Java必备知识之位运算及常见进制解读
目录
- 常见几种进制?
- Java八种按位运算?
- HashMap添加元素四步曲用到的位运算?
- 前奏:HashMap如何添加一个元素?
- 第一步曲
- 第二步曲
- 第三步曲
- 第四步曲
- 终曲:为什么HashMap底层源码用这么多位运算?
您好,我是贾斯汀,欢迎又进来学习啦!

【学习背景】
学习Java的小伙伴,都知道想要提升个人技术水平,阅读JDK源码少不了,但是说实话还是有些难度的,底层源码实现的原理离不开各种常用的数据结构和算法,很多时候还会用到各种位运算,比如面试必问和工作写烂透了的HashMap,就一个put(key,value)添加元素的底层实现,就用到了各种位运算知识,不对位运算略知一二,你还真读不懂它的源码,所以本文主要对Java中的几种位运算以及常见进制的说明,还会以HashMap底层实现添加元素四部曲展开说明,希望能提高提升自己对源码的理解,也希望能帮助到有需要的小伙伴~
进入正文~
常见几种进制?

- 二进制(Binary)
数值范围0,1,满2进1
以0b或0B开头
bit比特是计算机最小存储单元,1个bit占用1个二进制位即0或1
1个byte字节有8个bit即占用8个二进制位
int整型4字节占用32个二进制位
二进制左半部分表示高位,右半部分为低位
二进制最高位为0表示正数,最高位为1表示负数
二进制原码取反得到反码,反码补1得到补码,负数使用补码表示
- 八进制(Octal)
数值范围0-7,满8进1
以数字0开头表示
- 十进制(Decimal)
数值范围0-9 ,满10进1
日常阿拉伯数字即十进制
- 十六进制(Hexadecimal)
数值范围0-9及A-F,满16进1
以0x或0X开头表示。 此处的A-F不区分大小写
Java八种按位运算?
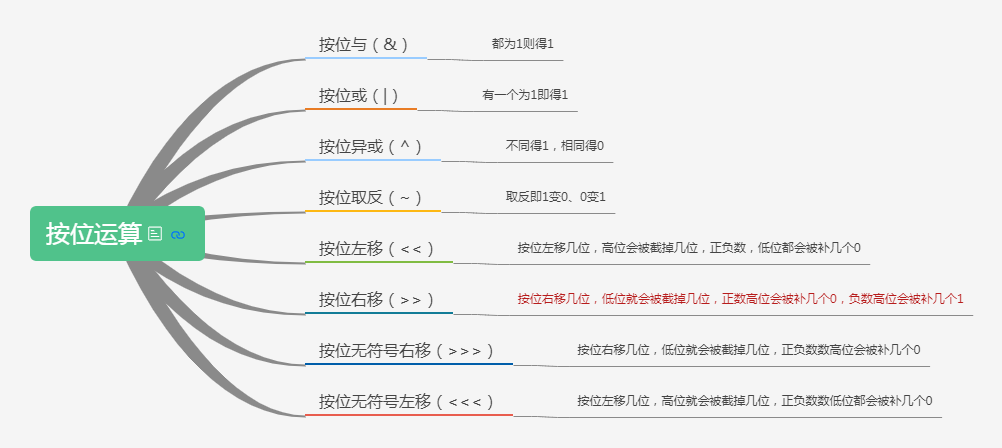
- 按位与(&)
都为1则得1
- 按位或(|)
有一个为1即得1
- 按位异或(^)
不同得1,相同得0
- 按位取反(~)
取反即1变0、0变1
- 按位左移(<<)
按位左移几位,高位会被截掉几位,正负数,低位都会被补几个0
- 按位右移(>>)
按位右移几位,低位就会被截掉几位,正数高位会被补几个0,负数高位会被补几个1
- 按位无符号右移(>>>)
按位右移几位,低位就会被截掉几位,正负数数高位会被补几个0
- 按位无符号左移(<<<)
按位左移几位,高位就会被截掉几位,正负数数低位都会被补几个0
HashMap添加元素四步曲用到的位运算?
前奏:HashMap如何添加一个元素?
HashMap底层数据结构是数组+链表,通过put(K key, V value)方法添加元素,底层四步曲如下:
- 第一步曲:根据key得到hashCode值
- 第二步曲:根据hashCode值计算出hash值
- 第三步曲:根据hash值计算出元素(key/value)最终要放在哪个数组index下标
- 第四步曲:最后根据元素(key/value)新建节点并保存到指定数组index下标位置
Java HashMap添加元素的示例代码:
HashMap<Object, Object> map = new HashMap<>();
map.put("name","Justin");
HashMap底层put(key,value)方法源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
接下来将解读底层源码用到哪些位运算,有什么奥妙之处
第一步曲
根据key得到hashCode值
可以看到hash值计算的过程就用到了^(异或)和>>>(无符号右移)两种位运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里key是字符串"name",String重写了计算字符串hashCode值的hashCode()方法,源码如下:

