使用mysql记录从url返回的http GET请求数据操作
业务场景需求及实现逻辑分析
在业务中,我们经常会碰到需要用HTTP GET请求数据的情况,比如http请求返回的结果如下所示:

那么,如果我们想将这些数据用mysql存储下来,那该怎么实现呢?
其实,调用python的httplib和MySQLdb包将会非常容易实现,httplib负责获取url的返回,MySQLdb负责对MySQL数据库进行操作。下面整理了关系逻辑图:
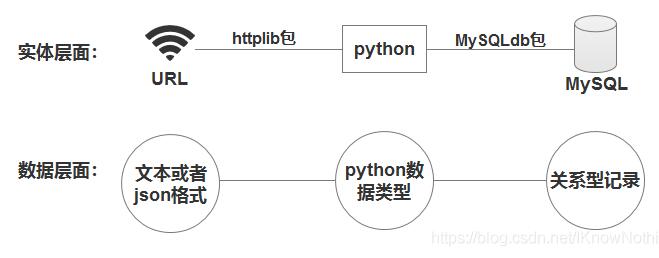
那么,我们开始代码开发:
python依赖包准备
python需要用到的包至少有如下几个,其中MySQLdb依赖包的安装可以参考python安装mysql的依赖包mysql-python
# 此为python文本编辑器界面 #!/usr/bin/python # coding=utf-8 import httplib import json import time import MySQLdb
用httplib获取url请求返回
httplib包支持如下的一些方法和函数:
url = "http://www.testtesttest.com/mobile/kit?token=yyyyyyyyy&key=tttttt&size=1" #具体的url链接
conn = httplib.HTTPConnection("www.testtesttest.com")
conn.request(method="GET", url=url) #指定GET方法,以及url对象
response = conn.getresponse() #创建response对象
res = response.read() #读取url返回的内容
# 使用json.loads方法将json解码为python对象
json_repose = json.loads(res)
data = json_repose['data']
此时,http请求返回的所有信息都存在了对象res中,因为请求返回的是json字符串,上面我们采用了json.loads方法来解析。
可以留意到,最终我们将请求返回的json内容,都存到了python的对象中里,而一旦将数据转为数组或者元组等形式储存,我们就可以用python自带的函数对其进行解析或者其他操作了。
用python解析url请求返回的json
# 这里我们定义了一个函数用于解析json
def data_list_analyze(i):
data_dict = data[i]
status = data_dict['status']
devi_id = data_dict['devi_id']
update_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(data_dict['update_time']))
actived_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(data_dict['actived_time']))
return devi_id, imei, device_type, actived_time
python连接数据库并写入数据
接下来是数据库的连接示例:
# 打开数据库连接,指定数据库ip、用户名、密码、连接的库名
db = MySQLdb.connect("192.168.xxx.xxx", "db_user", "db_password", "db_database", charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 建表sql语句
sql = """create table if not exists `gergsmart_list`(
`devi_id` varchar(255) NOT NULL COMMENT 'IMEI, //硬件设备 IMEI',
`imei` varchar(255) COMMENT 'ICCID,//硬件设备 SIM卡',
`device_type` varchar(255) COMMENT '设备类型',
`actived_time` datetime COMMENT '⾸次激活时间',
PRIMARY KEY(`devi_id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
"""
# 使用execute方法执行SQL语句,建表
cursor.execute(sql)
# 插入数据sql语句
insert_sql = "insert into `gergsmart_list` \
(devi_id,imei,device_type,actived_time) \
values (%s, %s, %s, %s,)"
从上面可以留意到,我们可以将python解析得到的对象devi_id、imei、device_type、actived_time,放入了mysql的插入语句中去,这样我们就实现了“从url获取数据,存到python对象中,再将python对象插入到mysql的记录中”这样的操作了。
总结,其实我们可以将python看作为一个中转器,接收url请求返回,并写入MySQL。而其中httplib负责了接收操作,MySQLdb负责了写入操作。
补充:mysql请求超时!延伸拓展至get post请求的区别是什么,超详细!一篇足矣解决所有!!
将数据库的连接地址从127.0.0.1改为localhost即可!亲测有效!!
