Pytorch数据拼接与拆分操作实现图解
1、cat:拼接
直接合并数据

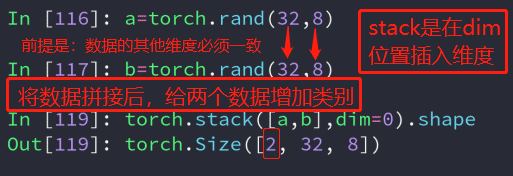
2、stack拼接:
与cat不同的是,stack创建了一个新的维度,在拼接的同时,给数据增加了类别。并且stack的所有数据维度必须一致。
3、split拆分:
通过数据长度进行拆分

4、chunk拆分:
与split不同的是:chunk是指定拆分的个数,将数据拆分为指定个数。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-
Pycharm中切换pytorch的环境和配置的教程详解
pytorch安装 注:在训练模型的时候,有时候可能需要不同版本的 torch和torchvision,所以需要配置不同的环境.anconda和pycharm自行安装,接下来在pycharm终端pip安装. 1. torch和torchvision下载 进入pytorch官网,[https://pytorch.org] 进入右下角的网站下载,找到需要的版本,我的版本如下 1.3.0-版本 cp37-python版本3.7 win-Windows系统 2. pycharm终端安装 (1)首先创建一
-
Windows下PyTorch开发环境安装教程
Anaconda安装 Anaconda是为方便使用python而建立的一个软件包,其包含常用的250多个工具包,多版本python解释器和强大的虚拟环境管理工具,所以Anaconda得名python全家桶.Anaconda可以使安装.运行和升级环境变得更简单,因此推荐安装使用. 安装步骤: 官网下载安装包 https://www.anaconda.com/distribution/#download-section 运行安装包 选择安装路径:通常选择默认路径,务必勾选Add Anaconda
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
在pytorch中实现只让指定变量向后传播梯度
pytorch中如何只让指定变量向后传播梯度? (或者说如何让指定变量不参与后向传播?) 有以下公式,假如要让L对xvar求导: (1)中,L对xvar的求导将同时计算out1部分和out2部分: (2)中,L对xvar的求导只计算out2部分,因为out1的requires_grad=False: (3)中,L对xvar的求导只计算out1部分,因为out2的requires_grad=False: 验证如下: #!/usr/bin/env python2 # -*- coding: utf-
-
Windows+Anaconda3+PyTorch+PyCharm的安装教程图文详解
1. 安装Anaconda3 官网下载Anaconda3:https://www.anaconda.com/distribution/ 运行下载好的.exe文件 Win+R 调出运行对话框,输入 cmd 回车,输入 python,如果出现python版本信息,表明安装成功. 添加环境变量:高级系统设置 -> 环境变量 2. 查看电脑显卡信息 以 Win10 为例,控制面板 -> NVIDIA控制面板 -> 帮助 -> 系统信息 -> 组件 3. 创建PyTorch环境 卸载原
-
Pytorch数据拼接与拆分操作实现图解
1.cat:拼接 直接合并数据 2.stack拼接: 与cat不同的是,stack创建了一个新的维度,在拼接的同时,给数据增加了类别.并且stack的所有数据维度必须一致. 3.split拆分: 通过数据长度进行拆分 4.chunk拆分: 与split不同的是:chunk是指定拆分的个数,将数据拆分为指定个数. 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.
-
Pytorch 使用 nii数据做输入数据的操作
使用pix2pix-gan做医学图像合成的时候,如果把nii数据转成png格式会损失很多信息,以为png格式图像的灰度值有256阶,因此直接使用nii的医学图像做输入会更好一点. 但是Pythorch中的Dataloader是不能直接读取nii图像的,因此加一个CreateNiiDataset的类. 先来了解一下pytorch中读取数据的主要途径--Dataset类.在自己构建数据层时都要基于这个类,类似于C++中的虚基类. 自己构建的数据层包含三个部分 class Dataset(object
-
c/c++ 利用sscanf进行数据拆分操作
sscanf使用示例 示例:使用sscanf分割文件中的数据,数据源示例如下 川EZ1E58,贵GQ7708,:1302 贵AE0996,:185 贵A0PJ06,贵JYN192,贵JYN192,:128 分割代码如下所示: #include <stdio.h> #include <string.h> int DealLine(char *StrLine) { // find : data save char Parkid[20] = ""; char *p =
-
Pytorch 高效使用GPU的操作
前言 深度学习涉及很多向量或多矩阵运算,如矩阵相乘.矩阵相加.矩阵-向量乘法等.深层模型的算法,如BP,Auto-Encoder,CNN等,都可以写成矩阵运算的形式,无须写成循环运算.然而,在单核CPU上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行.GPU(Graphic Process Units,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间.随着NVIDIA.AMD等公司不断推进其GPU的大规模并行架构,面向通用计算的GPU已成为加速可并
-

