JVM内存结构:程序计数器、虚拟机栈、本地方法栈
目录
- 一、JVM 入门介绍
- JVM 定义
- JVM 优势
- JVM JRE JDK的比较
- 学习步骤
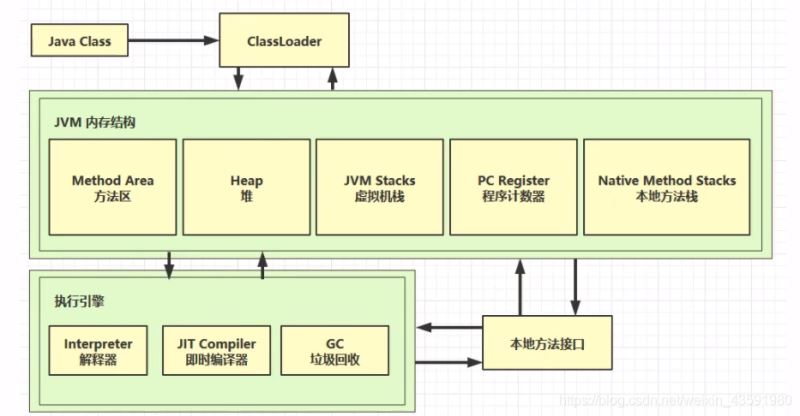
- 二、内存结构
- 整体架构
- 1、程序计数器(寄存器)
- 1.1 作用
- 1.2 特点
- 2、虚拟机栈
- 2.1 定义
- 2.2 演示
- 2.3 面试问题辨析
- 2.4 内存溢出
- 2.5 线程运行诊断
- 3、本地方法栈
- 4、总结
一、JVM 入门介绍
JVM 定义
Java Virtual Machine,JAVA程序的运行环境(JAVA二进制字节码的运行环境)
JVM 优势
- 一次编写,到处运行
- 自动内存管理,垃圾回收机制
- 数组下标越界检查 常见的JVM
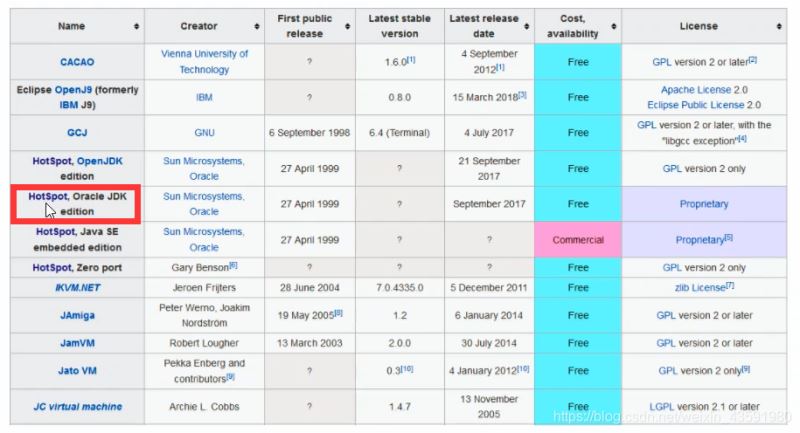
注:我们笔记所使用的的是HotSpot 版本
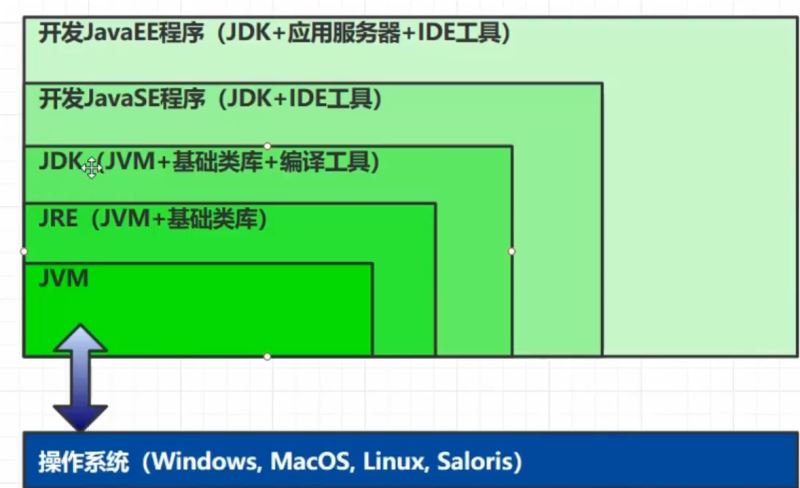
JVM JRE JDK的比较
JVM JRE JDK的区别:
学习步骤
学习顺序如下图:(由简到难)
二、内存结构
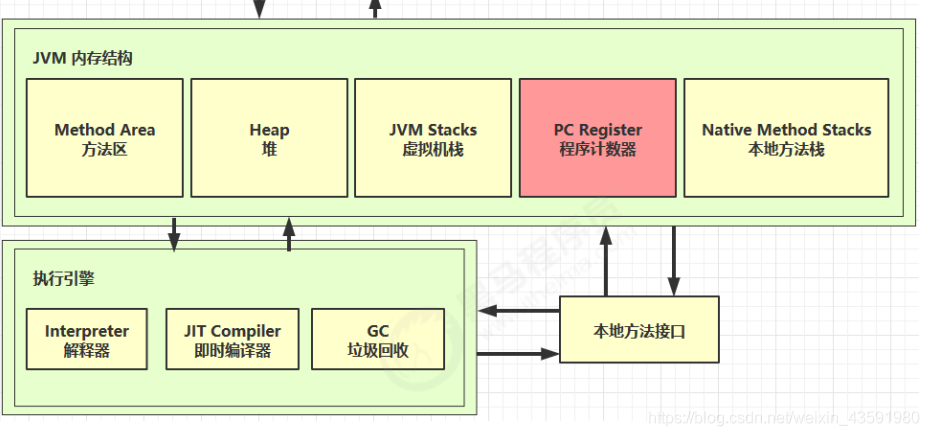
整体架构
1、程序计数器(寄存器)
Program Counter Register
1.1 作用
程序计数器用于保存JVM中下一条所要执行的指令的地址
0:getstatic #20 // PrintStream out = System.out; 1:astore_1 // -- 2:aload_1 // out.println(1); 3:iconst_1 // -- 4:invokevirtual #26 // -- 5:aload_1 // out.println(2); 6:iconst_2 // -- 7:invokevirtual #26 // -- 8:aload_1 // out.println(3); 9:iconst_3 // -- 10:invokevirtual #26 // -- 11:aload_1 // out.println(4); 12:iconst_4 // -- 13:invokevirtual #26 // -- 14:aload_1 // out.println(5); 15:iconst_5 // -- 16:invokevirtual #26 // -- return
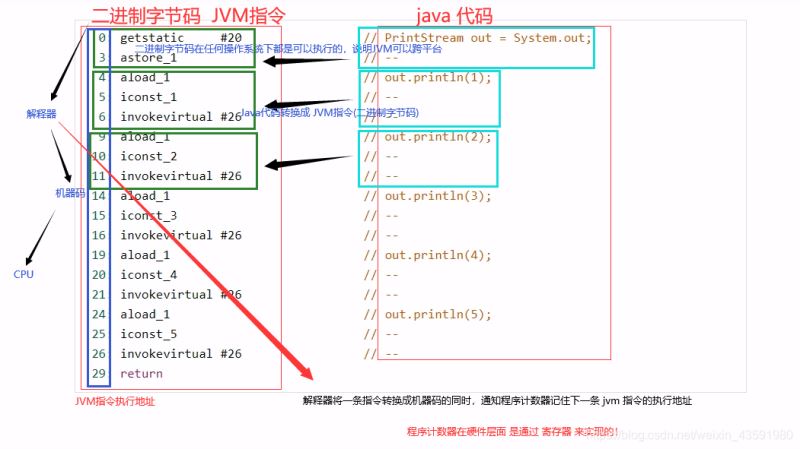
Java指令执行流程:
- 每一条二进制字节码(JVM指令) 通过 解释器 转换成 机器码 然后 就可以被 CPU 执行了!
- 当 解释器 将一条jvm 指令转换成 机器码后 其会 向程序计数器 递交 下一条 jvm 指令的执行地址!
- 程序计数器在硬件层面 其实是通过 寄存器 实现的!
- 所以程序计数器的作用就是:用于保存JVM中下一条所要执行的指令的地址!
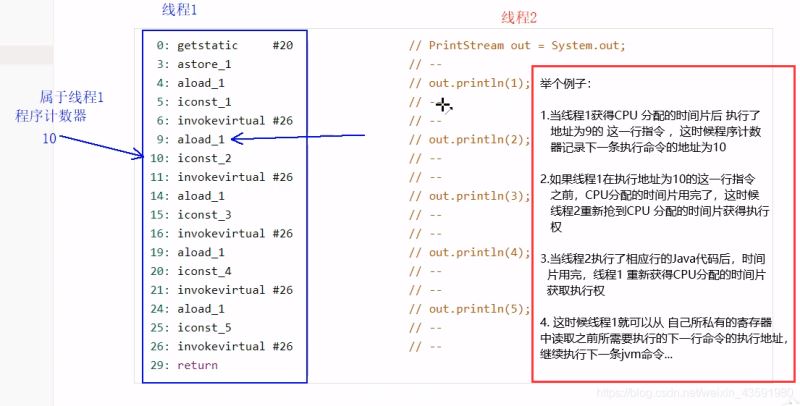
1.2 特点
- 线程私有
- CPU会为每个线程分配时间片,当当 前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码
- 程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
- 不会存在内存溢出
2、虚拟机栈
Java Virtual Machine Stacks
2.1 定义
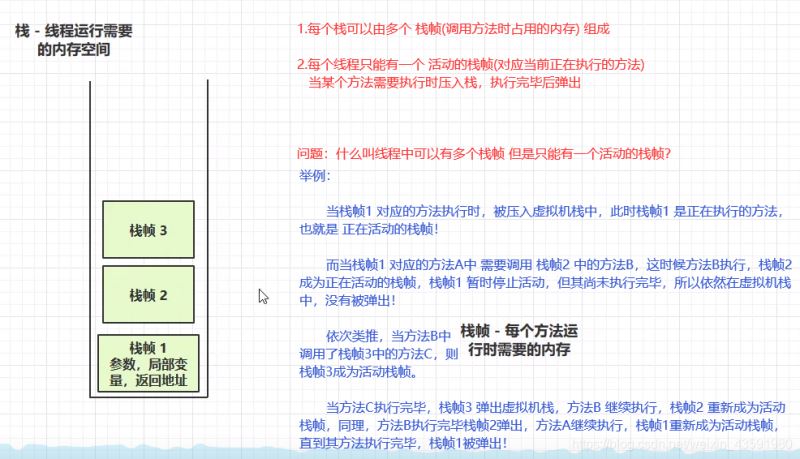
- 每个线程运行需要的内存空间,这一空间被称为虚拟机栈(Frames)
