Apache Hudi数据布局黑科技降低一半查询时间
目录
- 1. 背景
- 2. Clustering架构
- 2.1 调度Clustering
- 2.2 运行Clustering
- 2.3 Clustering配置
- 3. 表查询性能
- 3.1 进行Clustering之前
- 3.2 进行Clustering之后
- 4. 总结

1. 背景
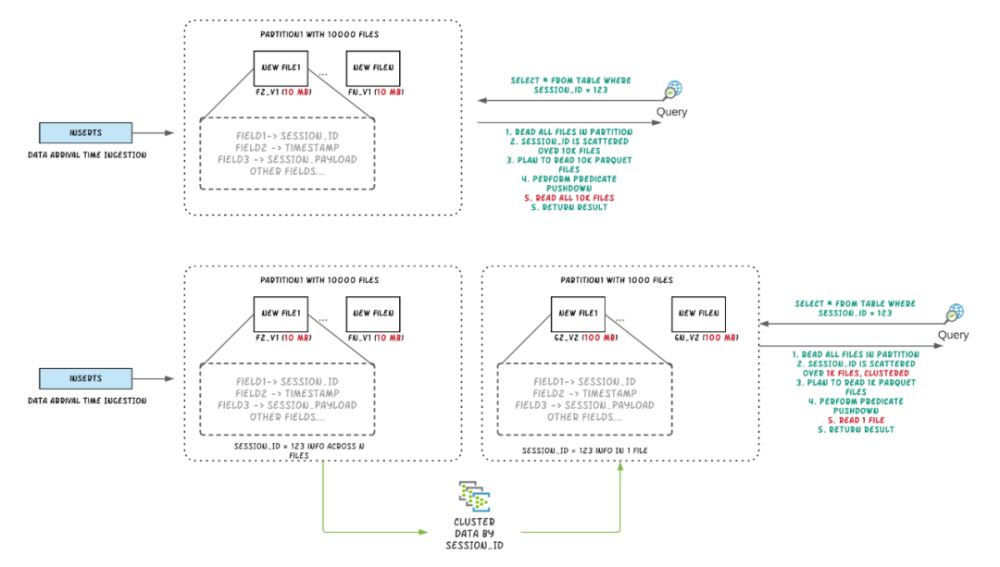
Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频繁的数据放在一起时,查询引擎的性能会更好,大多数系统都倾向于支持独立的优化来提高性能,以解决未优化的数据布局的限制。本博客介绍了一种称为Clustering[RFC-19]的服务,该服务可重新组织数据以提高查询性能,也不会影响摄取速度。
2. Clustering架构
Hudi通过其写入客户端API提供了不同的操作,如insert/upsert/bulk_insert来将数据写入Hudi表。为了能够在文件大小和摄取速度之间进行权衡,Hudi提供了一个hoodie.parquet.small.file.limit配置来设置最小文件大小。用户可以将该配置设置为0以强制新数据写入新的文件组,或设置为更高的值以确保新数据被"填充"到现有小的文件组中,直到达到指定大小为止,但其会增加摄取延迟。
为能够支持快速摄取的同时不影响查询性能,我们引入了Clustering服务来重写数据以优化Hudi数据湖文件的布局。
Clustering服务可以异步或同步运行,Clustering会添加了一种新的REPLACE操作类型,该操作类型将在Hudi元数据时间轴中标记Clustering操作。
总体而言Clustering分为两个部分:
•调度Clustering:使用可插拔的Clustering策略创建Clustering计划。•执行Clustering:使用执行策略处理计划以创建新文件并替换旧文件。
2.1 调度Clustering
调度Clustering会有如下步骤
•识别符合Clustering条件的文件:根据所选的Clustering策略,调度逻辑将识别符合Clustering条件的文件。•根据特定条件对符合Clustering条件的文件进行分组。每个组的数据大小应为targetFileSize的倍数。分组是计划中定义的"策略"的一部分。此外还有一个选项可以限制组大小,以改善并行性并避免混排大量数据。•最后将Clustering计划以avro元数据格式保存到时间线。
2.2 运行Clustering
•读取Clustering计划,并获得clusteringGroups,其标记了需要进行Clustering的文件组。•对于每个组使用strategyParams实例化适当的策略类(例如:sortColumns),然后应用该策略重写数据。•创建一个REPLACE提交,并更新HoodieReplaceCommitMetadata中的元数据。
Clustering服务基于Hudi的MVCC设计,允许继续插入新数据,而Clustering操作在后台运行以重新格式化数据布局,从而确保并发读写者之间的快照隔离。
注意:现在对表进行Clustering时还不支持更新,将来会支持并发更新。
2.3 Clustering配置
使用Spark可以轻松设置内联Clustering,参考如下示例
import org.apache.hudi.QuickstartUtils._</code><code>import scala.collection.JavaConversions._</code><code>import org.apache.spark.sql.SaveMode._</code><code>import org.apache.hudi.DataSourceReadOptions._</code><code>import org.apache.hudi.DataSourceWriteOptions._</code><code>import org.apache.hudi.config.HoodieWriteConfig._</code><code>val df = //generate data frame</code><code>df.write.format("org.apache.hudi").</code><code> options(getQuickstartWriteConfigs).</code><code> option(PRECOMBINE_FIELD_OPT_KEY, "ts").