉字处理
java导出数据到dbf文件,如果姓名中有生僻汉字,在dbf中看到的很可能是?号。
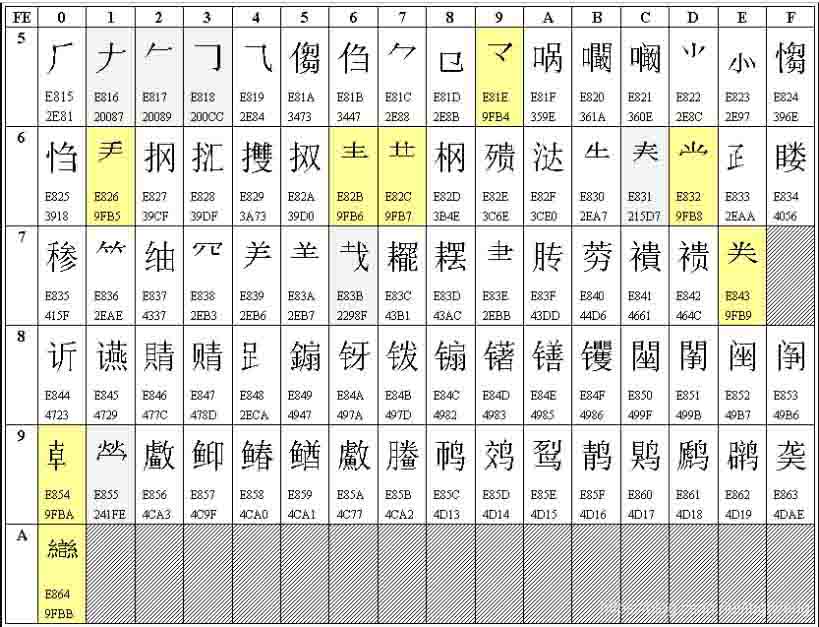
遇到这种情况需查对GBK的生僻汉字的Unicode表,GBK提及的52个生僻汉字有两种Unicode。
例如:
䶮(yan 3) \u4ADE就不能在dbf中正常显示是?
如果换成\uE863则可以(可以打开word的插入->符号->其他符号,在字符代码中输入4ADE的到字符插入word,输入E863的到另一形式插入word,将这两种形式的字符从word拷贝到Visual Fox Pro的命令窗口可以看到差别,一个变成?一个能正常显示)。
解决方式:
1.建立52个生僻汉字的unicode映射Map
2.将生僻汉字转成unicode形式(有可能是将整个姓名转成unicode)
3.将姓名的unicode形式进行分割(\u)生成数组(注意两端的双引号)
4.遍历unicode数组,如果找到生僻汉字的unicode则进行替换
5.将unicode还原成汉字
6.写入dbf
汉字转unicode可利用(import com.alibaba.fastjson.JSON) :
//unicode转中文
public static String unicodeToString(String str) {
return String.valueOf(JSON.parse(str));
}
//中文字符转unicode
public static String stringToUnicode(String s) {
return JSON.toJSONString(s, SerializerFeature.BrowserCompatible);
}
其他说明:
例如:
䶮在mysql中能显示出来,导出到dbf中时如果选择 字符集为 GB2312或GBK,导出的 䶮为?。
在Visual Fox Pro 9的命令窗口里输入的 䶮为?
打开word,插入,输入字符编码4DAE得到 䶮,插入到word,复制粘贴到 Visual Fox Pro 9的命令窗口改字显示 为?
