C语言非递归算法解决快速排序与归并排序产生的栈溢出
目录
- 1、栈溢出原因和递归的基本认识
- 2、快速排序(非递归实现)
- 3、归并排序(非递归实现)
建议还不理解快速排序和归并排序的小伙伴们可以先去看我上一篇博客哦!C语言超详细讲解排序算法下篇
1、栈溢出原因和递归的基本认识
我们先简单来了解下内存分布结构:

栈区:用于存放地址、临时变量等;
堆区:程序运行期间动态分配所使用的场景;
静态区:存放全局变量和静态变量,具体还分为 .bss段和.data段;
.bss段:存放未初始化的和初始化为0的全局变量或者静态变量;
.data段:初始化不为0的全局变量或者静态变量;
常量区:存放常量(比如比变量名字,非0的初始化值,const常量,字符串等),只读;
代码区:存放代码的位置,只读;
我们再来看这样的一串代码运行的结果:
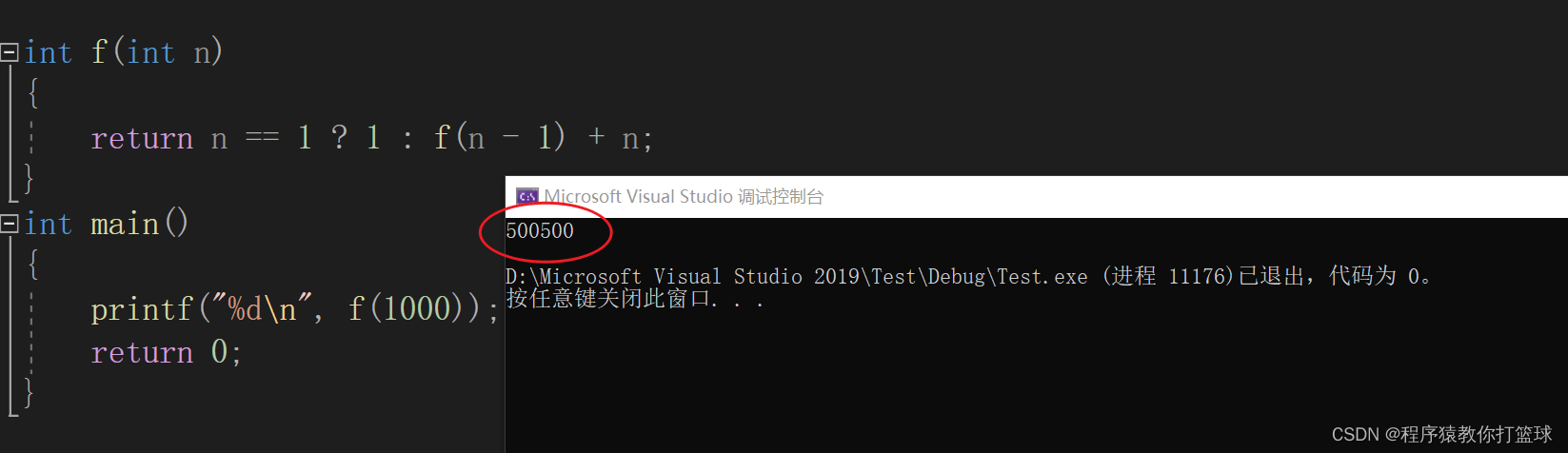
这是一个累加求和的递归函数,当我们发现累加求和到1000递归仍然能正常执行,我们接着改为10000看看是否还能正常运行?

我们可以看到,当数值达到10000的时候程序已经崩了,并不会显示任何错误,当我们进入调试可以发现报错显示栈溢出,那为什么会造成栈溢出呢,我们接着往下看!
递归的基本认识:
递归本质也是函数调用,是函数调用,本质就要形成和释放栈帧
调用函数是有成本的,这个成本就体现在形成和释放栈帧上:时间+空间
所以,递归就是不断形成栈帧的过程
内存和CPU的资源是有限的,也就决定了,合理的递归是绝对不能无限递归下去,如果递归调用深度太深,这样有可能导致一 直开辟栈空间,最终产生栈空间耗尽的情况,这样的现象我们称为栈溢出!
既然使用递归极端情况下会出现栈溢出的问题,那么我们就用非递归的方式来实现快速排序和归并排序!
