python实现密度聚类(模板代码+sklearn代码)
本人在此就不搬运书上关于密度聚类的理论知识了,仅仅实现密度聚类的模板代码和调用skelarn的密度聚类算法。
有人好奇,为什么有sklearn库了还要自己去实现呢?其实,库的代码是比自己写的高效且容易,但自己实现代码会对自己对算法的理解更上一层楼。
#调用科学计算包与绘图包 import numpy as np import random import matplotlib.pyplot as plt
# 获取数据 def loadDataSet(filename): dataSet=np.loadtxt(filename,dtype=np.float32,delimiter=',') return dataSet
#计算两个向量之间的欧式距离
def calDist(X1 , X2 ):
sum = 0
for x1 , x2 in zip(X1 , X2):
sum += (x1 - x2) ** 2
return sum ** 0.5
#获取一个点的ε-邻域(记录的是索引)
def getNeibor(data , dataSet , e):
res = []
for i in range(dataSet.shape[0]):
if calDist(data , dataSet[i])<e:
res.append(i)
return res
#密度聚类算法
def DBSCAN(dataSet , e , minPts):
coreObjs = {}#初始化核心对象集合
C = {}
n = dataSet.shape[0]
#找出所有核心对象,key是核心对象的index,value是ε-邻域中对象的index
for i in range(n):
neibor = getNeibor(dataSet[i] , dataSet , e)
if len(neibor)>=minPts:
coreObjs[i] = neibor
oldCoreObjs = coreObjs.copy()
k = 0#初始化聚类簇数
notAccess = list(range(n))#初始化未访问样本集合(索引)
while len(coreObjs)>0:
OldNotAccess = []
OldNotAccess.extend(notAccess)
cores = coreObjs.keys()
#随机选取一个核心对象
randNum = random.randint(0,len(cores)-1)
cores=list(cores)
core = cores[randNum]
queue = []
queue.append(core)
notAccess.remove(core)
while len(queue)>0:
q = queue[0]
del queue[0]
if q in oldCoreObjs.keys() :
delte = [val for val in oldCoreObjs[q] if val in notAccess]#Δ = N(q)∩Γ
queue.extend(delte)#将Δ中的样本加入队列Q
notAccess = [val for val in notAccess if val not in delte]#Γ = Γ\Δ
k += 1
C[k] = [val for val in OldNotAccess if val not in notAccess]
for x in C[k]:
if x in coreObjs.keys():
del coreObjs[x]
return C
# 代码入口 dataSet = loadDataSet(r"E:\jupyter\sklearn学习\sklearn聚类\DataSet.txt") print(dataSet) print(dataSet.shape) C = DBSCAN(dataSet, 0.11, 5) draw(C, dataSet)
结果图:
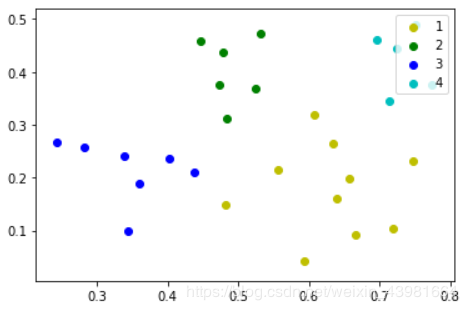
下面是调用sklearn库的实现
db = skc.DBSCAN(eps=1.5, min_samples=3).fit(dataSet) #DBSCAN聚类方法 还有参数,matric = ""距离计算方法
labels = db.labels_ #和X同一个维度,labels对应索引序号的值 为她所在簇的序号。若簇编号为-1,表示为噪声
print('每个样本的簇标号:')
print(labels)
raito = len(labels[labels[:] == -1]) / len(labels) #计算噪声点个数占总数的比例
print('噪声比:', format(raito, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 获取分簇的数目
print('分簇的数目: %d' % n_clusters_)
print("轮廓系数: %0.3f" % metrics.silhouette_score(X, labels)) #轮廓系数评价聚类的好坏
for i in range(n_clusters_):
print('簇 ', i, '的所有样本:')
one_cluster = X[labels == i]
print(one_cluster)
plt.plot(one_cluster[:,0],one_cluster[:,1],'o')
plt.show()
到此这篇关于python实现密度聚类(模板代码+sklearn代码)的文章就介绍到这了,更多相关python 密度聚类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python基于聚类算法实现密度聚类(DBSCAN)计算【测试可用】