计算得到hashCode值为3373707
第二步曲
根据hashCode值计算出hash值
(h = key.hashCode()) ^ (h >>> 16) 即 (3373707) ^ (3373707 >>> 16)
3373707二进制表达
0000000001100110111101010001011
h >>> 16二进制表达
00000000000000000000000000110011
根据^异或运算原理即不同得1,相同得0得到3373707 ^ (3373707 >>>16)二进制结果为:
0000000001100110111101010111000
进制在线转换:http://tools.jb51.net/transcoding/hexconvert
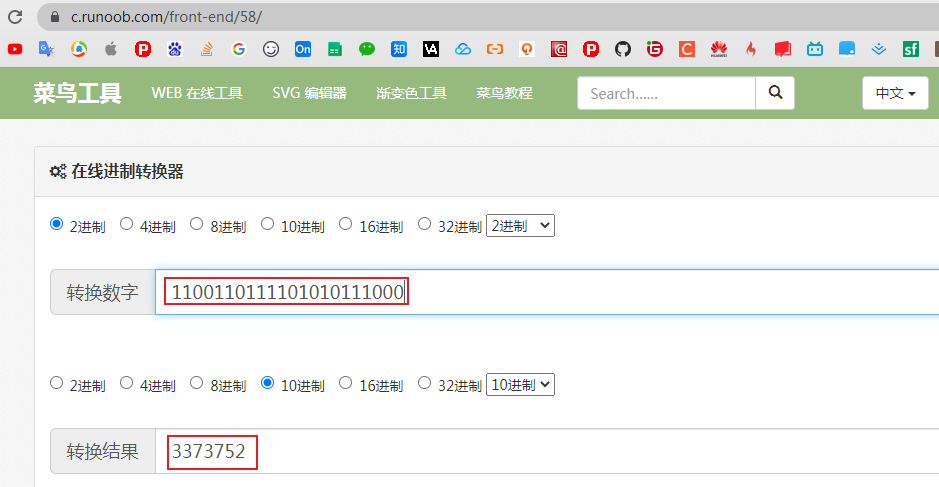
即计算key的hash值得到3373752,断点往后查看hash值刚好也是这个值
第三步曲
根据hash值计算出元素(key/value)最终要放在哪个数组index下标
公式:i = (n - 1) & hash
这里就用到了&按位与运算(都为1则得1)

公式(n - 1) & hash 的奥妙之处在于,n表示HashMap中的数组容量大小,并且刚好是16,32,64…2的次方,这种情况其实是等效于 hash % n 取模,计算出的数组index下标值一样,还能够保证不会数组下标越界
但是HashMap这里没有使用%取模,因为hash值是int整型即十进制数值,使用%取模会先将内存数据转成十进制再进行运算,多了这部分的性能开销,因此效率比较低
HashTable底层倒是用的%取模,hash值与十六进制0x7FFFFFFF做按位与运算目的是为了保证hash值始终是正数

有的小伙伴可能会问了,使用%取模计算,那这里为啥HashTable还在用,我想说的是其实也可以优化,只不过HashTable本身就是主打synchronized线程安全,也就不考虑优化%取模为位运算了

第四步曲
最后根据元素(key/value)新建节点并保存到指定数组index下标位置
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
终曲:为什么HashMap底层源码用这么多位运算?
关于位运算的使用,文中在介绍第三步曲时,也提到了HashMap计算数组下标使用%取模和位运算的问题,使用于位运算的奥妙之处在直接从内存读取数据进行计算,不需要转成十进制,如果使用%取模需要先转成十进制,有性能开销,效率比较低
HashMap底层除了文中提到的^按位异或、>>>无符号右移、&按位与位运算,其实在HashMap的扩容机制resize()中,还用到了<<左移运算
oldCap << 1