</code><code> option(RECORDKEY_FIELD_OPT_KEY, "uuid").</code><code> option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").</code><code> option(TABLE_NAME, "tableName").</code><code> option("hoodie.parquet.small.file.limit", "0").</code><code> option("hoodie.clustering.inline", "true").</code><code> option("hoodie.clustering.inline.max.commits", "4").</code><code> option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").</code><code> option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").</code><code> option("hoodie.clustering.plan.strategy.sort.columns", "column1,column2"). //optional, if sorting is needed as part of rewriting data</code><code> mode(Append).</code><code> save("dfs://location");
对于设置更高级的异步Clustering管道,参考此处示例。
3. 表查询性能
我们使用生产环境表的一个分区创建了一个数据集,该表具有约2000万条记录,约200GB,数据集具有多个session_id的行。用户始终使用会话谓词查询数据,单个会话的数据会分布在多个数据文件中,因为数据摄取会根据到达时间对数据进行分组。下面实验表明通过对会话进行Clustering可以改善数据局部性并将查询执行时间减少50%以上。
查询SQL如下
spark.sql("select * from table where session_id=123")
3.1 进行Clustering之前
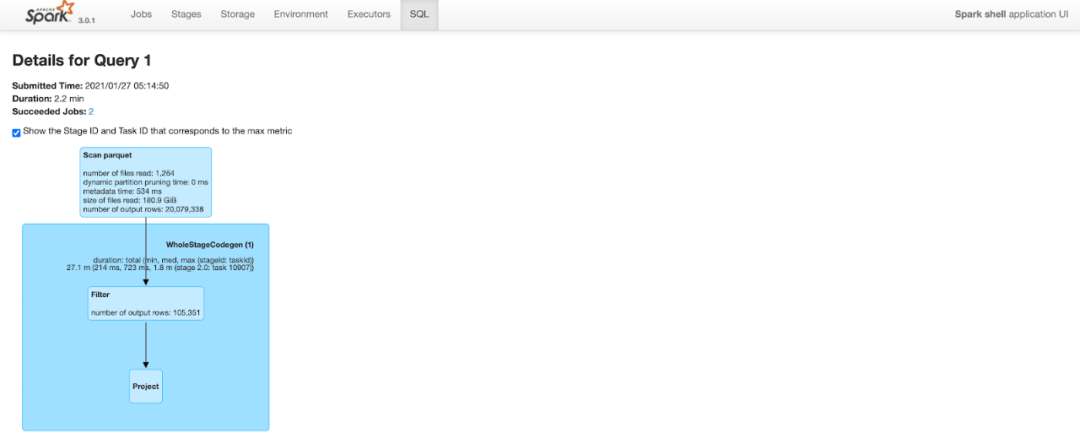
查询花费了2.2分钟。请注意查询计划的"扫描parquet"部分中的输出行数包括表中的所有2000W行。
3.2 进行Clustering之后
查询计划与上面类似,但由于改进了数据局部性和谓词下推,Spark可以修剪很多行。进行Clustering后,相同的查询在扫描parquet文件时仅输出11万行(2000万行中的),这将查询时间从2.2分钟减少到不到一分钟。

下表总结了使用Spark3运行的实验对查询性能的改进
| Table State | Query runtime | Num Records Processed | Num files on disk | Size of each file |
| Unclustered | 130,673 ms | ~20M | 13642 | ~150 MB |
| Clustered | 55,963 ms | ~110K | 294 | ~600 MB |
Clustering后查询运行时间减少了60%,在其他样本数据集上也观察到了类似的结果,请参阅示例查询计划和RFC-19性能评估上的更多详细信息。
我们希望大型表能够大幅度提高速度,与上面的示例不同,查询运行时间几乎完全由实际I/O而不是查询计划决定。
4. 总结
使用Clustering,我们可以通过以下方式提高查询性能:
利用空间填充曲线之类的概念来适应数据湖布局并减少查询读取的数据量。
将小文件合并成较大的文件以减少查询引擎需要扫描的文件总数。
Clustering使得大数据进行流处理,摄取可以写入小文件以满足流处理的延迟要求,可以在后台使用Clustering将这些小文件重写成较大的文件并减少文件数。
除此之外,Clustering框架还提供了根据特定要求异步重写数据的灵活性,我们预见到许多其他用例将采用带有自定义可插拔策略的Clustering框架来按需管理数据湖数据,如可以通过Clustering解决如下一些用例:
重写数据并加密数据。
从表中修剪未使用的列并减少存储空间。
以上就是Apache Hudi数据布局黑科技降低一半查询时间的详细内容,更多关于Apache Hudi数据布局查询的资料请关注我们其它相关文章!