2、快速排序(非递归实现)
快速排序非递归实现思想:
首先我们可以借助数据结构的栈来完成,遵循栈的后进先出,我们可以先入右再入左,然后使用我们上一期讲的三个方法中的其中一个方法,这里我们选择挖坑法,使用挖坑法我们可以看作成两个区间也就是: [left, keyIndex - 1] 和 [keyIndex + 1, right],如果区间存在我们接着入栈,如此循环直到栈为空,则排序结束!
图解见下:

代码实现如下:
//挖坑法 - 升序
int PartSort(int* a, int left, int right)
{
int begin = left;
int end = right;
int key = a[begin];
int pivot = begin;
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
pivot = begin;//当begin与end相遇,随便把begin和end的值给pivot
a[pivot] = key;
return pivot;
}
void QuickSortNonR(int* a, int n)
{
Stack st;
StackInit(&st);//初始化栈
StackPush(&st, n - 1);//入数组最后一个元素下标
StackPush(&st, 0);//入数组第一个元素下标
while (!StackEmpty(&st))//当栈不为空我们就进入循环
{
int left = StackTop(&st);//取出栈顶元素给left
StackPop(&st);//出栈 - 删除栈顶元素
int right = StackTop(&st);
StackPop(&st);
int keyIndex = PartSort(a, left, right);//使用挖坑法区间排序
//[left, keyIndex - 1] keyIndex [keyIndex + 1, right] - 分成子区间
if (keyIndex + 1 < right)//因栈后进先出的特性,所以先入右区间
{
StackPush(&st, right);
StackPush(&st, keyIndex + 1);
}
if (left < keyIndex - 1)
{
StackPush(&st, keyIndex - 1);
StackPush(&st, left);
}
}
StackDestory(&st);//销毁栈
}
3、归并排序(非递归实现)
归并排序非递归实现思想:
上期我们知道归并需要开辟一个数组,并且使用分治的算法来实现归并排序,而非递归版本我们的思路也是差不多,先让他们一个一个归并,然后两个两个归并,再接着四个四个一起归并,具体图解见下:

代码实现如下:
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc:");
return;
}
int gap = 1;//gap为每组数据的个数,每次翻倍
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//可以看成 [i, i + gap - 1] [i + gap, i + 2 * gap - 1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//归并过程中右半区间有可能不存在!
if (begin2 >= n)
break;
//归并过程中右半区间越界了,就修正下
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//拷贝进去
for (int j = i; j <= end2; ++j)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
}
本期到这里就结束了,相信你们已经对非递归快速排序和归并排序已经很了解了,非递归这两个在校招中经常会考,加油把!
gitee(码云):Mercury. (zzwlwp) - Gitee.com
到此这篇关于C语言非递归算法解决快速排序与归并排序产生的栈溢出的文章就介绍到这了,更多相关C语言 栈溢出内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言之快速排序案例详解
快速排序:是对冒泡排序算法的一种改进. 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 例如有一个数字序列: 5 0 1 6 8 2 3 4 9 7 对其进行快速排序变为:0 1 2 3 4 5 6 7 8 9 思路如下:首先将要排序的序列的首个数字5定位比较数,这是一个参考对象! 然后的方法很简单:分别从序列的两端进行比较.先
-
C语言递归实现归并排序详解
