一篇文章让你快速掌握Pandas可视化图表
目录
- 前言
- 1. 概述
- 2. 图表元素设置
- 3. 常见图表类型
- 4. 其他图表类型
- 总结
前言
今天简单介绍一下Pandas可视化图表的一些操作,Pandas其实提供了一个绘图方法plot(),可以很方便的将Series和Dataframe类型数据直接进行数据可视化。
1. 概述
这里我们引入需要用到的库,并做一些基础设置。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置 可视化风格
plt.style.use('tableau-colorblind10')
# 以下代码从全局设置字体为SimHei(黑体),解决显示中文问题【Windows】
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决中文字体下坐标轴负数的负号显示问题
plt.rcParams['axes.unicode_minus'] = False
plot方法默认是折线图,而它还支持以下几类图表类型:
‘line' : 折线图 (default)
‘bar' : 柱状图
‘barh' : 条形图
‘hist' : 直方图
‘box' : 箱型图
‘kde' : 密度图
‘density' : 同密度图
‘area' : 面积图
‘pie' : 饼图
‘scatter' : 散点图 (DataFrame only)
‘hexbin' : 六边形箱体图 (DataFrame only)
# 随机种子
np.random.seed(1)
ts = pd.Series(np.random.randn(100), index=pd.date_range("1/1/2020", periods=100))
ts = ts.cumsum()
ts.plot()

2. 图表元素设置
图表元素设置主要是指 数据源选择、图大小、标题、坐标轴文字、图例、网格线、图颜色、字体大小、线条样式、色系、多子图、图形叠加与绘图引擎等等。
数据源选择
这里是指坐标轴的x、y轴数据,对于Series类型数据来说其索引就是x轴,y轴则是具体的值;对于Dataframe类型数据来说,其索引同样是x轴的值,y轴默认为全部,不过可以进行指定选择。
# 随机种子
np.random.seed(1)
df = pd.DataFrame(np.random.randn(100, 4), index=ts.index, columns=list("ABCD"))
df = df.cumsum()
df.head()
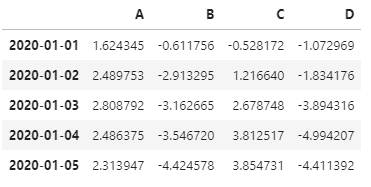
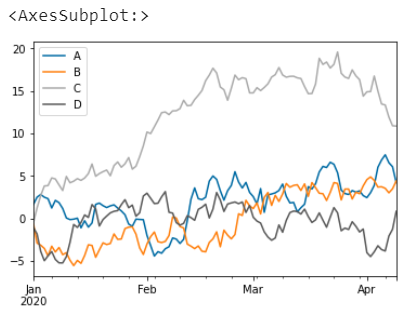
对于案例数据,直接绘图效果如下(显示全部列)
df.plot()
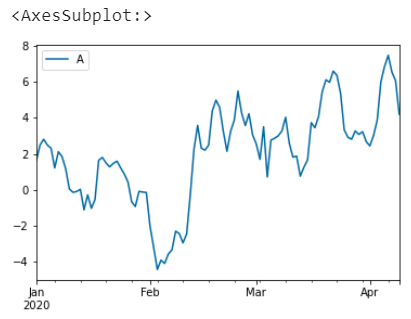
我们可以指定数据源,比如指定列A的数据
