C++实现简单BP神经网络
本文实例为大家分享了C++实现简单BP神经网络的具体代码,供大家参考,具体内容如下
实现了一个简单的BP神经网络
使用EasyX图形化显示训练过程和训练结果
使用了25个样本,一共训练了1万次。
该神经网络有两个输入,一个输出端
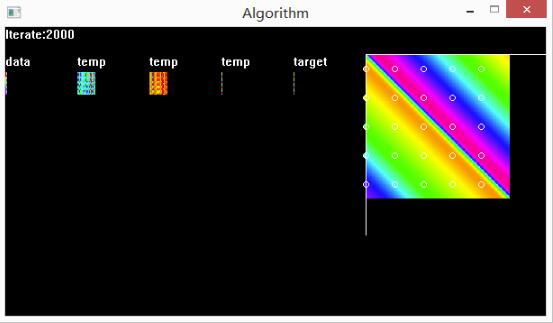
下图是训练效果,data是训练的输入数据,temp代表所在层的输出,target是训练目标,右边的大图是BP神经网络的测试结果。
以下是详细的代码实现,主要还是基本的矩阵运算。
#include <stdio.h>
#include <stdlib.h>
#include <graphics.h>
#include <time.h>
#include <math.h>
#define uint unsigned short
#define real double
#define threshold (real)(rand() % 99998 + 1) / 100000
// 神经网络的层
class layer{
private:
char name[20];
uint row, col;
uint x, y;
real **data;
real *bias;
public:
layer(){
strcpy_s(name, "temp");
row = 1;
col = 3;
x = y = 0;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
data[i][j] = 1;
}
}
}
layer(FILE *fp){
fscanf_s(fp, "%d %d %d %d %s", &row, &col, &x, &y, name);
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
fscanf_s(fp, "%lf", &data[i][j]);
}
}
}
layer(uint row, uint col){
strcpy_s(name, "temp");
this->row = row;
this->col = col;
this->x = 0;
this->y = 0;
this->data = new real*[row];
this->bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
data[i][j] = 1.0f;
}
}
}
layer(const layer &a){
strcpy_s(name, a.name);
row = a.row, col = a.col;
x = a.x, y = a.y;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = a.bias[i];
for (uint j = 0; j < col; j++){
data[i][j] = a.data[i][j];
}
}
}
~layer(){
// 删除原有数据
for (uint i = 0; i < row; i++){
delete[]data[i];
}
delete[]data;
}
layer& operator =(const layer &a){
// 删除原有数据
for (uint i = 0; i < row; i++){
delete[]data[i];
}
delete[]data;
delete[]bias;
// 重新分配空间
strcpy_s(name, a.name);
row = a.row, col = a.col;
x = a.x, y = a.y;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = a.bias[i];
for (uint j = 0; j < col; j++){
data[i][j] = a.data[i][j];
}
}
return *this;
}
layer Transpose() const {
layer arr(col, row);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[j][i] = data[i][j];
}
}
return arr;
}
layer sigmoid(){
layer arr(col, row);
arr.x = x, arr.y = y;
for (uint i = 0; i < x.row; i++){
for (uint j = 0; j < x.col; j++){
arr.data[i][j] = 1 / (1 + exp(-data[i][j]));// 1/(1+exp(-z))
}
}
return arr;
}
layer operator *(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] * b.data[i][j];
}
}
return arr;
}
layer operator *(const int b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = b * data[i][j];
}
}
return arr;
}
layer matmul(const layer &b){
layer arr(row, b.col);
arr.x = x, arr.y = y;
for (uint k = 0; k < b.col; k++){
for (uint i = 0; i < row; i++){
arr.bias[i] = bias[i];
arr.data[i][k] = 0;
for (uint j = 0; j < col; j++){
arr.data[i][k] += data[i][j] * b.data[j][k];
}
}
}
return arr;
}
layer operator -(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] - b.data[i][j];
}
}
return arr;
}
layer operator +(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] + b.data[i][j];
}
}
return arr;
}
layer neg(){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = -data[i][j];
}
}
return arr;
}
bool operator ==(const layer &a){
bool result = true;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
if (abs(data[i][j] - a.data[i][j]) > 10e-6){
result = false;
break;
}
}
}
return result;
}
void randomize(){
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
