用python实现爬取奥特曼图片实例
爬取网址:http://www.ultramanclub.com/allultraman/
使用工具:pycharm,requests
进入网页

打开开发者工具

点击 Network
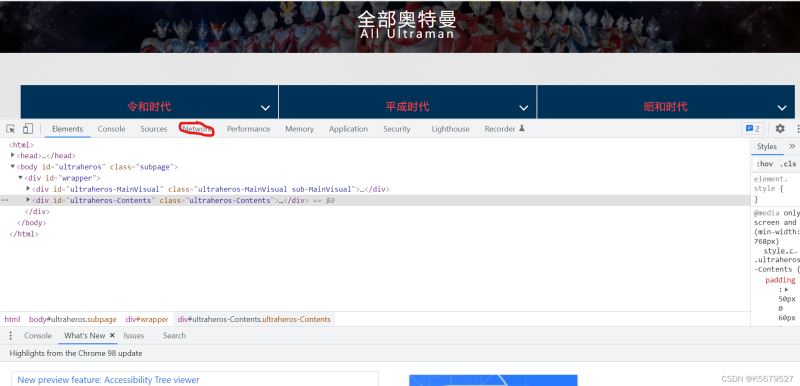
刷新网页,获取信息


其中的Request URL就是我们所爬取的网址
滑到最下有一个User-Agent,复制

向服务器发送请求

200意味着请求成功
使用 response.text 获取文本数据

可以看到有些乱码
使用encode转换
import requests
url = 'http://www.ultramanclub.com/allultraman/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = url,headers=headers)
html = response.text
Html=html.encode('iso-8859-1').decode('gbk')
print(Html)

接下来开始爬取需要的数据
使用Xpath获得网页链接
要使用Xpath必须先导入parsel包
import requests
import parsel
def get_response(html_url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = html_url,headers=headers)
return response
url = 'http://www.ultramanclub.com/allultraman/'
response = get_response(url)
html=response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(html)
period_hrefs = selector.xpath('//div[@class="btn"]/a/@href') #获取三个时代的网页链接
for period_href in period_hrefs:
print(period_href.get())

可以看到网页链接不完整,我们手动给它添加上去period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()

进入其中一个网页

跟之前的操作一样,用Xpath获取奥特曼的网页信息
for period_href in period_hrefs:
period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()
# print(period_href)
period_response = get_response(period_href).text
period_html = parsel.Selector(period_response)
lis = period_html.xpath('//div[@class="ultraheros-Contents_Generations"]/div/ul/li/a/@href')
for li in lis:
print(li.get())
运行后同样发现链接不完整

li = 'http://www.ultramanclub.com/allultraman/' + li.get().replace('./','')

拿到网址后继续套娃操作,就可以拿到图片数据

png_url = 'http://www.ultramanclub.com/allultraman/' + li_selector.xpath('//div[@class="left"]/figure/img/@src').get().replace('../','')

完整代码
import requests
import parsel
import os
dirname = "奥特曼"
if not os.path.exists(dirname): #判断是否存在名称为奥特曼的文件夹,没有就创建
os.mkdir(dirname)
def get_response(html_url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = html_url,headers=headers)
return response
url = 'http://www.ultramanclub.com/allultraman/'
response = get_response(url)
html=response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(html)
period_hrefs = selector.xpath('//div[@class="btn"]/a/@href') #获取三个时代的网页链接
for period_href in period_hrefs:
period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()
period_html = get_response(period_href).text
period_selector = parsel.Selector(period_html)
lis = period_selector.xpath('//div[@class="ultraheros-Contents_Generations"]/div/ul/li/a/@href')
for li in lis:
li = 'http://www.ultramanclub.com/allultraman/' + li.get().replace('./','') #获取每个奥特曼的网址
# print(li)
li_html = get_response(li).text
li_selector = parsel.Selector(li_html)
url = li_selector.xpath('//div[@class="left"]/figure/img/@src').get()
# print(url)
if url:
png_url = 'http://www.ultramanclub.com/allultraman/' + url.replace('.', '')
png_title =li_selector.xpath('//ul[@class="lists"]/li[3]/text()').get()
png_title = png_title.encode('iso-8859-1').decode('gbk')
# print(li,png_title)
png_content = get_response(png_url).content
with open(f'{dirname}\\{png_title}.png','wb') as f:
f.write(png_content)
print(png_title,'图片下载完成')
else:
continue