df.plot(y='A')
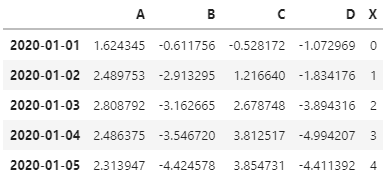
我们还可以指定x轴和多列为y,我这里先构建一列X,然后进行数据源选取
df["X"] = list(range(len(df))) df.head()
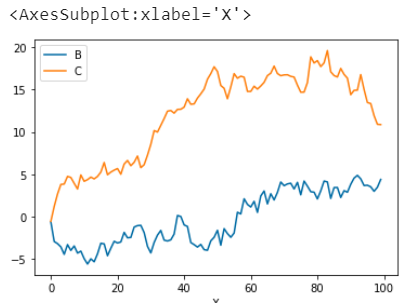
选择X列为x轴,B、C列为y轴数据
# 指定多个Y df.plot(x='X',y=['B','C'])
图大小
通过参数figsize传入一个元组,指定图的长宽(英寸)
注意:以下我们以柱状图为例做演示
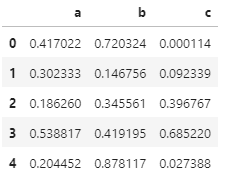
np.random.seed(1) df = pd.DataFrame(np.random.rand(10, 3), columns=["a", "b", "c"]) df.head()
# 图像大小 df.plot.bar(figsize=(10,5))

除了在绘图时定义图像大小外,我们还可以通过matplotlib的全局参数设置图像大小
plt.rcParams['figure.figsize'] = (10,5)
标题
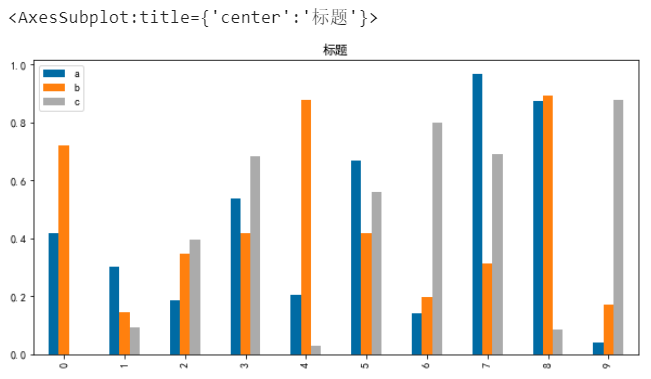
通过参数title设置图表标题,需要注意的是如果想要显示中文,需要提前设置相关字体参数,参考此前推文《》
# 标题 df.plot.bar(title='标题',)
图例
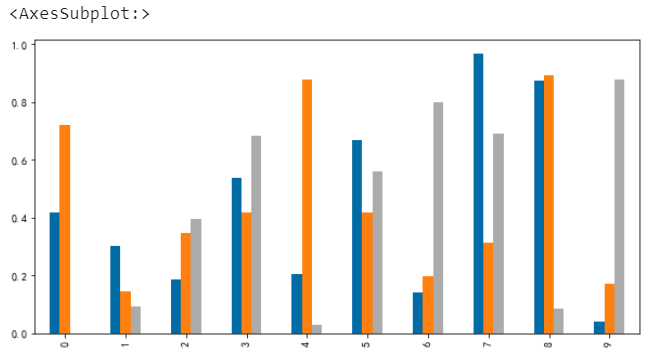
通过参数legend可以设置图例,默认是显示图例的,可以不显示或者显示的图例顺序倒序
# 图例不显示 df.plot.bar(legend=False)
# 图例倒序 df.plot.bar(legend='reverse')
坐标轴文字
细心的朋友可能会发现,在上图中x轴标签数字显示是躺着的,怎么坐起来呢?
那么可以通过参数rot设置文字的角度
# x轴标签旋转角度 df.plot.bar(rot=0)
网格线
默认情况下图表是不显示网格线的,我们可以通过参数grid来设置其显隐
# 网格线 df.plot.bar(grid=True)
图颜色
通过color参数可以设定填充颜色,edgecolor可以设置边框颜色
# 指定颜色 df.plot.bar(color=['red','orange','yellow'], edgecolor='grey')
字体大小
通过fontsize可以设置字体大小
# 字体大小 df.plot.bar(fontsize=20)
线条样式
对于折线图来说,还可以设置线条样式style
df.plot(style = ['.-','--','*-'] # 圆点、虚线、星星
)
色系
通过colormap参数可以指定色系,色系选择可以参考matplotlib库的色系表