打开word,插入,输入字符编码8E63得到 ,有些版本的Word能显示出来,有些版本的不能显示,按Alt+X ,插入到word,复制粘贴到 Visual Fox Pro 9的命令窗口改字能显示 正常
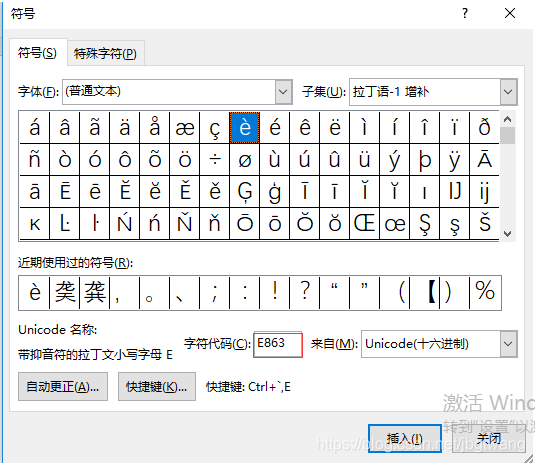
上图输入E863无反应
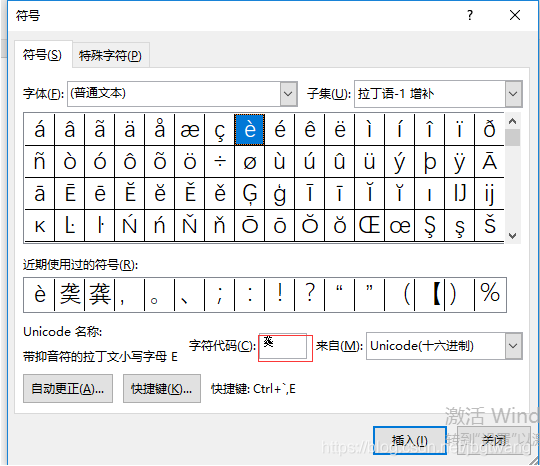
按快捷键Alt+x后的效果
java-dbf中文标题乱码
项目中需要对DBF的文件进行导入处理,上网搜了发现有java-dbf这个东西。实际应用中踩了不少坑,主要就是中文乱码的问题。
InputStream in = new FileInputStream("D:\\test.dbf");
DBFReader reader = new DBFReader(in);
reader.setCharactersetName("GBK");
for(int i = 0; i < reader.getFieldCount(); i++){
DBFField field = reader.getField(i);
System.out.print(field.getName() + ",");
}
System.out.print("\r\n");
Object[] values;
while ( (values = reader.nextRecord()) != null ){
for(Object value : values){
System.out.print(value.toString() + ",");
}
System.out.print("\r\n");
}
网上写法千篇一律,大概就是这样。问题来了DBF中具体数据的中文乱码通过reader.setCharactersetName("GBK")解决了。
但是发现列名的乱码还是没有解决
后来查了一下源码,发现了问题所在
public DBFReader(InputStream in, Charset charset, boolean showDeletedRows) {
try {
this.showDeletedRows = showDeletedRows;
this.inputStream = in;
this.dataInputStream = new DataInputStream(this.inputStream);
this.header = new DBFHeader();
this.header.read(this.dataInputStream, charset, showDeletedRows);
setCharset(this.header.getUsedCharset());
/* it might be required to leap to the start of records at times */
int fieldSize = this.header.getFieldDescriptorSize();
int tableSize = this.header.getTableHeaderSize();
int t_dataStartIndex = this.header.headerLength - (tableSize + (fieldSize * this.header.fieldArray.length)) - 1;
skip(t_dataStartIndex);
this.mapFieldNames = createMapFieldNames(this.header.userFieldArray);
} catch (IOException e) {
DBFUtils.close(dataInputStream);
DBFUtils.close(in);
throw new DBFException(e.getMessage(), e);
}
}
其中header就是我们读取的列名,列数所依靠的成员变量,但是这个变量在对象创建的时候就赋值好了。
这就导致了后来即使调用了setCharactersetName也解决不了列名乱码问题。
所以我们要从根本上解决问题,创建对象的时候直接传入charset对象。
修改后代码如下
public static void main(String[] args) throws FileNotFoundException {
InputStream in = new FileInputStream("D:\\test.dbf");
Charset charset = Charset.forName("GBK");
DBFReader reader = new DBFReader(in,charset);
for(int i = 0; i < reader.getFieldCount(); i++){
DBFField field = reader.getField(i);
System.out.print(field.getName() + ",");
}
System.out.print("\r\n");
Object[] values;
while ( (values = reader.nextRecord()) != null ){
for(Object value : values){
System.out.print(value.toString() + ",");
}
System.out.print("\r\n");
}
}
输出时候列名就正常了
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java汉字转拼音类库Pinyin4j详细使用方法与实例
汉字转拼音类库Pinyin4j一般用法 pinyin4j的使用很方便,一般转换只需要使用PinyinHelper类的静态工具方法即可: String[] pinyin = PinyinHelper.toHanyuPinyinStringArray('刘'); //该类还有其他的拼音转换形式,但是基本上用不到,就不介绍了 返回的数组即是该字符的拼音,如上例就是pinyin[0]=liu2,后面的数字代表声调,声调为5表示轻读,无声调.之所谓返回数组,是因为被判定的汉字有可能有多个读音.如果输入的参
-
java解析dbf之通过javadbf包生成和读取dbf文件
以下是简单示例 复制代码 代码如下: package com.cramc; import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStream; import com.linuxense.javadbf.DBFException;import com.lin