这里oldCap << 1刚好是两倍,可以总结的说一个数与n进行左移运算,结果为这个数乘以2的n次方
oldCap << 1 等值 oldCap = oldCap * (2的n次方)
同理,一个数与n进行右移运算结果为这个数除以2的n次方
oldCap >> 1 等值 oldCap = oldCap / (2的n次方)
**
到此这篇关于Java必备知识之位运算及常见进制解读的文章就介绍到这了,更多相关Java 位运算内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java 三种进制的数值常量操作
我就废话不多说了,大家还是直接看代码吧~ package cn.nxl2018; class Test{ //十进制常量赋值 void decimals(){ byte b=10; short s=10; char ch=69; int i=10; long l=10l;//l/L可加可不加 float f=10.1f;//float f=10,可以不加f将10默认转换为float类型,输出10.0.但当是小数时必须加f. float f2=10.2e3f;//可以用指数形式来表示 double
-
Java 3种方法实现进制转换
由其他进制转换为十进制比较简单,下面着重谈一谈十进制如何化为其他进制. 1.使用Java带有的方法Integer,最简单粗暴了,代码如下 //使用java提供的方法 //但仅局限于比较常用的二进制.八进制.十六进制 public static String trans1(int num, int radix) { if(radix == 2) return Integer.toBinaryString(num); else if(radix == 8) return Integer.toOcta
-