# 指定色系 x = df.plot.bar(colormap='rainbow')
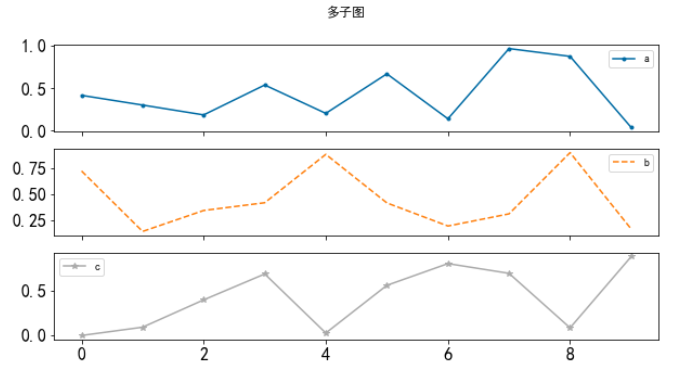
多子图
通过subplots参数决定是否以多子图形式输出显示图表
# 多子图
x = df.plot.line(title ='多子图',
fontsize =16,
subplots =True, # 分列
style = ['.-','--','*-','^-'] # 圆点、虚线、星星
)
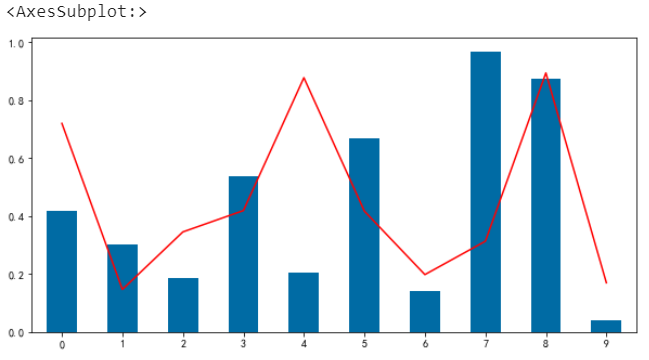
图像叠加
不同的图表类型组合在一起
df.a.plot.bar() df.b.plot(color='r')
绘图引擎
通过backend可以指定不同的绘图引擎,目前默认是matplotlib,还支持bokeh、plotly、Altair等等。当然,在使用新的引擎前需要先安装对应的库。
# 绘图引擎 import pandas_bokeh pandas_bokeh.output_notebook() df.plot.bar(backend='pandas_bokeh')
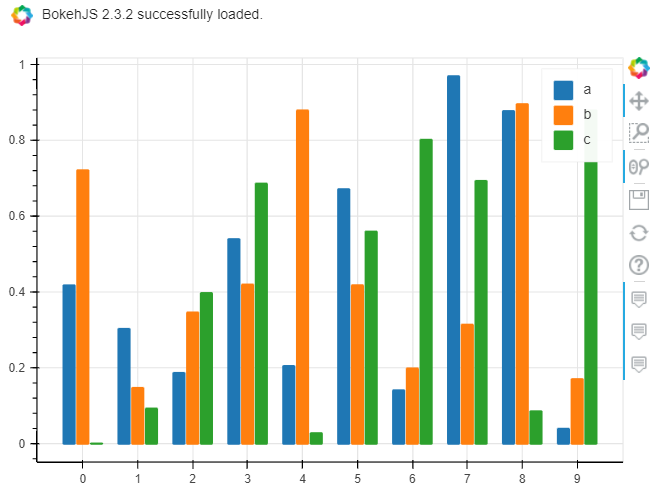
# 绘图引擎 plotly
df.plot.bar(backend='plotly',
barmode='group',
height=500, # 图表高度
width=800, # 图表宽度
)

3. 常见图表类型
在介绍完图表元素设置后,我们演示一下常见的几种图表类型。
柱状图
柱状图主要用于数据的对比,通过柱形的高低来表达数据的大小。
# 柱状图bar df.plot.bar()
(这里不做展示,前面案例中有)
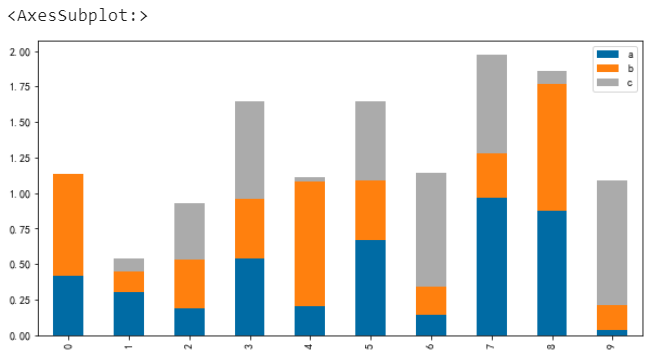
此外我们还可以绘制堆叠柱状图,通过设置参数stacked来搞定
# 堆叠柱状图 df.plot.bar(stacked=True)
柱状图多子图
# 柱状图多子图 df.plot.bar(subplots=True, rot=0)

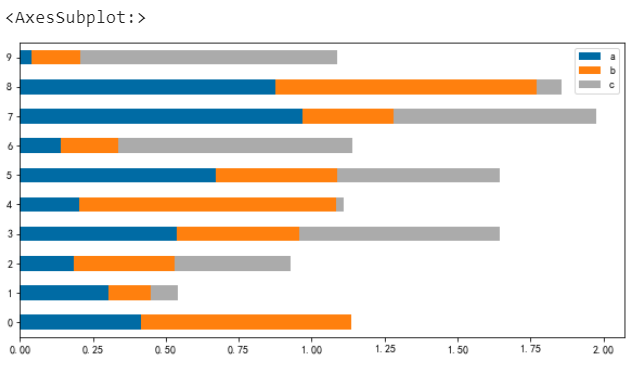
条形图
条形图和柱状图其实差不多,条形图就是柱状图的横向展示
# 条形图barh df.plot.barh(figsize=(6,8))
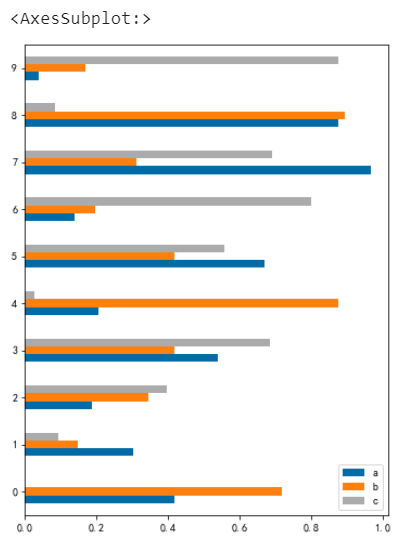
堆叠条形图
# 堆叠条形图 df.plot.barh(stacked=True)
直方图
直方图又称为质量分布图,主要用于描述数据在不同区间内的分布情况,描述的数据量一般比较大。
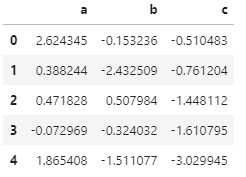
# 直方图
np.random.seed(1)
df = pd.DataFrame(
{
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000),
