python数据挖掘使用Evidently创建机器学习模型仪表板
目录
- 1、安装包
- 2、导入所需的库
- 3、加载数据集
- 4、创建模型
- 5、创建仪表板
- 6、可用报告类型
- 1)数据漂移
- 2)数值目标漂移
- 3)分类目标漂移
- 4)回归模型性能
- 5)分类模型性能
- 6)概率分类模型性能
解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么。创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的。
Evidently 是一个开源 Python 库,用于创建交互式可视化报告、仪表板和 JSON 配置文件,有助于在验证和预测期间分析机器学习模型。它可以创建 6 种不同类型的报告,这些报告与数据漂移、分类或回归的模型性能等有关。
让我们开始吧
1、安装包
使用 pip 软件包管理器安装,运行
$ pip install evidently
该工具允许在 Jupyter notebook 中以及作为单独的HTML文件构建交互式报告。如果你只想将交互式报告生成为HTML文件或导出为JSON配置文件,则安装现已完成。
为了能够在 Jupyter notebook 中构建交互式报告,我们使用Jupyter nbextension。如果想在 Jupyter notebook 中创建报告,那么在安装之后,您应该在 terminal 中运行以下两个命令。
要安装 jupyter Nbextion,请运行:
$ jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
运行
jupyter nbextension enable evidently --py --sys-prefix
有一点需要注意:安装后单次运行就足够了。无需每次都重复最后两个命令。
2、导入所需的库
在这一步中,我们将导入创建ML模型所需的库。我们还将导入用于创建用于分析模型性能的仪表板的库。此外,我们将导入 pandas 以加载数据集。
import pandas as pd import numpy as np from sklearn.ensemble import RandomForestRegressor from evidently.dashboard import Dashboard from evidently.tabs import RegressionPerformanceTab from evidently.model_profile import Profile from evidently.profile_sections import RegressionPerformanceProfileSection
3、加载数据集
在这一步中,我们将加载数据并将其分离为参考数据和预测数据。
raw_data = pd.read_csv('/content/day.csv', header = 0, sep = ',', parse_dates=['dteday'])
ref_data = raw_data[:120]
prod_data = raw_data[120:150]
ref_data.head()

4、创建模型
在这一步中,我们将创建机器学习模型,对于这个特定的数据集,我们将使用随机森林回归模型。
target = 'cnt' datetime = 'dteday' numerical_features = ['mnth', 'temp', 'atemp', 'hum', 'windspeed'] categorical_features = ['season', 'holiday', 'weekday', 'workingday', 'weathersit',] features = numerical_features + categorical_features model = RandomForestRegressor(random_state = 0) model.fit(ref_data[features], ref_data[target]) ref_data['prediction'] = model.predict(ref_data[features]) prod_data['prediction'] = model.predict(prod_data[features])
5、创建仪表板
在这一步中,我们将创建仪表板来解释模型性能并分析模型的不同属性,如 MAE、MAPE、误差分布等。
column_mapping = {}
column_mapping['target'] = target
column_mapping['prediction'] = 'prediction'
column_mapping['datetime'] = datetime
column_mapping['numerical_features'] = numerical_features
column_mapping['categorical_features'] = categorical_features
dashboard = Dashboard(tabs=[RegressionPerformanceTab])
dashboard .calculate(ref_data, prod_data, column_mapping=column_mapping)
dashboard.save('bike_sharing_demand_model_perfomance.html')