- 每个栈由多个栈帧(Frame) 组成,对应着每个方法运行时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的方法,当方法执行时压入栈,方法执行完毕后 弹出栈
2.2 演示
代码
/**
* @Auther: csp1999
* @Date: 2020/11/10/11:36
* @Description: 演示栈帧
*/
public class Demo01 {
public static void main(String[] args) {
methodA();
}
private static void methodA() {
methodB(1, 2);
}
private static int methodB(int a, int b) {
int c = a + b;
return c;
}
}
我们打断点来Debug 一下看一下方法执行的流程:

接这往下走,使方法B执行完毕:
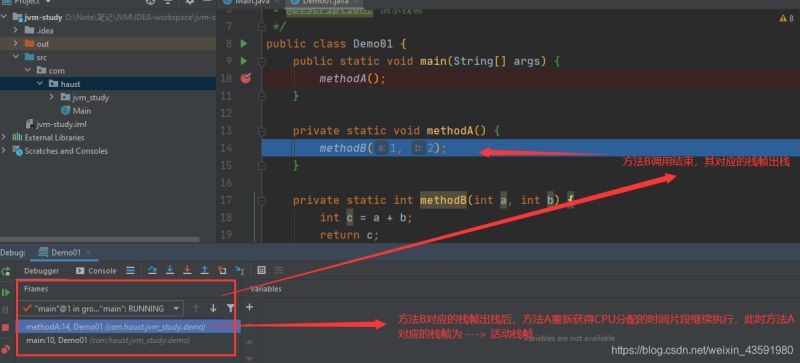
然后方法A执行完毕,其对应的栈帧出栈,main方法对应的栈帧为活动栈帧;最后main执行完毕 栈帧出栈,虚拟机栈为空,代码运行结束!
2.3 面试问题辨析
- 1.垃圾回收是否涉及栈内存?
- 不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
- 2.栈内存的分配越大越好吗?
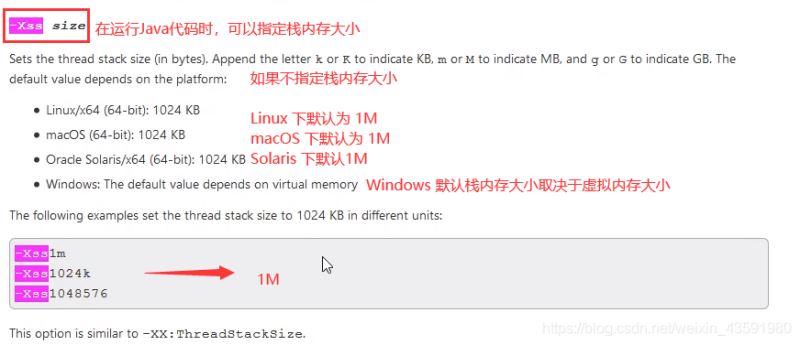
- 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
- 举例:如果物理内存是500M(假设),如果一个线程所能分配的栈内存为2M的话,那么可以有250个线程。而如果一个线程分配栈内存占5M的话,那么最多只能有100 个线程同时执行!
3.方法内的局部变量是否是线程安全的?