-
JAVA 根据数据库表内容生产树结构JSON数据的实例代码
1.利用场景 组织机构树,通常会有组织机构表,其中有code(代码),pcode(上级代码),name(组织名称)等字段 2.构造数据(以下数据并不是组织机构数据,而纯属本人胡编乱造的数据) List<Tree<Test>> trees = new ArrayList<Tree<Test>>(); tests.add(new Test("0", "", "关于本人")); tests.add(new
-

java导出dbf文件生僻汉字处理方式
java导出dbf文件生僻汉字处理 java导出数据到dbf文件,如果姓名中有生僻汉字,在dbf中看到的很可能是?号. 遇到这种情况需查对GBK的生僻汉字的Unicode表,GBK提及的52个生僻汉字有两种Unicode. 例如: 䶮(yan 3) \u4ADE就不能在dbf中正常显示是? 如果换成\uE863则可以(可以打开word的插入->符号->其他符号,在字符代码中输入4ADE的到字符插入word,输入E863的到另一形式插入word,将这两种形式的字符从word拷贝到Visual F
-
Java导出txt文件的方法
本文实例讲述了Java导出txt文件的方法.分享给大家供大家参考.具体如下: 例子一 /** * export导出文件 */ @RequestMapping(value="/grab/export/csv",method={RequestMethod.GET}) public void exportCsv(HttpServletRequest request,HttpServletResponse response){ String userId = ServletRequestUti
-
Python导出DBF文件到Excel的方法
本文实例讲述了Python导出DBF文件到Excel的方法.分享给大家供大家参考.具体如下: from dbfpy import dbf from time import sleep from win32com import client def dbf2xls(dbfilename, exfilename): db = dbf.Dbf(dbfilename, True) ex = client.Dispatch('Excel.Application') wk = ex.Workbooks.Ad
-
JAVA导出CSV文件实例教程
以前导出总是用POI导出为Excel文件,后来当我了解到CSV以后,我发现速度飞快. 如果导出的数据不要求格式.样式.公式等等,建议最好导成CSV文件,因为真的很快. 虽然我们可以用Java再带的文件相关的类去操作以生成一个CSV文件,但事实上有好多第三方类库也提供了类似的功能. 这里我们使用apache提供的commons-csv组件 Commons CSV 文档在这里 http://commons.apache.org/ http://commons.apache.org/proper/co
-
Java导出CSV文件的方法
本文实例为大家分享了Java导出CSV文件的具体代码,供大家参考,具体内容如下 Java导出csv文件: 控制层: @Controller @RequestMapping("/historyReport/") public class HistoryStockReportController { private static final Logger LOGGER = LoggerFactory.getLogger(HistoryStockReportController.class)
-
Java 导出 CSV 文件操作详情
首先第一步 导入坐标: <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-csv</artifactId> <version>1.6</version> </dependency> 第二步 引入工具类 说明下 因为这个工具类用到是Listj集合我就顺带吧 实体类和map 之间的转换也说了 import org.apach
-
java导出Excel文件的步骤全纪录
一.背景 当前B/S模式已成为应用开发的主流,而在企业办公系统中,常常有客户这样子要求:你要把我们的报表直接用Excel打开(电信系统.银行系统).或者是:我们已经习惯用Excel打印.这样在我们实际的开发中,很多时候需要实现导入.导出Excel的应用. 最近在java上做了一个EXCEL的导出功能,写了一个通用类,在这里分享分享,该类支持多sheet,且无需手动进行复杂的类型转换,只需提供三个参数即可: 1.fileName excel文件名 2.HasMap<String,List<?&g
-
Java使用poi导出ppt文件的实现代码
什么是poi Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程式对Microsoft Office格式档案读和写的功能.POI为"Poor Obfuscation Implementation"的首字母缩写,意为"简洁版的模糊实现". poi常用的包 HSSF - 提供读写Microsoft Excel XLS格式档案的功能. XSSF - 提供读写Microsoft Excel OOXML
-
java中的export方法实现导出excel文件
目录 1.export函数 2.导出列名 3.export实现方法 4.前端对接 5.前端代码 1.export函数 //导出文件接口 public String export(){ return this.myExport(exportList); } 2.导出列名 private String myExport(List<BusinessDept> list){ com.bronzesoft.power.tools.json.JSONObject info = new com.bronze
-
Java调用dll文件的实现解析
目录 Java调用dll文件 环境 接下来进入正文 Java调用dll文件几种常见方式 Java调用动态库需要关注的问题 一.数据类型对应关系 二.Jnative调用dll 三.JNA调用dll Java调用dll文件 近期根据C++做了一个图片质量检测的项目,目前需要在在java中进行调用,所以先在C++上生成dll文件,然后基于java调用dll文件实现功能. 环境 C++:VS2017(之前配置opencv真是要了老命) java:idea2020+jdk1.8. 注意:jdk安装的时候小