Pytorch数据读取与预处理该如何实现
在炼丹时,数据的读取与预处理是关键一步.不同的模型所需要的数据以及预处理方式各不相同,如果每个轮子都我们自己写的话,是很浪费时间和精力的.Pytorch帮我们实现了方便的数据读取与预处理方法,下面记录两个DEMO,便于加快以后的代码效率. 根据数据是否一次性读取完,将DEMO分为: 1.串行式读取.也就是一次性读取完所有需要的数据到内存,模型训练时不会再访问外存.通常用在内存足够的情况下使用,速度更快. 2.并行式读取.也就是边训练边读取数据.通常用在内存不够的情况下使用,会占用计算资源,如果分
-
很有意思的SQL多行数据拼接
要实现的SQL查询很原始: 要求从第一个表进行查询得到第二个表格式的数据,上网查询之后竟然能写出下面的SQL: 复制代码 代码如下: select * from userino SELECT * FROM( SELECT DISTINCT userpart FROM userino )A OUTER APPLY( SELECT [usernames]= replace(replace(replace((SELECT username as value FROM userino N WHERE u
-
详解Numpy中的数组拼接、合并操作(concatenate, append, stack, hstack, vstack, r_, c_等)
Numpy中提供了concatenate,append, stack类(包括hsatck.vstack.dstack.row_stack.column_stack),r_和c_等类和函数用于数组拼接的操作. 各种函数的特点和区别如下标: concatenate 提供了axis参数,用于指定拼接方向 append 默认先ravel再拼接成一维数组,也可指定axis stack 提供了axis参数,用于生成新的维度 hstack 水平拼接,沿着行的方向,对列进行拼接 vstack 垂直拼接,沿着列的
-
基于Python对数据shape的常见操作详解
这一阵在用python做DRL建模的时候,尤其是在配合使用tensorflow的时候,加上tensorflow是先搭框架再跑数据,所以调试起来很不方便,经常遇到输入数据或者中间数据shape的类型不统一,导致一些op老是报错.而且由于水平菜,所以一些常用的数据shape转换操作也经常百度了还是忘,所以想再整理一下. 一.数据的基本属性 求一组数据的长度 a = [1,2,3,4,5,6,7,8,9,10,11,12] print(len(a)) print(np.size(a)) 求一组数据的s
-
pandas数据拼接的实现示例
一 前言 pandas数据拼接有可能会用到,比如出现重复数据,需要合并两份数据的交集,并集就是个不错的选择,知识追寻者本着技多不压身的态度蛮学习了一下下: 二 数据拼接 在进行学习数据转换之前,先学习一些数拼接相关的知识 2.1 join()联结 有关merge操作知识追寻者这边不提及,有空可能后面会专门出一篇相关文章,因为其学习方式根SQL的表联结类似,不是几行能说清楚的知识点: join操作能将 2 个DataFrame 合并为一块,前提是DataFrame 之间的列没有重复: # -*-
-
在Vue中使用Select选择器拼接label的操作
我就废话不多说了,大家还是直接看代码吧~ <el-form-item label="货道商品" prop="productid"> <el-select v-model="form.productid" filterable placeholder="请选择" @change="changeselect"> <el-option v-for="item in mypr