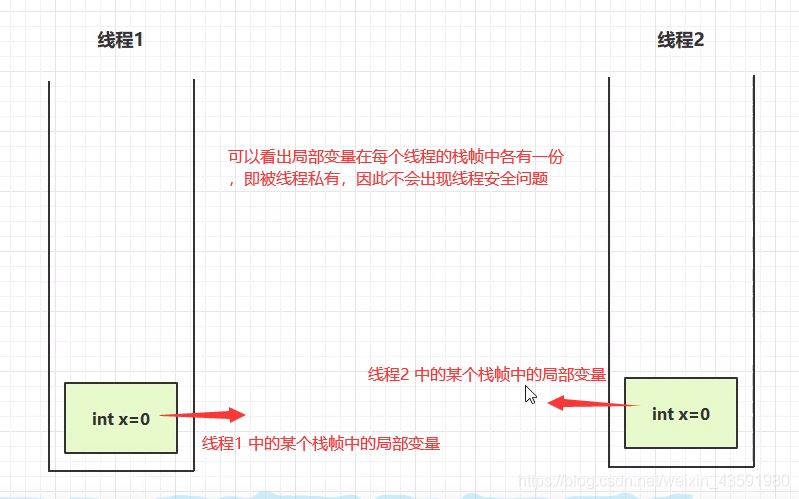
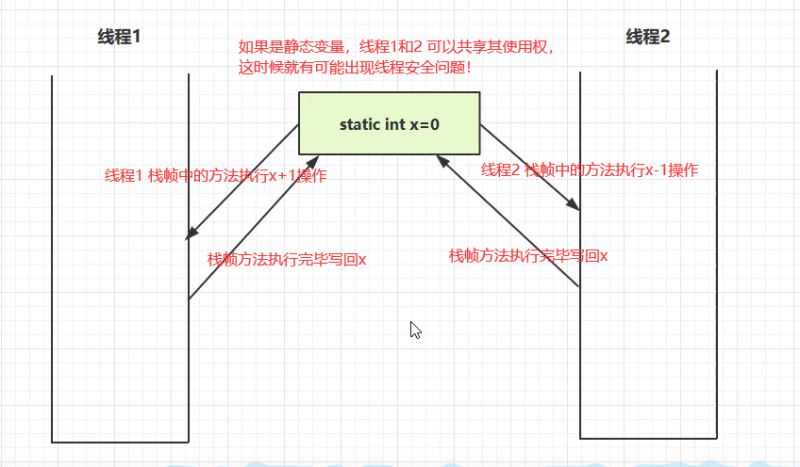
从图中得出:局部变量如果是静态的可以被多个线程共享,那么就存在线程安全问题。如果是非静态的只存在于某个方法作用范围内,被线程私有,那么就是线程安全的!
看一个案例:
/**
* 局部变量的线程安全问题
*/
public class Demo02 {
public static void main(String[] args) {// main 函数主线程
StringBuilder sb = new StringBuilder();
sb.append(4);
sb.append(5);
sb.append(6);
new Thread(() -> {// Thread新创建的线程
m2(sb);
}).start();
}
public static void m1() {
// sb 作为方法m1()内部的局部变量,是线程私有的 ---> 线程安全
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static void m2(StringBuilder sb) {
// sb 作为方法m2()外部的传递来的参数,sb 不在方法m2()的作用范围内
// 不是线程私有的 ---> 非线程安全
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static StringBuilder m3() {
// sb 作为方法m3()内部的局部变量,是线程私有的
StringBuilder sb = new StringBuilder();// sb 为引用类型的变量
sb.append(1);
sb.append(2);
sb.append(3);
return sb;// 然而方法m3()将sb返回,sb逃离了方法m3()的作用范围,且sb是引用类型的变量
// 其他线程也可以拿到该变量的 ---> 非线程安全
// 如果sb是非引用类型,即基本类型(int/char/float...)变量的话,逃离m3()作用范围后,则不会存在线程安全
}
}
该面试题答案:
如果方法内局部变量没有逃离方法的作用范围,则是线程安全的
如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题
2.4 内存溢出
Java.lang.stackOverflowError 栈内存溢出
发生原因
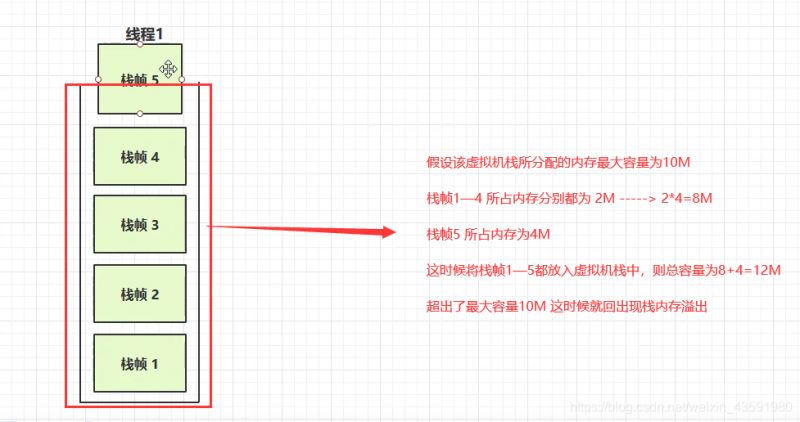
- 1.虚拟机栈中,栈帧过多(无限递归),这种情况比较常见!
- 2.每个栈帧所占用内存过大(某个/某几个栈帧内存直接超过虚拟机栈最大内存),这种情况比较少见!
举2个案例:
案例1:
/**
* 演示栈内存溢出 java.lang.StackOverflowError
* -Xss256k 可以通过栈内存参数 设置栈内存大小
*/
public class Demo03 {
private static int count;
public static void main(String[] args) {
try {
method1();
} catch (Throwable e) {
e.printStackTrace();
System.out.println(count);
}
}
private static void method1() {
count++;// 统计栈帧个数
method1();// 方法无限递归,不断产生栈帧 到虚拟机栈
}
}
最后输出结果:
java.lang.StackOverflowError
at com.haust.jvm_study.demo.Demo03.method1(Demo03.java:21)
...
...