在上图中,可以清楚地看到显示模型性能的报告,可以使用上述代码下载并创建的 HTML 报告。
6、可用报告类型
1)数据漂移
检测特征分布的变化

2)数值目标漂移
检测数值目标和特征行为的变化。

3)分类目标漂移
检测分类目标和特征行为的变化

4)回归模型性能
分析回归模型的性能和模型误差
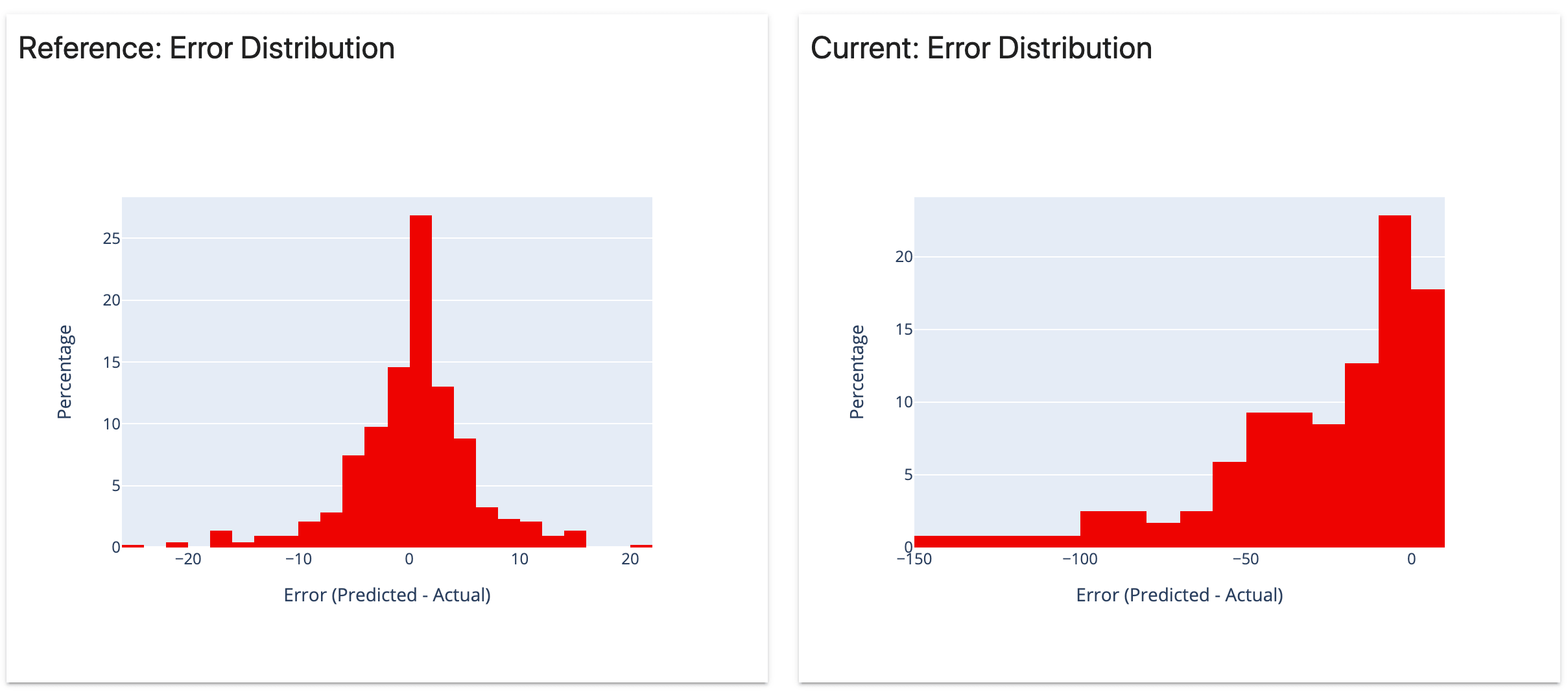
5)分类模型性能
分析分类模型的性能和错误。适用于二元和多类模型
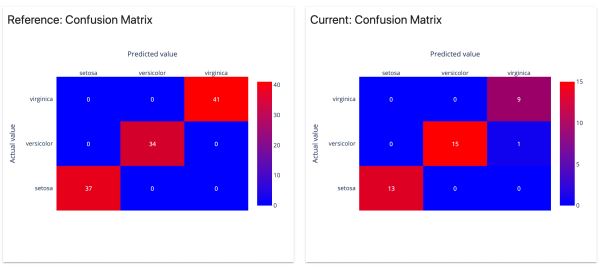
6)概率分类模型性能
分析概率分类模型的性能、模型校准的质量和模型错误。适用于二元和多类模型。

以上就是python数据挖掘使用Evidently创建机器学习模型仪表板的详细内容,更多关于Evidently创建机器学习模型仪表板的资料请关注我们其它相关文章!
相关推荐
-