相关推荐
-

Apache Calcite进行SQL解析(java代码实例)
背景 当一个项目分了很多模块,很多个服务的时候,一些公共的配置就需要统一管理了,于是就有了元数据驱动! 简介 什么是Calcite?是一款开源SQL解析工具, 可以将各种SQL语句解析成抽象语法树AST(Abstract Syntax Tree), 之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中.Calcite能做啥? SQL 解析 SQL 校验 查询优化 SQL 生成器 数据连接 实例 今天主要是贴出一个java代码实例,实现了:解析SQL语句中的表名上代码:SQL语
-
使用 Apache 反向代理的设置技巧
Apache 是一个多功能的 Web 服务器,它提供了完整的支持功能,其中一些是通过扩展来实现的.在本文中,我们将使用该mod_proxy模块将 Apache 配置为反向代理角色. 虽然 Apache 可能不是您作为反向代理的首选,但 NGINX 等更现代的替代方案往往会引起注意,mod_proxy但对于已经在运行 Apache 并且现在需要将流量路由到另一个服务的服务器很有用.您可以设置 Apache 虚拟主机将给定域的请求传递到单独的 Web 服务器. 出于本指南的目的,我们将 Apache
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
Apache Tomcat如何高并发处理请求
目录 介绍 接收Socket请求 Socket请求轮询 请求具体处理 总结 参考: 介绍 作为常用的http协议服务器,tomcat应用非常广泛.tomcat也是遵循Servelt协议的,Servelt协议可以让服务器与真实服务逻辑代码进行解耦.各自只需要关注Servlet协议即可.对于tomcat是如何作为一个高性能的服务器的呢?你是不是也会有这样的疑问? tomcat是如何接收网络请求? 如何做到高性能的http协议服务器? tomcat从8.0往后开始使用了NIO非阻塞io模型,提高了吞吐
-
Apache Hudi性能提升三倍的查询优化
目录 1. 背景 2. 设置 3. 测试 4. 结果 5. 总结 从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持. 1. 背景 Amazon EMR 团队最近发表了一篇很不错的文章展示了对数据进行聚簇是如何提高查询性能的,为了更好地了解发生了什么以及它与空间填充曲线的关系,让我们仔细研究该文章的设置. 文章中比较了 2 个 Apache Hudi 表(均来自 Amazon Reviews 数据集)
-
Vertica集成Apache Hudi重磅使用指南
目录 1. 摘要 2. Apache Hudi介绍 3. 环境准备 4. Vertica和Apache Hudi集成 4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3 4.2 配置 Vertica 和 Apache HUDI 集成 4.3 如何让 Vertica 查看更改的数据 4.3.1 写入数据 4.3.2 更新数据 4.3.3 创建和查看数据的历史快照 1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用
-
Apache Hudi数据布局黑科技降低一半查询时间
目录 1. 背景 2. Clustering架构 2.1 调度Clustering 2.2 运行Clustering 2.3 Clustering配置 3. 表查询性能 3.1 进行Clustering之前 3.2 进行Clustering之后 4. 总结 1. 背景 Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据.在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
基于Apache Hudi在Google云构建数据湖平台的思路详解
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中,包括数据库.blob存储和其他方法,为了进行有效的业务分析,必须对现代应用程序创建的数据进行处理和分析,并且产生的数据量非常巨大!有效地存储数PB数据并拥有必要的工具来查询它以便使用它至关重要,只有这样对该数据的分析才能产生有意义的结果.大数据是一门处理分析方法.有条不紊地从中提取信息或以其他方式处
-
Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
OnZoom基于Apache Hudi的一体架构实践解析
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创建.主持和盈利的活动,如健身课.音乐会.站立表演或即兴表演,以及Zoom会议平台上的音乐课程. 在OnZoom data platform中,source数据主要分为MySQL DB数据和Log数据. 其中Kafka数据通过Spark Streaming job实时消费,MySQL数据通过Spark
-
Apache Hudi集成Spark SQL操作hide表
目录 1. 摘要 2. 环境准备 2.1 启动spark-sql 2.2 设置并发度 3. Create Table 4. Insert Into 4.1 Insert 4.2 Select 5. Update 5.1 Update 5.2 Select 6. Delete 6.1 Delete 6.2 Select 7. Merge Into 7.1 Merge Into Insert 7.2 Select 7.4 Merge Into Update 7.5 Select 7.6 Merge