39317// 栈帧个数,不同的虚拟机大小能存放的栈帧数量不一样
我们可以通过修改参数来指定虚拟机栈内存大小
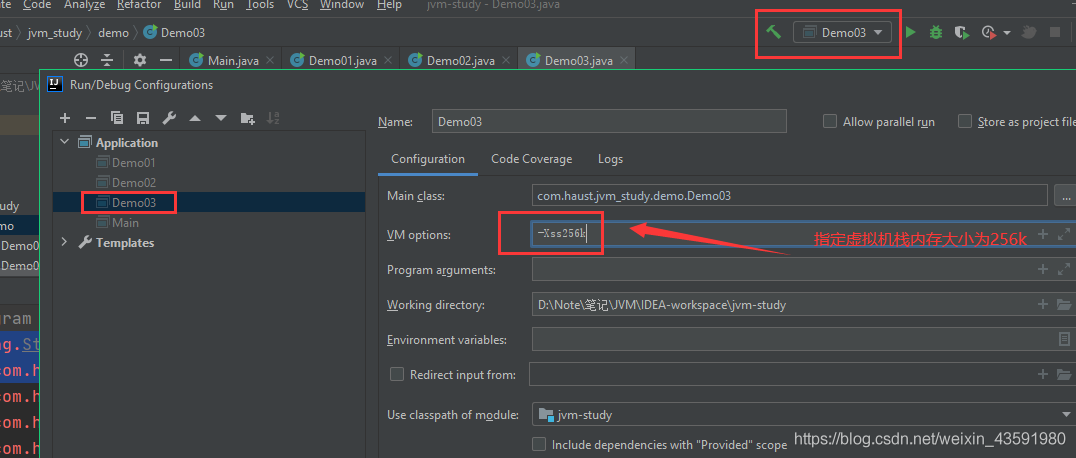
当我们将虚拟机栈内存缩小到指定的256k的时候再运行Demo03后,会得到其栈内最大栈帧数为:3816 远小于原来的39317!
案例2:
/**
* 两个类之间的循环引用问题,导致的栈溢出
*
* 解决方案:打断循环,即在员工emp 中忽略其dept属性,放置递归互相调用
*/
public class Demo04 {
public static void main(String[] args) throws JsonProcessingException {
Dept d = new Dept();
d.setName("Market");
Emp e1 = new Emp();
e1.setName("csp");
e1.setDept(d);
Emp e2 = new Emp();
e2.setName("hzw");
e2.setDept(d);
d.setEmps(Arrays.asList(e1, e2));
// 输出结果:{"name":"Market","emps":[{"name":"csp"},{"name":"hzw"}]}
ObjectMapper mapper = new ObjectMapper();// 要导入jackson包
System.out.println(mapper.writeValueAsString(d));
}
}
/**
* 员工
*/
class Emp {
private String name;
@JsonIgnore// 忽略该属性:为啥呢?我们来分析一下!
/**
* 如果我们不忽略掉员工对象中的部门属性
* System.out.println(mapper.writeValueAsString(d));
* 会出现下面的结果:
* {
* "name":"Market","emps":
* [c
* {"name":"csp",dept:{name:'xxx',emps:'...'}},
* ...
* ]
* }
* 也就是说,输出结果中,部门对象dept的json串中包含员工对象emp,
* 而员工对象emp 中又包含dept,这样互相包含就无线递归下去,json串越来越长...
* 直到栈溢出!
*/
private Dept dept;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
}
/**
* 部门
*/
class Dept {
private String name;
private List<Emp> emps;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
2.5 线程运行诊断
案例1:CPU占用过高
- Linux环境下运行某些程序的时候,可能导致CPU的占用过高,这时需要定位占用CPU过高的线程
- top命令,查看是哪个进程占用CPU过高
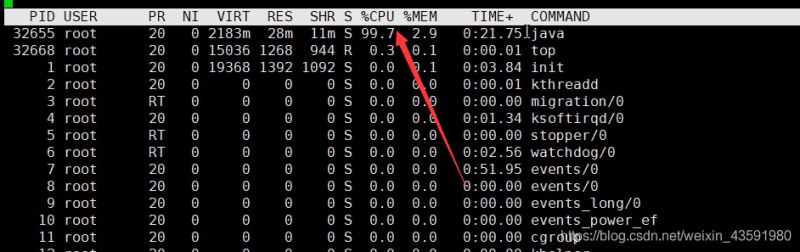
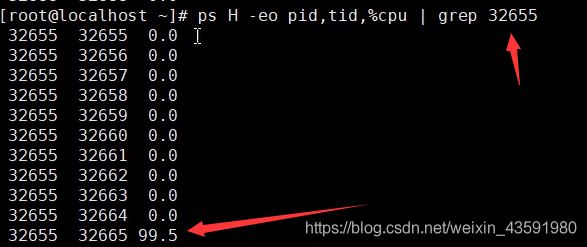
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过top查到的进程号 通过ps命令进一步查看具体是哪个线程占用CPU过高!
- jstack 进程id 通过查看进程中的线程的nid,刚才通过ps命令看到的tid来对比定位,注意jstack查找出的线程id是16进制的,需要转换
- 可以通过线程id,找到有问题的线程,进一步定位到问题代码的源码行数!