查阅了很多的资料,归纳总结了get请求和post请求的区别
做了以下总结:
众所周知的是get请求的参数是直接暴露在url上面,安全性较低。post请求的参数是存放在body里面夹带过去,安全性较高一点。接下来我们看看稍微全面一点的解释
我们先看一下前辈们的解释
一、get和post请求的区别是什么:
get是从服务器上获取数据,post是向服务器传送数据。
get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。post是通过HTTPpost机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
对于get方式,服务器端用Request.QueryString获取变量的值,对于post方式,服务器端用Request.Form获取提交的数据。
get传送的数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
get安全性非常低,post安全性较高。
GET 请求可被缓存 POST 请求不会被缓存
GET 请求保留在浏览器历史记录中 POST 请求不会保留在浏览器历史记录中
GET 请求可被收藏为书签 POST 不能被收藏为书签
GET请求只能进行url编码(application/x-www-form-urlencoded)POST支持多种编码方式(application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。)
最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
接下来参考一下官方的说法是什么:
二、在w3schools中也对二者进行了区分给出了官方的答案
GET在浏览器回退时是无害的,而POST会再次提交请求。
GET产生的URL地址可以被Bookmark,而POST不可以。
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
GET请求只能进行url编码,而POST支持多种编码方式。
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
GET请求在URL中传送的参数是有长度限制的,而POST么有。
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
GET参数通过URL传递,POST放在Request body中。
GET产生一个TCP数据包;POST产生两个TCP数据包。
基于上述以及查阅的资料做一个总结
HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。 HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。
post请求和get请求都是HTTP的请求方式,本质上来说并无区别,底层实现都是基于TCP/IP协议。但是请求有各种各样的方式,于是HTTP对请求方式进行了划分和规定,于是产生了get、post处理请求的分工和区别。
此外还有搜索到另外一个区别:GET产生一个TCP数据包;POST产生两个TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
GET与POST都有自己的语义,不能随便混用。
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
综述:
“GET方式提交的数据最多只能是1024字节”,因为GET是通过URL提交数据,那么GET可提交的数据量就跟URL的长度有直接关系了。而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。注意这是限制是整个URL长度,而不仅仅是你的参数值数据长度。
理论上讲,POST是没有大小限制的,HTTP协议规范也没有进行大小限制,说“POST数据量存在80K/100K的大小限制”是不准确的,POST数据是没有限制的,起限制作用的是服务器的处理程序的处理能力。对于ASP程序,Request对象处理每个表单域时存在100K的数据长度限制。但如果使用Request.BinaryRead则没有这个限制。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python发送http请求解析返回json的实例
python发起http请求,并解析返回的json字符串的小demo,方便以后用到. #! /usr/bin/env python # -*- coding:gbk -*- import os import sys import json import urllib import urllib2 if __name__ == "__main__": query_file = sys.argv[1] query_index = 0 with open(query_file, 'r') a
-

java后台发起get请求获取响应数据
本文实例为大家分享了java后台发起get请求获取响应数据,供大家参考,具体内容如下 学习记录: 话不多说直接上代码: package com.jl.chromeTest; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLConnection; import java
-
python通过get,post方式发送http请求和接收http响应的方法
本文实例讲述了python通过get,post方式发送http请求和接收http响应的方法.分享给大家供大家参考.具体如下: 测试用CGI,名字为test.py,放在apache的cgi-bin目录下: #!/usr/bin/python import cgi def main(): print "Content-type: text/html\n" form = cgi.FieldStorage() if form.has_key("ServiceCode") a
-
使用mysql记录从url返回的http GET请求数据操作