Java基础之位运算知识总结
一.位运算的分类与展现效果 java位运算可以分为左移和右移,其中右移还有无符号右移. java只对整型位移,可以分为int体系和long体系.int体系包括(byte, short, int, char),long体系只包含long.int体系中进行位运算时,除int类型外都会先转换为int再进行运算.. 无符号右移指的是,向右移动时,左边补位的是0. 一般来说,右移左移常用作乘2n 或者除以2n.(右移除以2n,左移乘以2n) int i1 = 4; int r1 = i1 >> 2;
-
Java 位运算符>>与>>>区别案例详解
下图是java教程中对于>>和>>>区别的解释,但是介绍的并不详细,因为这两种运算符是以补码二进制进行运算的. 1.学习过计算机原理的都知道,数字是以补码的形式在计算机中存储的,那么源码,反码,补码之间的关系是如下所示: **正整数**的原码.反码和补码都一样: **负数部分**: 1.原码和反码的相互转换:符号位不变,数值位按位取反 2.原码和补码的相互转换:符号位不变,数值位按位取反,末位再加1 3.已知补码,求原码的负数的补码:符号位和数值位都取反,末位再加1 2.了解
-
JAVA位运算的知识点总结
一.在计算机中数据是如何进行计算的? 1.1:java中的byte型数据取值范围 我们最开始学习java的时候知道,byte类型的数据占了8个bit位,每个位上或0或1,左边第一位表示符号位,符号位如果为1表示负数,为0则表示正数,因此要推算byte的取值范围,只需要让数值位每一位上都等于1即可. 我们来用我们的常规思维来分析下byte类型的取值范围: 图1 如果按照这种思路来推算,七个1的二进制数转换为十进制是127,算上符号位,取值范围应为:-127~+127,但事实上我们知道,byte的取
-
Java实现任意进制转换
本文实例为大家分享了Java实现任意进制转换的具体代码,供大家参考,具体内容如下 问题描述 编写程序实现任意进制间的相互转换 (一).进制转换思想 1.先把任意进制转化为十进制 2.再把十进制转化为任意进制 3.本算法结合了十以下进制利用公式转换以及十以上进制调用函数转换 (二).问题分析 1.输入当前数进制 输入当前进制 m ,且保证 m>1 public static void main (String[] args){ int l,m,n; String l16; Scanner sc =
-
Java必备知识之位运算及常见进制解读
目录 常见几种进制? Java八种按位运算? HashMap添加元素四步曲用到的位运算? 前奏:HashMap如何添加一个元素? 第一步曲 第二步曲 第三步曲 第四步曲 终曲:为什么HashMap底层源码用这么多位运算? 您好,我是贾斯汀,欢迎又进来学习啦! [学习背景] 学习Java的小伙伴,都知道想要提升个人技术水平,阅读JDK源码少不了,但是说实话还是有些难度的,底层源码实现的原理离不开各种常用的数据结构和算法,很多时候还会用到各种位运算,比如面试必问和工作写烂透了的HashMap,就一个
-
浅谈java中的移动位运算:,>>>
1. 概念 << 左移运算符,左移是在后面补0, num << 1,相当于num乘以2 >> 右移运算符, 右移是在前面补1或0,num >> 1, 相当于num除以2 >>> 无符号右移,是在前面补0, 忽略符号位,空位都以0补齐 另外, 不论是左右还是右移32位,相当于不移动,还是原值. 实际上 在java虚拟机执行这句代码的时候如下这样执行的: 5>>(n%32)--->结果 你这里n=32 :所以5>>
-
C#实现将汉字转化为2位大写的16进制Unicode的方法
本文实例讲述了C#实现将汉字转化为2位大写的16进制Unicode的方法.分享给大家供大家参考.具体实现方法如下: 说明: str.ToString("x") : 转为1位16进制小写 str.ToString("X") : 转为1位16进制大写 str.ToString("X2"):转为2位16进制大写 具体代码如下: 复制代码 代码如下: publicstaticstring StringToUnicode16(string text, st
-
轻松实现C/C++各种常见进制相互转换
其它进制转为十进制 在实现这个需求之前,先简单介绍一个c标准库中的一个函数: long strtol( const char *str, char **str_end, int base); 参数详细说明请 参考文档 注意:这个函数在c标准库stdlib中,所以需要 #include<cstdlib> 用法参考 #include <stdio.h> #include <errno.h> #include <stdlib.h> int main(void) {
-
python中常见进制之间的转换方式
目录 1. 很多情况下需要进行不同进制之间的转换 下面的表格反应了常见进制之间的转换 2. 第二种是使用format函数进行转换 3. 手动转化 10进制转换为其他进制代码 其他的进制转为10进制代码 1. 很多情况下需要进行不同进制之间的转换 其中比较常用到的是python的内置函数进行进制的转换,一般使用内置函数进行转换的时候是先将控制台输入的字符串或者是自定义的字符串先转换为10进制然后将10进制转换为其他的进制,常见的是二进制.十进制.八进制.十六进制之间的转换,其中遵循一个原则是: 其
-
java发送heartbeat心跳包(byte转16进制)
复制代码 代码如下: package com.jxy.web; import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.io.UnsupportedEncodingException;import java.net.Socket;import java.net.UnknownHostException; import com.jxy.tools.MyByte; pu
-
Java解析DICOM图之如何获得16进制数据详解
前言 在最近的一个项目需要用JAVA来解析DICOM图片,DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线,CT,核磁共振,超声等),并且在眼科和牙科等其它医学领域得到越来越深入广泛的应用,在实现中遇到一些问题下面做一些记录. 首先找一个*.dcm文件.用编辑器打开可以看到如下界面.我是用的编辑器是UltraEdit 红字标注的是字节码的标注,前面8行代码是文件的头信息一般没用.从第九行开始的四个十六进制数"44,49,43,4D"是很重要的.用ASCll码解释就
-
Java位运算知识点详解
在日常的Java开发中,位运算使用的不多,使用的更多的是算数运算(+.-.*./.%).关系运算(<.>.<=.>=.==.!=)和逻辑运算(&&.||.!),所以相对来说对位运算不是那么熟悉,本文将以Java的位运算来详细介绍下位运算及其应用. 1. 位运算起源 位运算起源于C语言的低级操作,Java的设计初衷是嵌入到电视机顶盒内,所以这种低级操作方式被保留下来.所谓的低级操作,是因为位运算的操作对象是二进制位,但是这种低级操作对计算机而言是非常简单直接,友好高效
-
浅析关于PHP位运算的简单权限设计
1.写在最前面最近想写一个简单的关于权限处理的东西,之前我也了解过用二进制数的位运算可以出色地完成这个任务.关于二进制数的位运算,常见的就是"或.与.非"这三种简单运算了,当然,我也查看了下PHP手册,还有"异或.左移.右移"这三个运算.记得上初中时数学老师就开始唠叨个不停了,在此我也不想对此运算再作额外的说明,直接进入正题. 2.如何定义权限将权限按照2的N次方来定义值,依次类推.为什么要这样子定义呐?这样子定义保证了每个权限值(二进制)中只有一个1,而它恰好对应
-
Golang 运算符及位运算详解
什么是运算符? 运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是"+". 在vb2005中运算符大致可以分为5种类型:算术运算符.位运算符. 关系运算符.赋值运算符.逻辑运算符. 算数运算符 运算符 描述 + 相加 - 相减 * 相乘 / 相除 % 求余 注意: ++(自增)和--(自减)在Go语言中是单独的语句,并不是运算符. func main() { a, b := 3,4 fmt.Printf("a 加 b