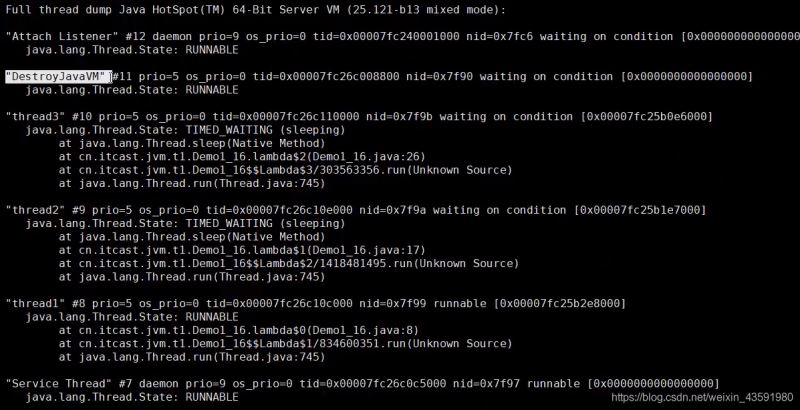
我们可以看到上图中的thread1 线程一直在运行(runnable)中,说明就是它占用了较高的CPU内存;

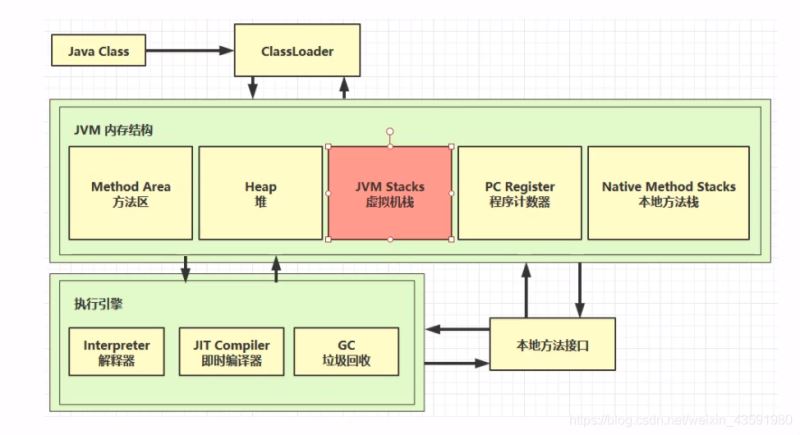
3、本地方法栈
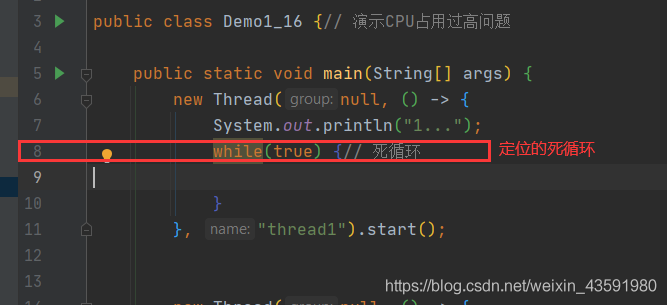
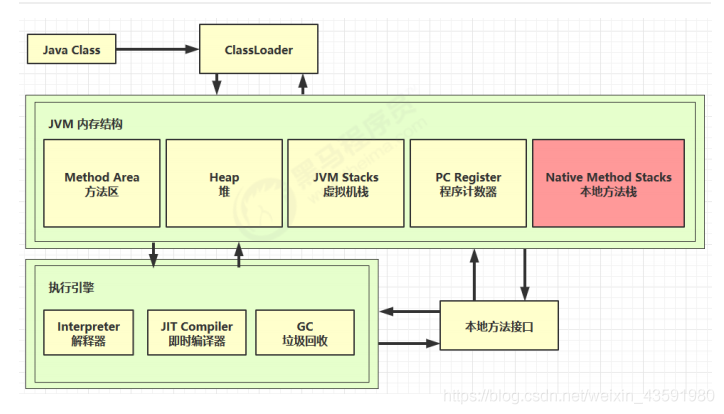
一些带有native 关键字的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法!
如图:

- 本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序,Java诞生的时候是C/C++横行的时候,要想立足,必须由调用C/C++程序,于是就在内存中专门开辟了一块区域处理标记为native的代码,它的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时加载native libraies
- 目前该方法的使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍
- 本地方法栈(Native Method Stack):(它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库)
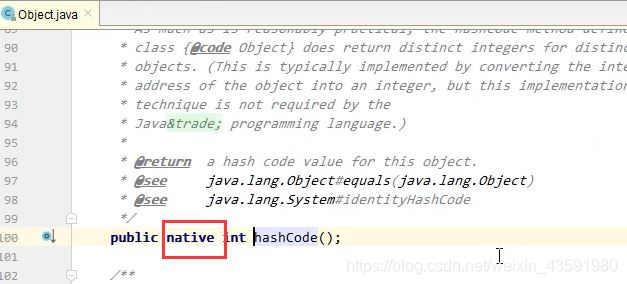
- native方法的举例: Object类中的clone wait notify hashCode 等 Unsafe类都是native方法
4、总结
这篇文章的内容就到这了,希望大家多多关注我们的其他内容!