当爬到 奈克斯特奥特曼的时候,就会返回None,调了半天,也没搞懂,所以用if url:语句跳过了奈克斯特奥特曼,有没有大佬知道原因
url = li_selector.xpath('//div[@class="left"]/figure/img/@src').get()
到此这篇关于用python实现爬取奥特曼图片实例的文章就介绍到这了,更多相关python爬取奥特曼图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python图片处理之图片采样处理详解
目录 一.图像采样处理原理 二.图像采样实现 三.图像局部采样处理 四.总结 一.图像采样处理原理 图像采样(Image Sampling)处理是将一幅连续图像在空间上分割成M×N个网格,每个网格用一个亮度值或灰度值来表示,其示意图如图9-1所示. 图像采样的间隔越大,所得图像像素数越少,空间分辨率越低,图像质量越差,甚至出现马赛克效应:相反,图像采样的间隔越小,所得图像像素数越多,空间分辨率越高,图像质量越好,但数据量会相应的增大.图9-2展示了不同采样间隔的“Lena”图,其中图(a)为原始
-
python爬取微信公众号文章图片并转为PDF
遇到那种有很多图的微信公众号文章咋办?一个一个存很麻烦,应朋友的要求自己写了个爬虫.2.0版本完成了!完善了生成pdf的功能,可根据图片比例自动调节大小,防止超出页面范围,增加了序号方面查看 #-----------------settings--------------- #url='https://mp.weixin.qq.com/s/8JwB_SXQ-80uwQ9L97BMgw' print('jd3096 for king 2.0 VIP8钻石永久会员版') print('愿你远离流氓软
-
用python实现爬取奥特曼图片实例
爬取网址:http://www.ultramanclub.com/allultraman/ 使用工具:pycharm,requests 进入网页 打开开发者工具 点击 Network 刷新网页,获取信息 其中的Request URL就是我们所爬取的网址 滑到最下有一个User-Agent,复制 向服务器发送请求 200意味着请求成功 使用 response.text 获取文本数据 可以看到有些乱码 使用encode转换 import requests url = 'http://www.ultr
-
python实现爬取百度图片的方法示例
本文实例讲述了python实现爬取百度图片的方法.分享给大家供大家参考,具体如下: import json import itertools import urllib import requests import os import re import sys word=input("请输入关键字:") path="./ok" if not os.path.exists(path): os.mkdir(path) word=urllib.parse.quote(w
-
Python爬虫爬取网站图片
此次python3主要用requests,解析图片网址主要用beautiful soup,可以基本完成爬取图片功能, 爬虫这个当然大多数人入门都是爬美女图片,我当然也不落俗套,首先也是随便找了个网址爬美女图片 from bs4 import BeautifulSoup import requests if __name__=='__main__': url='http://www.27270.com/tag/649.html' headers = { "U
-
利用Python2下载单张图片与爬取网页图片实例代码
前言 一直想好好学习一下Python爬虫,之前断断续续的把Python基础学了一下,悲剧的是学的没有忘的快.只能再次拿出来滤了一遍,趁热打铁,通过实例来实践下,下面这篇文章主要介绍了关于Python2下载单张图片与爬取网页的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 一.需求分析 1.知道图片的url地址,将图片下载到本地. 2.知道网页地址,将图片列表中的图片全部下载到本地. 二.准备工作 1.开发系统:win7 64位. 2.开发环境:python2.7. 3
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天,试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代码: import urllib.request import os def url_open(url): req = urllib.reques
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例
本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫.分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: #coding=utf-8 import re import requests import urllib from bs4 import BeautifulSoup import time time1=time.time() def getHtml(url): page = requests.get(url) html =page.text
-
Python下使用Scrapy爬取网页内容的实例
上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现.研究的时候很痛苦,但是很享受,做技术的嘛. 首先,安装Python,坑太多了,一个个爬.由于我是windows环境,没钱买mac, 在安装的时候遇到各种各样的问题,确实各种各样的依赖. 安装教程不再赘述.如果在安装的过程中遇到 ERROR:需要windows c/c++问题,一般是由于缺少windows开发编译环境,晚上大多数教程是安装一个VisualStudio,太不靠谱了,事实上只要安装一个WindowsS
-
Python爬虫爬取糗事百科段子实例分享
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 1.抓取糗事百科热门段子: 2.过滤带有图片的段子: 3.实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数. 糗事百科是不需要登录的,所以也没必要用到Cookie,另外糗事百科有的段子是附图的,我们把图抓下来图片不便于显示,那么我们