data[i][j] = threshold;
}
bias[i] = 0.3;
}
}
void print(){
outtextxy(x, y - 20, name);
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
COLORREF color = HSVtoRGB(360 * data[i][j], 1, 1);
putpixel(x + i, y + j, color);
}
}
}
void save(FILE *fp){
fprintf_s(fp, "%d %d %d %d %s\n", row, col, x, y, name);
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
fprintf_s(fp, "%lf ", data[i][j]);
}
fprintf_s(fp, "\n");
}
}
friend class network;
friend layer operator *(const double a, const layer &b);
};
layer operator *(const double a, const layer &b){
layer arr(b.row, b.col);
arr.x = b.x, arr.y = b.y;
for (uint i = 0; i < arr.row; i++){
for (uint j = 0; j < arr.col; j++){
arr.data[i][j] = a * b.data[i][j];
}
}
return arr;
}
// 神经网络
class network{
int iter;
double learn;
layer arr[3];
layer data, target, test;
layer& unit(layer &x){
for (uint i = 0; i < x.row; i++){
for (uint j = 0; j < x.col; j++){
x.data[i][j] = i == j ? 1.0 : 0.0;
}
}
return x;
}
layer grad_sigmoid(layer &x){
layer e(x.row, x.col);
e = x*(e - x);
return e;
}
public:
network(FILE *fp){
fscanf_s(fp, "%d %lf", &iter, &learn);
// 输入数据
data = layer(fp);
for (uint i = 0; i < 3; i++){
arr[i] = layer(fp);
//arr[i].randomize();
}
target = layer(fp);
// 测试数据
test = layer(2, 40000);
for (uint i = 0; i < test.col; i++){
test.data[0][i] = ((double)i / 200) / 200.0f;
test.data[1][i] = (double)(i % 200) / 200.0f;
}
}
void train(){
int i = 0;
char str[20];
data.print();
target.print();
for (i = 0; i < iter; i++){
sprintf_s(str, "Iterate:%d", i);
outtextxy(0, 0, str);
// 正向传播
layer l0 = data;
layer l1 = arr[0].matmul(l0).sigmoid();
layer l2 = arr[1].matmul(l1).sigmoid();
layer l3 = arr[2].matmul(l2).sigmoid();
// 显示输出结果
l1.print();
l2.print();
l3.print();
if (l3 == target){
break;
}
// 反向传播
layer l3_delta = (l3 - target ) * grad_sigmoid(l3);
layer l2_delta = arr[2].Transpose().matmul(l3_delta) * grad_sigmoid(l2);
layer l1_delta = arr[1].Transpose().matmul(l2_delta) * grad_sigmoid(l1);
// 梯度下降法
arr[2] = arr[2] - learn * l3_delta.matmul(l2.Transpose());
arr[1] = arr[1] - learn * l2_delta.matmul(l1.Transpose());
arr[0] = arr[0] - learn * l1_delta.matmul(l0.Transpose());
}
sprintf_s(str, "Iterate:%d", i);
outtextxy(0, 0, str);
// 测试输出
// selftest();
}
void selftest(){
// 测试
layer l0 = test;
layer l1 = arr[0].matmul(l0).sigmoid();
layer l2 = arr[1].matmul(l1).sigmoid();
layer l3 = arr[2].matmul(l2).sigmoid();
setlinecolor(WHITE);
// 测试例
for (uint j = 0; j < test.col; j++){
COLORREF color = HSVtoRGB(360 * l3.data[0][j], 1, 1);// 输出颜色
putpixel((int)(test.data[0][j] * 160) + 400, (int)(test.data[1][j] * 160) + 30, color);
}
// 标准例
for (uint j = 0; j < data.col; j++){
COLORREF color = HSVtoRGB(360 * target.data[0][j], 1, 1);// 输出颜色
setfillcolor(color);
fillcircle((int)(data.data[0][j] * 160) + 400, (int)(data.data[1][j] * 160) + 30, 3);
}
line(400, 30, 400, 230);
line(400, 30, 600, 30);
}
void save(FILE *fp){
fprintf_s(fp, "%d %lf\n", iter, learn);
data.save(fp);
for (uint i = 0; i < 3; i++){
arr[i].save(fp);
}
target.save(fp);
}
};
#include "network.h"
void main(){
FILE file;
FILE *fp = &file;
// 读取状态
fopen_s(&fp, "Text.txt", "r");
network net(fp);