相关推荐
-

JVM内存结构相关知识解析
最近在看< JAVA并发编程实践 >这本书,里面涉及到了 Java 内存模型,通过 Java 内存模型顺理成章的来到的 JVM 内存结构,关于 JVM 内存结构的认知还停留在上大学那会的课堂上,一直没有系统的学习这一块的知识,所以这一次我把< 深入理解Java虚拟机JVM高级特性与最佳实践 >.< Java虚拟机规范 Java SE 8版 >这两本书中关于 JVM 内存结构的部分都看了一遍,算是对 JVM 内存结构有了新的认识.JVM 内存结构是指:Java 虚拟机定义
-
了解Java虚拟机JVM的基本结构及JVM的内存溢出方式
JVM内部结构图 Java虚拟机主要分为五个区域:方法区.堆.Java栈.PC寄存器.本地方法栈.下面 来看一些关于JVM结构的重要问题. 1.哪些区域是共享的?哪些是私有的? Java栈.本地方法栈.程序计数器是随用户线程的启动和结束而建立和销毁的, 每个线程都有独立的这些区域.而方法区.堆是被整个JVM进程中的所有线程共享的. 2.方法区保存什么?会被回收吗? 方法区不是只保存的方法信息和代码,同时在一块叫做运行时常量池的子区域还 保存了Class文件中常量表中的各种符号引用,以及翻译出来的
-
JVM入门之内存结构(堆、方法区)
目录 1.堆 1.1 定义 1.2 堆的作用 1.3 特点 1.4 堆内存溢出 1.5 堆内存诊断 2.方法区 2.1 结构(1.6 对比 1.8) 2.2 内存溢出 2.3 常量池 2.4 运行时常量池 2.5 常量池与串池的关系 2.6 StringTable的位置 2.7 StringTable 垃圾回收 2.8 方法区的垃圾回收 3.直接内存 释放原理 1.堆 1.1 定义 是Java内存区域中一块用来存放对象实例的区域[几乎所有的对象实例都在这里分配内存] 通过new关键字创建的对象都
-
JVM内存结构划分实例解析
这篇文章主要介绍了JVM内存结构划分实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 数据区域划分 运行时内存区域划分:程序计数器.虚拟机栈.本地方法栈.堆.方法区 程序计数器 线程私有 通过寄存器实现 不会存在运行溢出 当前线程所执行的行号指示器,记住下一条JVM指令的执行地址 虚拟机栈 垃圾回收不涉及栈内存 栈内存是线程私有的,可以理解为线程运行需要的内存空间 栈由栈帧组成,每个栈帧代表一个方法执行时需要的内存(参数,局部变量,返回地
-
分析JVM的组成结构
目录 一.JavaSE体系 二.运行时数据区 三.程序计数器 3.1.什么是程序计数器 3.2.程序计数器有什么特点 3.3.用个例子来说明 四.虚拟机栈 4.1.局部变量表 4.2.操作数据栈 4.3.动态链接 4.4.方法出口 4.5.栈溢出 五.本地方法栈 六.方法区 七.堆 八.运行时常量池 8.1.符号引用 8.2.字面量 8.3.jvm各版本运行时常量池变化 8.4.直接内存 一.JavaSE体系 JavaSE,Java 平台标准版,为 Java EE 和 Java ME 提供了基础
-
深入理解JVM之Class类文件结构详解
本文实例讲述了深入理解JVM之Class类文件结构.分享给大家供大家参考,具体如下: 概述 我们平时在DOS界面中往往需要运行先运行javac命令,这个命令的直接结果就是产生相应的class文件,然后基于这个class文件才可以真正运行程序得到结果.自然.这是Java虚拟机的功劳,那么是不是Java虚拟机只能编译.java的源文件呢?答案是否定的.时至今日,Java虚拟机已经实现了语言无关性的特点.而实现语言无关性的基础是虚拟机和字节码的存储格式,Java虚拟机已经不和包括Java语言在内的任何
-
深入解析JVM之内存结构及字符串常量池(推荐)
前言 Java作为一种平台无关性的语言,其主要依靠于Java虚拟机--JVM,我们写好的代码会被编译成class文件,再由JVM进行加载.解析.执行,而JVM有统一的规范,所以我们不需要像C++那样需要程序员自己关注平台,大大方便了我们的开发.另外,能够运行在JVM上的并只有Java,只要能够编译生成合乎规范的class文件的语言都是可以跑在JVM上的.而作为一名Java开发,JVM是我们必须要学习了解的基础,也是通向高级及更高层次的必修课:但JVM的体系非常庞大,且术语非常多,所以初学者对此非
-
JVM 体系结构详解
JVM 是一种抽象的计算机,基于堆栈架构,它有自己的指令集和内存管理,是 Java 跨平台的依据,JVM解释执行字节码,或将字节码编译成本地代码执行.Java 虚拟机体系结构如下: Class File Class File 是平台无关的二进制文件,包含着能被JVM执行的字节码,其中多字节采用大端序,字符使用一种改进的UTF-8编码.Class文件精确的描述了一个类或接口的信息,其中包括: 常量池:数值和字符串字面常量,元数据如类名.方法名称.参数,以及各种符号引用 方法的字节码指令,参数个数,
-