本文实例讲述了Python基于聚类算法实现密度聚类(DBSCAN)计算.分享给大家供大家参考,具体如下: 算法思想 基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果. 几个必要概念: ε-邻域:对于样本集中的xj, 它的ε-邻域为样本集中与它距离小于ε的样本所构成的集合. 核心对象:若xj的ε-邻域中至少包含MinPts个样本,则xj为一个核心对象. 密度直达:若xj位于xi的ε-邻域中,且xi为核心对象,则xj由xi密度直达. 密度可达:若样
-
python实现密度聚类(模板代码+sklearn代码)
本人在此就不搬运书上关于密度聚类的理论知识了,仅仅实现密度聚类的模板代码和调用skelarn的密度聚类算法. 有人好奇,为什么有sklearn库了还要自己去实现呢?其实,库的代码是比自己写的高效且容易,但自己实现代码会对自己对算法的理解更上一层楼. #调用科学计算包与绘图包 import numpy as np import random import matplotlib.pyplot as plt # 获取数据 def loadDataSet(filename): dataSet=np.lo
-
python实现mean-shift聚类算法
本文实例为大家分享了python实现mean-shift聚类算法的具体代码,供大家参考,具体内容如下 1.新建MeanShift.py文件 import numpy as np # 定义 预先设定 的阈值 STOP_THRESHOLD = 1e-4 CLUSTER_THRESHOLD = 1e-1 # 定义度量函数 def distance(a, b): return np.linalg.norm(np.array(a) - np.array(b)) # 定义高斯核函数 def gaussian
-
python中kmeans聚类实现代码
k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进:另外一种是要对k大小的选择也没有很完善的理论,针对这个比较经典的理论是轮廓系数,二分聚类的算法确定k的大小,在最后还写了二分聚类算法的实现,代码主要参考机器学习实战那本书: #encoding:utf-8 ''''' Created on 2015年9月21日 @author: Z
-
python 利用jinja2模板生成html代码实例
这篇文章主要介绍了python 利用jinja2模板生成html代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 from jinja2 import Environment, FileSystemLoader import json def generate_html(data): env = Environment(loader=FileSystemLoader('./')) # 加载模板 template = env.get_tem
-
python绘图subplots函数使用模板的示例代码
背景 使用python进行图像可视化,很多情况下都需要subplots将多幅图像绘制在一个figure中.因为使用频率足够高,那么程序员就需要将其"封装",方便复用,所以,这里将笔者常用的subplots用法记录之. 如果有python绘图使用subplots出现标题重叠的解决方法 的问题,可以参考之. 模板 显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文 使用subplot(221) 对应的subplots代码: fr
-
Python自定义指标聚类实例代码
目录 前言 与KMeans++比较 Yolo检测框聚类 总结 前言 最近在研究 Yolov2 论文的时候,发现作者在做先验框聚类使用的指标并非欧式距离,而是IOU.在找了很多资料之后,基本确定 Python 没有自定义指标聚类的函数,所以打算自己做一个 设训练集的 shape 是 [n_sample, n_feature],基本思路是: 簇中心初始化:第 1 个簇中心取样本的特征均值,shape = [n_feature, ]:从第 2 个簇中心开始,用距离函数 (自定义) 计算每个样本到最近中
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索
-
Python数据结构之顺序表的实现代码示例
顺序表即线性表的顺序存储结构.它是通过一组地址连续的存储单元对线性表中的数据进行存储的,相邻的两个元素在物理位置上也是相邻的.比如,第1个元素是存储在线性表的起始位置LOC(1),那么第i个元素即是存储在LOC(1)+(i-1)*sizeof(ElemType)位置上,其中sizeof(ElemType)表示每一个元素所占的空间. 追加直接往列表后面添加元素,插入是将插入位置后的元素全部往后面移动一个位置,然后再将这个元素放到指定的位置,将长度加1删除是将该位置后面的元素往前移动,覆盖该元素,然
-
python实现发送带附件的邮件代码分享
具体代码如下: from django.template import loader from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.header import Header import smtplib import traceback class SendEmail(object): """ 发送html邮件