fclose(fp);
initgraph(600, 320);
net.train();
// 保存状态
fopen_s(&fp, "Text.txt", "w");
net.save(fp);
fclose(fp);
getchar();
closegraph();
}
上面这段代码是在2016年初实现的,非常简陋,且不利于扩展。时隔三年,我再次回顾了反向传播算法,重构了上面的代码。
最近,参考【深度学习】一书对反向传播算法的描述,我用C++再次实现了基于反向传播算法的神经网络框架:Github: Neural-Network。该框架支持张量运算,如卷积,池化和上采样运算。除了能实现传统的stacked网络模型,还实现了基于计算图的自动求导算法,目前还有些bug。预计支持搭建卷积神经网络,并实现【深度学习】一书介绍的一些基于梯度的优化算法。
欢迎感兴趣的同学在此提出宝贵建议。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
C++实现神经BP神经网络
本文实例为大家分享了C++实现神经BP神经网络的具体代码,供大家参考,具体内容如下 BP.h #pragma once #include<vector> #include<stdlib.h> #include<time.h> #include<cmath> #include<iostream> using std::vector; using std::exp; using std::cout; using std::endl; class BP
-
C++实现简单BP神经网络
本文实例为大家分享了C++实现简单BP神经网络的具体代码,供大家参考,具体内容如下 实现了一个简单的BP神经网络 使用EasyX图形化显示训练过程和训练结果 使用了25个样本,一共训练了1万次. 该神经网络有两个输入,一个输出端 下图是训练效果,data是训练的输入数据,temp代表所在层的输出,target是训练目标,右边的大图是BP神经网络的测试结果. 以下是详细的代码实现,主要还是基本的矩阵运算. #include <stdio.h> #include <stdlib.h>
-

Python实现的三层BP神经网络算法示例
本文实例讲述了Python实现的三层BP神经网络算法.分享给大家供大家参考,具体如下: 这是一个非常漂亮的三层反向传播神经网络的python实现,下一步我准备试着将其修改为多层BP神经网络. 下面是运行演示函数的截图,你会发现预测的结果很惊人! 提示:运行演示函数的时候,可以尝试改变隐藏层的节点数,看节点数增加了,预测的精度会否提升 import math import random import string random.seed(0) # 生成区间[a, b)内的随机数 def rand(
-
Python使用numpy实现BP神经网络
本文完全利用numpy实现一个简单的BP神经网络,由于是做regression而不是classification,因此在这里输出层选取的激励函数就是f(x)=x.BP神经网络的具体原理此处不再介绍. import numpy as np class NeuralNetwork(object): def __init__(self, input_nodes, hidden_nodes, output_nodes, learning_rate): # Set number of nodes in i
-
基于python的BP神经网络及异或实现过程解析
BP神经网络是最简单的神经网络模型了,三层能够模拟非线性函数效果. 难点: 如何确定初始化参数? 如何确定隐含层节点数量? 迭代多少次?如何更快收敛? 如何获得全局最优解? ''' neural networks created on 2019.9.24 author: vince ''' import math import logging import numpy import random import matplotlib.pyplot as plt ''' neural network
-
基于Matlab实现BP神经网络交通标志识别
目录 一.BP神经网络交通标志识别简介 二.部分源代码 三.运行结果 一.BP神经网络交通标志识别简介 道路交通标志用以禁止.警告.指示和限制道路使用者有秩序地使用道路, 保障出行安全.若能自动识别道路交通标志, 则将极大减少道路交通事故的发生.但是由于道路交通错综复杂, 且智能识别技术尚未成熟, 为了得到高效实用的道路标志识别系统, 仍需进行大量的研究.限速交通标志的检测识别作为道路交通标志识别系统的一个重要组成部分, 对它的研究具有非常重要的意义. 目前国内已有不少学者针对道路交通标志牌的智
-
Java实现BP神经网络MNIST手写数字识别的示例详解
目录 一.神经网络的构建 二.系统架构 服务器 客户端 采用MVC架构 一.神经网络的构建 (1):构建神经网络层次结构 由训练集数据可知,手写输入的数据维数为784维,而对应的输出结果为分别为0-9的10个数字,所以根据训练集的数据可知,在构建的神经网络的输入层的神经元的节点个数为784个,而对应的输出层的神经元个数为10个.隐层可选择单层或多层. (2):确定隐层中的神经元的个数 因为对于隐层的神经元个数的确定目前还没有什么比较完美的解决方案,所以对此经过自己查阅书籍和上网查阅资料,有以下的
-
基于Java实现的一层简单人工神经网络算法示例
本文实例讲述了基于Java实现的一层简单人工神经网络算法.分享给大家供大家参考,具体如下: 先来看看笔者绘制的算法图: 2.数据类 import java.util.Arrays; public class Data { double[] vector; int dimention; int type; public double[] getVector() { return vector; } public void setVector(double[] vector) { this.vect
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测
-
tensorflow建立一个简单的神经网络的方法
本笔记目的是通过tensorflow实现一个两层的神经网络.目的是实现一个二次函数的拟合. 如何添加一层网络 代码如下: def add_layer(inputs, in_size, out_size, activation_function=None): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) bia
-
tensorflow构建BP神经网络的方法
之前的一篇博客专门介绍了神经网络的搭建,是在python环境下基于numpy搭建的,之前的numpy版两层神经网络,不能支持增加神经网络的层数.最近看了一个介绍tensorflow的视频,介绍了关于tensorflow的构建神经网络的方法,特此记录. tensorflow的构建封装的更加完善,可以任意加入中间层,只要注意好维度即可,不过numpy版的神经网络代码经过适当地改动也可以做到这一点,这里最重要的思想就是层的模型的分离. import tensorflow as tf import nu