归并排序递归实现还是比较难理解的,感觉涉及递归一般理解起来都会比较有难度吧,但是看了b站视频,然后照着打下来,然后自己写了点注释,就发现不知不觉都大概懂了. 这里的归并讲的是升序排序 归并排序思路大概就是:先划分数组,将数组划分为左右半区,分成的左右半区,各自再划分左右半区,一直划分,直到最后左右半区的元素都为一个时,开始合并,因为都划分为一个元素了,那么此时两个元素的排序就非常简单了,只需要比较大小就可以排序了,那么回溯上去会发现每组都是两两有序了,那么直接再依次比较两组之间的排头元素即可,取
-
举例讲解C语言对归并排序算法的基础使用
基础概念 百度百科是这么描述归并排序的: 归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作. 设有数列 {6,202,100,301,38,8,1} 初始状态: [6] [202] [100] [301] [38] [8] [1] 比较次数 i=1 [6 202 ] [ 100 301] [ 8 38] [ 1 ] 3 i=2 [ 6 100 202 301 ] [ 1 8 38 ] 4 i=3 [ 1 6 8 38 100 202 301 ] 4 总计: 1
-
C语言实现快速排序
快速排序算法是一种分治排序算法.它将数组划分为两个部分,然后分别对两个部分进行排序.我们将看到,划分的准确位置取决于输入数组中元素的初始位置.关键在于划分过程,它重排数组,使得以下三个条件成立:(i)对于某个i,a[i]在最终位置上 (ii)a[left],...,a[i-1]中的元素都比a[i]小 (iii)a[i+1],...a[right]中的元素都比a[i]大.我们通过划分来完成排序,然后递归地应用该方法处理子数组. 我们使用一般策略来实现划分.首先,我们任选一个a[right]作为划分
-
C语言开发之归并排序详解及实例
C语言归并排序 即将两个都升序(或降序)排列的数据序列合并成一个仍按原序排列的序列. 上代码: #include <stdio.h> #include <stdlib.h> #define m 6 #define n 4 int main() { int a[m]={-3,6,19,26,68,100} ,b[n]={8,10,12,22}; int i,j,k,c[m+n]; int l ; i=j=k=0; printf("a数组的元素:\n"); for
-
C语言下快速排序(挖坑法)详解
目录 全部代码如下 挖坑法--> 代码讲解--> 总结 全部代码如下 #include <stdio.h> void evaluation(int *x,int b)//赋值函数 { *x = b; } void Compare(int arr[],int first,int last) { int one = first;//数列第一个元素下标 int end = last;//数列最后一个元素下标 int key = arr[one];//创建一个坑 //判断是否为一个元素 i
-
C语言 实现归并排序算法
C语言 实现归并排序算法 归并排序(Merge sort)是创建在归并操作上的一种有效的排序算法.该算法是采用分治法(Divide and Conquer)的一个非常典型的应用. 一个归并排序的例子:对一个随机点的链表进行排序 算法描述 归并操作的过程如下: 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列 设定两个指针,最初位置分别为两个已经排序序列的起始位置 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置 重复步骤3直到某一指针到达序列尾
-
C语言简单实现快速排序
快速排序是一种不稳定排序,它的时间复杂度为O(n·lgn),最坏情况为O(n2):空间复杂度为O(n·lgn). 这种排序方式是对于冒泡排序的一种改进,它采用分治模式,将一趟排序的数据分割成独立的两部分,其中一组数据的每个值都小于另一组.每一趟在进行分类的同时实现排序. 其中每一趟的模式通过设置key当基准元素,key的选择可以是数据的第一个,也可以是数据的最后一个.这里以每次选取数据的第一个为例: 具体代码实现: #include<stdio.h> #define N 6 int fun(i
-
C语言非递归算法解决快速排序与归并排序产生的栈溢出
目录 1.栈溢出原因和递归的基本认识 2.快速排序(非递归实现) 3.归并排序(非递归实现) 建议还不理解快速排序和归并排序的小伙伴们可以先去看我上一篇博客哦!C语言超详细讲解排序算法下篇 1.栈溢出原因和递归的基本认识 我们先简单来了解下内存分布结构: 栈区:用于存放地址.临时变量等: 堆区:程序运行期间动态分配所使用的场景: 静态区
-
易语言非递归算法遍历目录的代码示例
非递归算法遍历目录 .版本 2 .支持库 shell .支持库 EDataStructure .支持库 iext .程序集 窗口程序集1 .子程序 _按钮_浏览_被单击 编辑框_目录.内容 = 浏览文件夹 ("选择目录:", 假) .子程序 枚举文件 .参数 目录, 文本型 .局部变量 队列, 队列 .局部变量 节点, 节点 .局部变量 节点1, 节点 .局部变量 路径, 文本型 .局部变量 文件夹名称, 文本型 .局部变量 文件名, 文本型 .局部变量 文件数目, 整数型 节点.加入