提高python代码可读性利器pycodestyle使用详解
目录 关于PEP-8 目的 安装 基本用法 高级用法 结论 编程是数据科学中不可或缺的技能,虽然创建脚本来执行基本功能很容易,但编写大规模可读性良好的代码需要更多的思考. 关于PEP-8 pycodestyle 检查器提供基于 PEP-8 样式约定的代码建议.那么 PEP-8 到底是什么呢? PEP 代表 Python 增强建议,PEP-8 是一个概述编写 Python 代码最佳实践的指南.它的主要目标是通过标准化代码样式来提高代码的整体一致性和可读性. 目的 快速浏览一下PEP-8文档,就会发
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
python解释模型库Shap实现机器学习模型输出可视化
目录 安装所需的库 导入所需库 创建模型 创建可视化 1.Bar Plot 2.队列图 3.热图 4.瀑布图 5.力图 6.决策图 解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的.解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮. 我们开始吧- 安装所需的库 使用pip安装Shap开始.下面给出的命令可以做到这一点. pip install shap 导入所需库 在这一步中,我们将导入加载数据.创建模型和创建该模型的可视化所需的库. df = pd
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python人工智能human learn绘图可创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
python人工智能human learn绘图创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
Python OpenCV实战之与机器学习的碰撞
目录 0. 前言 1. 机器学习简介 1.1 监督学习 1.2 无监督学习 1.3 半监督学习 2. K均值 (K-Means) 聚类 2.1 K-Means 聚类示例 3. K最近邻 3.1 K最近邻示例 4. 支持向量机 4.1 支持向量机示例 小结 0. 前言 机器学习是人工智能的子集,它为计算机以及其它具有计算能力的系统提供自动预测或决策的能力,诸如虚拟助理.车牌识别系统.智能推荐系统等机器学习应用程序给我们的日常生活带来了便捷的体验.机器学习的蓬勃发展,得益于以下三个关键因素:1) 海
-
python 数据挖掘算法的过程详解
目录 1.首先简述数据挖掘的过程 第一步:数据选择 第二步:数据预处理 第三步:特征值数据转换 第四步:模型训练 第五步:测试模型+效果评估 第六步:模型使用 第七步:解释与评价 2.主要的算法模型讲解——基于sklearn 3.sklearn自带方法joblib来进行保存训练好的模型 1.首先简述数据挖掘的过程 第一步:数据选择 可以通过业务原始数据.公开的数据集.也可通过爬虫的方式获取. 第二步: 数据预处理 数据极可能有噪音,不完整等缺陷,需要对数据进行数据标准化,方法有min-max 标
-
python数据挖掘Apriori算法实现关联分析
目录 摘要: 关联分析 Apriori原理 算法实现 挖掘关联规则 利用Apriori算法解决实际问题 发现毒蘑菇的相似特征 总结: 摘要: 主要是讲解一些数据挖掘中频繁模式挖掘的Apriori算法原理应用实践 当我们买东西的时候,我们会发现物品展示方式是不同,购物以后优惠券以及用户忠诚度也是不同的,但是这些来源都是大量数据的分析,为了从顾客身上获得尽可能多的利润,所以需要用各种技术来达到目的. 通过查看哪些商品一起购物可以帮助商店了解客户的购买行为.这种从大规模数据集中寻找物品间的隐含关系被称
-
小白入门篇使用Python搭建点击率预估模型
点击率预估模型 0.前言 本篇是一个基础机器学习入门篇文章,帮助我们熟悉机器学习中的神经网络结构与使用. 日常中习惯于使用Python各种成熟的机器学习工具包,例如sklearn.TensorFlow等等,来快速搭建各种各样的机器学习模型来解决各种业务问题. 本文将从零开始,仅仅利用基础的numpy库,使用Python实现一个最简单的神经网络(或者说是简易的LR,因为LR就是一个单层的神经网络),解决一个点击率预估的问题. 1.假设一个业务场景 声明:为了简单起见,下面的一切设定从简-. 定义需
-
Python Django 后台管理之后台模型属性详解
十八.Django 后台模型属性篇 继续在之前的项目中进行代码的编码,首先要回忆一下通过 createsuperuser 命令创建的管理员账号,如果忘记了,需要重新创建一个. 本篇博客涉及的代码都在 admin.py 文件中,如果你首次打开本篇文章,请翻看本文结尾出的目录大纲,可以再次学习. 为了便于学习,提前在 models.py 中新增一个类,代码如下: from django.db import models class MyCenter(models.Model): pass 18.1
-
如何使用Python实现一个简易的ORM模型
本文记录下自己使用Python实现一个简易的ORM模型 使用到的知识 1.元类 2.描述器 元类 对于元类,我的理解其实也便较浅,大概是这个意思 所有的类都是使用元类来进行创建的,而所有的类的父类中必然是object(针对Python3),Python中的元类只有一个(type),当然这里不包含自定义元类 下面我们来看下类的创建 class Test: # 定义一个类 pass Test1 = type("Test2",(object,),{"name":"