JVM内存结构:程序计数器、虚拟机栈、本地方法栈
目录 一.JVM 入门介绍 JVM 定义 JVM 优势 JVM JRE JDK的比较 学习步骤 二.内存结构 整体架构 1.程序计数器(寄存器) 1.1 作用 1.2 特点 2.虚拟机栈 2.1 定义 2.2 演示 2.3 面试问题辨析 2.4 内存溢出 2.5 线程运行诊断 3.本地方法栈 4.总结 一.JVM 入门介绍 JVM 定义 Java Virtual Machine,JAVA程序的运行环境(JAVA二进制字节码的运行环境) JVM 优势 一次编写,到处运行 自动内存管理,垃圾回收机制
-
深入理解Java虚拟机 JVM 内存结构
目录 前言 JVM是什么 JVM内存结构概览 运行时数据区 程序计数器 Java虚拟机栈 本地方法栈 方法区 运行时常量池 Java堆 直接内存 前言 JVM是Java中比较难理解和掌握的一部分,也是面试中被问的比较多的,掌握好JVM底层原理有助于我们在开发中写出效率更高的代码,可以让我们面对OutOfMemoryError时不再一脸懵逼,可以用掌握的JVM知识去查找分析问题.去进行JVM的调优.去让我们的应用程序可以支持更高的并发量等......总之一句话,学好JVM很重要! JVM是什么 J
-
JVM入门之JVM内存结构内容详解
一.java代码编译执行过程 源码编译:通过Java源码编译器将Java代码编译成JVM字节码(.class文件) 类加载:通过ClassLoader及其子类来完成JVM的类加载 类执行:字节码被装入内存,进入JVM虚拟机,被解释器解释执行 注:Java平台由Java虚拟机和Java应用程序接口搭建,Java语言则是进入这个平台的通道, 用Java语言编写并编译的程序可以运行在这个平台上 二.JVM简介 1.java程序经过一次编译之后,将java代码编译为字节码也就是class文件,然
-
Java虚拟机内存结构及编码实战分享
推荐 原创 了解JVM内存结构的目的 在Java的开发过程中,因为有JVM自动内存管理机制,不再需要像在C.C++开发那样手动释放对象的内存空间,不容易出现内存泄漏和内存溢出的问题.但是,正是由于把内存管理的权利交给了JVM,一旦出现内存泄漏和内存溢出方面的问题,如果不了解JVM是如何使用内存的,不了解JVM的内存结构是什么样子的,就很难找到问题的根源,就更难以解决问题. JVM内存结构简介 在JVM所管理的内存中,大致分为以下几个运行时数据区域: 程序计数器:当前线程所执行的字节码的行号指示器
-
华为技术专家讲解JVM内存模型(收藏)
全是干货的技术号: 本文已收录在[github面试知识仓库],欢迎 star/fork: https://github.com/Wasabi1234/Java-Interview-Tutorial 内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行. JVM内存布局规定了Java在运行过程中内存申请.分配.管理的策略,保证了JVM的高效稳定运行.不同的JVM对于内存的划分方式和管理机制存在着部分差异.结合JVM虚拟机规范,来探讨经典的JVM内存布局. J
-
一篇文章带你了解JVM内存模型
目录 1. JVM介绍 1.1 什么是JVM? 1.2 JVM的优点 1.2.1 一次编写,到处运行. 1.2.2 自动内存管理,垃圾回收机制. 1.2.3 数组下标越界检查 1.2.4 多态 1.3 JVM.JRE.JDK之间的关系 1.3.1 JVM的简介 1.3.2 JRE的简介 1.3.3 JDK的简介 1.4 JVM的常见实现 1.5 JVM的内存结构图 1.5.1方法区.堆 1.5.2虚拟机栈.程序计数器.本地方法栈 1.5.3执行引擎 1.5.4 GC(垃圾回收机制) 1.5.5本
-
JVM内存管理之JAVA语言的内存管理详解
引言 内存管理一直是JAVA语言自豪与骄傲的资本,它让JAVA程序员基本上可以彻底忽略与内存管理相关的细节,只专注于业务逻辑.不过世界上不存在十全十美的好事,在带来了便利的同时,也因此引入了很多令人抓狂的内存溢出和泄露的问题. 可怕的事情还不只如此,有些使用其它语言开发的程序员,给JAVA程序员扣上了一个"不懂内存"的帽子,这着实有点让人难以接受.毕竟JAVA当中没有malloc和delete.没有析构函数.没有指针,刚开始接触JAVA的程序员们又怎么可能接触内存这一部分呢,更何况有不
-
JVM内存模型/内存空间:运行时数据区
目录 JVM内存模型/内存空间 ① 程序计数器 (Program Counter Register) ② Java虚拟机栈 (VM Stack) ③ 本地方法栈 (Native Method Stack) ④ Java堆 (Java Heap) ⑤ 方法区(Method Area) ⑥ 运行时常量池 (Running Constant Pool) [特] 直接内存 总结 JVM内存模型/内存空间 Java虚拟机JVM运行起来,就会给内存划分空间,这块空间成为运行时数据区. 运行时数据区主要划分为