业务场景需求及实现逻辑分析 在业务中,我们经常会碰到需要用HTTP GET请求数据的情况,比如http请求返回的结果如下所示: 那么,如果我们想将这些数据用mysql存储下来,那该怎么实现呢? 其实,调用python的httplib和MySQLdb包将会非常容易实现,httplib负责获取url的返回,MySQLdb负责对MySQL数据库进行操作.下面整理了关系逻辑图: 那么,我们开始代码开发: python依赖包准备 python需要用到的包至少有如下几个,其中MySQLdb依赖包的安装可以参
-
Vue生命周期activated之返回上一页不重新请求数据操作
activated: 英文原意:使活动.触发 在Vue的生命周期函数中,这个好像用的不是特别多?(也许只是在我的工作中这个用的不多,或者说叫几乎不用这个) 一.需求 前不久在项目中有这样一个需求: 在订单页面的地址信息栏,默认通过接口填充了一个已经设置过的一个的默认地址,现在要跳转去地址列表重新选择一个地址并回填到订单页面的地址信息位置 二.尝试 常规操作: 我们通常会将通过接口请求数据的方法放在==created== 或者 ==mounted==这两个生命周期中的一个里面调用. 但是我们知道,
-
Java调用MySQL存储过程并获得返回值的方法
本文实例讲述了Java调用MySQL存储过程并获得返回值的方法.分享给大家供大家参考.具体如下: private void empsInDept(Connection myConnect, int deptId) throws SQLException { CallableStatement cStmt = myConnect.prepareCall("{CALL sp_emps_in_dept(?)}"); cStmt.setInt(1, deptId); cStmt.execute
-
Python简单调用MySQL存储过程并获得返回值的方法
本文实例讲述了Python调用MySQL存储过程并获得返回值的方法.分享给大家供大家参考.具体实现方法如下: try: conn = MySQLdb.connect ( host = 'localhost', user = 'root', passwd = 'pass', db = 'prod', port = 3306 ) cursor1=conn.cursor() cursor1.execute("CALL error_test_proc()") cursor1.close() e
-
VB.NET调用MySQL存储过程并获得返回值的方法
本文实例讲述了VB.NET调用MySQL存储过程并获得返回值的方法.分享给大家供大家参考.具体实现方法如下: Dim myConnectionString As String = "Database=" & myDatabase & _ " ;Data Source=" & myHost & _ ";User Id=" & myUserId & ";Password=" &
-
php随机取mysql记录方法小结
本文实例总结了php随机取mysql记录方法.分享给大家供大家参考.具体分析如下: 在php中要随机取mysql记录我们可以直接使用mysql_query来执行mysql中的select rand函数获取的数据并读出来,这里就来给大家简单介绍一下. 方法一,代码如下: 复制代码 代码如下: select * from tablename order by rand() limit 1 把 limit 后面的数值改为你想随机抽取的条数,这里只取一条. 方法二,代码如下: 复制代码 代码如下: $q
-
mysql记录根据日期字段倒序输出
我们知道倒序输出是很简单的 select * from table order by id desc 直接这样就可以 那么现在的问题在于日期字段怎么来倒序输出 这里我们用到cast()来将指定的字段转换为我们需要的类型 如下是实际项目中的sql语句 select * from water where phoneNumber=@phoneNumber order by cast(date as datetime) desc 我们说学而不思则罔,我们来思考下深层次的内容. 经过查阅资料得知类型的转换
-
mysql 记录不存在时插入 记录存在则更新的实现方法
mysql 记录不存在时插入在 MySQL 中,插入(insert)一条记录很简单,但是一些特殊应用,在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,本文介绍的就是这个问题的解决方案. 问题:我创建了一个表来存放客户信息,我知道可以用 insert 语句插入信息到表中,但是怎么样才能保证不会插入重复的记录呢? 答案:可以通过使用 EXISTS 条件句防止插入重复记录. 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的
-
mysql记录耗时的sql实例详解
mysql记录耗时的sql mysql可以把耗时的sql或未使用索引的sql都记录在slow log里,供优化分析使用. 1.mysql慢查询日志启用: mysql慢查询日志对于跟踪有问题的查询非常有用,可以分析出当前程序里有很耗费资源的sql语句,那如何打开mysql的慢查询日志记录呢? mysql> show variables like 'log_slow_queries'; +------------------+-------+ | Variable_name | Value | +-
-
探讨:parse url解析URL,返回其组成部分
parse_url(PHP 4, PHP 5)parse_url - 解析 URL,返回其组成部分说明array parse_url ( string $url )本函数解析一个 URL 并返回一个关联数组,包含在 URL 中出现的各种组成部分. 本函数不是用来验证给定 URL 的合法性的,只是将其分解为下面列出的部分.不完整的 URL 也被接受,parse_url() 会尝试尽量正确地将其解析. 参数url 要解析的 URL 返回值对严重不合格的 URL,parse_url() 可能会返回 F