浅析GBase8s 唯一索引与非唯一索引问题
唯一索引在列中不允许重复的值出现,可以用来定义和约束表中的一列或者多列组合值,在执行insert和update语句时需要检查唯一性。GBase8s中主键(PRIMARY KEY)会自动创建一个唯一索引。一个良好的表设计都应该定义主键或者唯一约束索引。特别是在OLTP系统中,唯一索引可以帮助快速定位少量记录。
唯一索引的创建语法:
CREATE UNIQUE INDEX idx_name ON tabname(col);
或者
CREATE DISTINCT INDEX idx_name ON tabname(col);
非唯一索引(可重复索引)可以在非主键列中创建,允许在列中出现重复的数据。但需要避免子键过于重复的数据列上创建索引,因为重复值越多的索引,其效率越低。
唯一索引与非唯一索引的实例图如下:
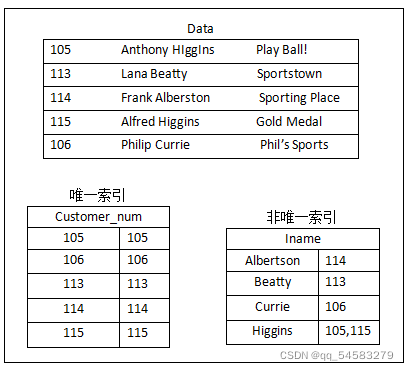
注意:由于需要在insert、update时进行唯一性判断,所以不建议在一个表上创建多个唯一索引。为了确保唯一性要求,一般在一张表中创建唯一索引就足够了。
补充:GBase 8s数据库表和主键索引使用的空间分离方法
GBase 8s数据库创建主键时一般情况下有两种方法:
1,创建表时指定主键,如:
create table tab1 ( id int, name varchar(255), primary key(id) ) in datadbs01;
2,使用alter语句修改表结构的方式创建主键
create table tab1 ( id int, name varchar(255) ) in datadbs01; alter table tab1 add constraint primary key(id);
这两种方法都无法为主键自动创建的索引指定单独的空间。
其实有一种变通的方式,可以将表使用的空间和主键索引使用的空间分离开,需要在方法2前加上创建唯一索引(即:不让alter table add primary key自动创建索引,而是使用刚创建的唯一索引),具体如下:
-- 创建表,使用datadbs01空间 create table tab1 ( id int, name varchar(255) ) in datadbs01; -- 创建唯一索引,使用indexdbs01空间 create unique index ix_tab1_id on tab1(id) in indexdbs01; -- 修改表,创建主键(关联唯一索引) alter table tab1 add constraint primary key(id);
到此这篇关于GBase8s 唯一索引与非唯一索引的文章就介绍到这了,更多相关GBase8s 索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅析GBase8s 唯一索引与非唯一索引问题
唯一索引在列中不允许重复的值出现,可以用来定义和约束表中的一列或者多列组合值,在执行insert和update语句时需要检查唯一性.GBase8s中主键(PRIMARY KEY)会自动创建一个唯一索引.一个良好的表设计都应该定义主键或者唯一约束索引.特别是在OLTP系统中,唯一索引可以帮助快速定位少量记录. 唯一索引的创建语法: CREATE UNIQUE INDEX idx_name ON tabname(col); 或者 CREATE DISTINCT INDEX idx_name ON t
-
浅析SQL Server 聚焦索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘.简短的内容,深入的理解. 话题 非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.你真的理解了吗??你能举出例子吗?
-
sql 聚集索引和非聚集索引(详细整理)
聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序. 聚集索引确定表中数据的物理顺序.聚集索引类似于电话簿,后者按姓氏排列数据.由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引.但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样. 聚集索引对于那些经常要搜索范围值的列特别有效.使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻.例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅
-
SQL Server 聚集索引和非聚集索引的区别分析
聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在"物理存储的排序"上,也就是首先要找到位置然后插入)查询数据比非聚集数据的速度快 汉语字典的正文本身就是一个聚集索引.比如,我们要查"安"字,就会很自然地翻开字典的前几页,因为"安"的拼音是"an",而按照拼音排序汉字的字典是以英文字母"a"开头并以"z"结尾的,那么&quo
-
sqlserver 聚集索引和非聚集索引实例
create database myIndexDemo go use myIndexDemo go create table ABC ( A int not null, B char(10), C varchar(10) ) go insert into ABC select 1,'B','C' union select 5,'B','C' union select 7,'B','C' union select 9,'B','C' go select * from ABC --在ABC表上创建聚
-
SQLSERVER的非聚集索引结构深度理解
我们知道SQLSERVER的数据行的存储有两种数据结构:A: 堆 B :B树(binary 二叉树) 数据按照这种两种的其中一种来排序和存储,学过数据结构的朋友应该知道二叉树,为什麽用二叉树,因为方便用二分查找法来快速 找到数据.如果是堆,那么数据是不按照任何顺序排序的,也没有任何结构,数据页面也不是首尾相连的,不像B树,数据页面 使用双向链表首尾相连.堆表只依靠表里的IAM页(索引分配映射页)将堆的页面联系在一起,IAM里记录了页面编号,页面位置 除非表里有聚集索引,如果没有的话那么表里的
-
MySQL索引之主键索引
在MySQL里,主键索引和辅助索引分别是什么意思,有什么区别? 上次的分享我们介绍了聚集索引和非聚集索引的区别,本次我们继续介绍主键索引和辅助索引的区别. 1.主键索引 主键索引,简称主键,原文是PRIMARY KEY,由一个或多个列组成,用于唯一性标识数据表中的某一条记录.一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL. 在MySQL中,InnoDB数据表的主键设计我们通常遵循几个原则: 1.采用一个没有业务用途的自增属性列作为主键: 2.主键字段值总是不更新,只有新增或
-
sqlserver索引的原理及索引建立的注意事项小结
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上.就好像参考手册将所有主题按顺序编排一样.一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据. SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就
-
索引的原理及索引建立的注意事项
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上.就好像参考手册将所有主题按顺序编排一样.一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据. SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就
-
教你通过B+Tree平衡多叉树理解InnoDB引擎的聚集和非聚集索引
目录 InnoDB引擎是通过B+Tree实现索引结构 二叉树(Binary Tree) 平衡二叉树(AVL Tree) 平衡多叉树(B-Tree) B+Tree 聚集和非聚集索引 聚集索引(clustered index) 非聚集索引(secondary index) InnoDB引擎是通过B+Tree实现索引结构 因为B+Tree是从二叉树演化而来,在这之前我们来先了解二叉树.平衡二叉树.平衡多叉树. 二叉树(Binary Tree) 简介:每个节点最多有两个子树的树结构.它有一个特点:左子树