-
PHP基于递归算法解决兔子生兔子问题
本文实例讲述了PHP基于递归算法解决兔子生兔子问题.分享给大家供大家参考,具体如下: 接到面试通知辗转反侧,一直在默念明天改如何介绍自己的项目经验等. 早早的起床,洗漱,把自己的总结的问题自问自答了一些. 匆匆吃了早饭,挤进让人面目狰狞的地铁,此时什么都不顾,只盼着赶紧下地铁.终于提前半小时到了面试地点,再次拿出准备的问题看了几眼,还剩15分钟上去.跟着人力填了表格,然后给了我一个算法题. 如下:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都
-
C语言植物大战数据结构快速排序图文示例
目录 快速排序 一.经典1962年Hoare法 1.单趟排序 2.递归左半区间和右半区间 3.代码实现 二.填坑法(了解) 1.单趟思路 2.代码实现 三.双指针法(最佳方法) 1.单趟排序 2.具体思路 3.代码递归图 4.代码实现 四.三数取中优化(最终方案) 1.三数取中 2.代码实现(最终代码) 五.时间复杂度(重点) 1.最好情况下 2.最坏情况下 3.空间复杂度 六.非递归写法 1.栈模拟递归快排 2.队列实现快排 浅浅总结下 “田家少闲月,五月人倍忙”“夜来南风起,小麦覆陇黄” C
-
如何利用C语言位运算解决只出现一次的数字
解题所需要的C语言基础知识 hello!从现在开始就进入本题解的正式内容了.首先给大家用图解的方式介绍3个C语言位运算的基本操作符 & | ^ 这些知识对下面的解题都非常重要,一定要熟练掌握,不然等会会有一种"我在哪,我是谁我在干什么"的感觉. 只出现一次的数字I 题目描述 只出现一次的数字 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次.找出那个只出现了一次的元素. 说明: 你的算法应该具有线性时间复杂度. 你可以不使用额外空间来实现吗? 示例 1:
-
C语言非递归后序遍历二叉树
本文实例为大家分享了C语言非递归后序遍历二叉树的具体代码,供大家参考,具体内容如下 法一:实现思路:一个栈 先按 根->右子树->左子树的顺序访问二叉树.访问时不输出.另一个栈存入前一个栈只进栈的结点. 最后输出后一个栈的结点数据. #include<stdio.h> #include<stdlib.h> typedef struct TreeNode{ char element; struct TreeNode *left,*right; }Tree,*BTree;
-
C++基于递归算法解决汉诺塔问题与树的遍历功能示例
本文实例讲述了C++基于递归算法解决汉诺塔问题与树的遍历功能.分享给大家供大家参考,具体如下: 递归是把问题转化为规模缩小的同类问题,然后迭代调用函数(或过程)求得问题的解.递归函数就是直接或间接调用自身的函数. 递归两要素:递归关系和递归边界(终止条件),递归关系确定了迭代的层次结构,需要深入了解并分解问题:终止条件保证了程序的有穷性. 递归的应用有很多,常见的包括:阶乘运算.斐波那契数列.汉诺塔.数的遍历,还有大名鼎鼎的快排等等.理论上,递归问题都可以由多层循环来实现.递归的每次调用都会消耗
-
C++使用递归和非递归算法实现的二叉树叶子节点个数计算方法
本文实例讲述了C++使用递归和非递归算法实现的二叉树叶子节点个数计算方法.分享给大家供大家参考,具体如下: /*求二叉树叶子节点个数 -- 采用递归和非递归方法 经调试可运行源码及分析如下: ***/ #include <stdlib.h> #include <iostream> #include <stack> using std::cout; using std::cin; using std::endl; using std::stack; /*二叉树结点定义*/
-
二叉树先序遍历的非递归算法具体实现
在前面一文,说过二叉树的递归遍历算法(二叉树先根(先序)遍历的改进),此文主要讲二叉树的非递归算法,采用栈结构 总结先根遍历得到的非递归算法思想如下: 1)入栈,主要是先头结点入栈,然后visit此结点 2)while,循环遍历当前结点,直至左孩子没有结点 3)if结点的右孩子为真,转入1)继续遍历,否则退出当前结点转入父母结点遍历转入1) 先看符合此思想的算法: 复制代码 代码如下: int PreOrderTraverseNonRecursiveEx(const BiTree &T, int
-
C#用递归算法解决八皇后问题
1.引子 中国有一句古话,叫做"不撞南墙不回头",生动的说明了一个人的固执,有点贬义,但是在软件编程中,这种思路确是一种解决问题最简单的算法,它通过一种类似于蛮干的思路,一步一步地往前走,每走一步都更靠近目标结果一些,直到遇到障碍物,我们才考虑往回走.然后再继续尝试向前.通过这样的波浪式前进方法,最终达到目的地.当然整个过程需要很多往返,这样的前进方式,效率比较低下. 2.适用范围 适用于那些不存在简明的数学模型以阐明问题的本质,或者存在数学模型,但是难于实现的问题. 3.应用场景 在