"c": np.random.randn(1000) - 1,
},
columns=["a", "b", "c"],
)
df.head()
df.plot.hist(alpha=0.5) # alpha设置透明度

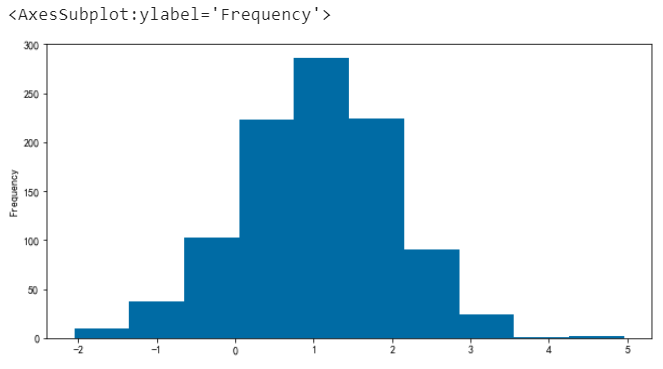
单直方图
# 单直方图 df.a.plot.hist()
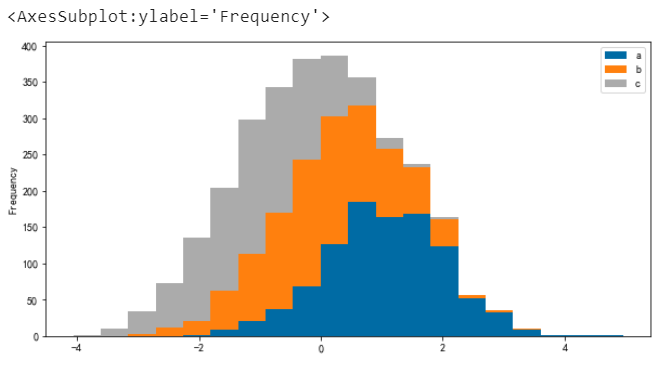
堆叠并指定分箱数(默认为 10)
# 堆叠并指定分箱数(默认为 10) df.plot.hist(stacked=True, bins=20)
横向展示
# 可以通过orientation='horizontal'和 cumulative=True 绘制横向和累积直方图 df["a"].plot.hist(orientation="horizontal", cumulative=True)
多子图展示
# 绘制多子图 df.hist(color="k", alpha=0.5, bins=50)
单个直方图(自定义分箱+透明度)
# 以下2种方式效果一致
df.hist('a', bins = 20, alpha=0.5)
# df.a.hist(bins = 20, alpha=0.5)
分组
# by 分组 np.random.seed(1) data = pd.Series(np.random.randn(1000)) data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4))
箱线图
箱线图又称盒须图、箱型图等,用于显示一组数据分布情况的统计图。
np.random.seed(1) df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"]) df.head()
df.boxplot()
指定元素颜色
# 指定元素颜色
color = {
"boxes": "Green", # 箱体颜色
"whiskers": "Orange", # 连线颜色
"medians": "Blue", # 中位数颜色
"caps": "Gray", # 极值颜色
}
df.boxplot(color=color, sym="r+")
横向展示
df.boxplot(vert=False, positions=[1, 4, 5, 6, 8])
面积图
面积图又称区域图,是将折线图与坐标轴之间的区域使用颜色填充,填充颜色可以很好地突出趋势信息,一般颜色带有透明度会更合适于观察不同序列之间的重叠关系。
np.random.seed(1) df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"]) df.head()
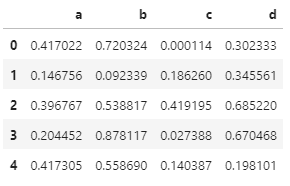
默认情况下,面积图是堆叠的
# 默认是堆叠 df.plot.area()
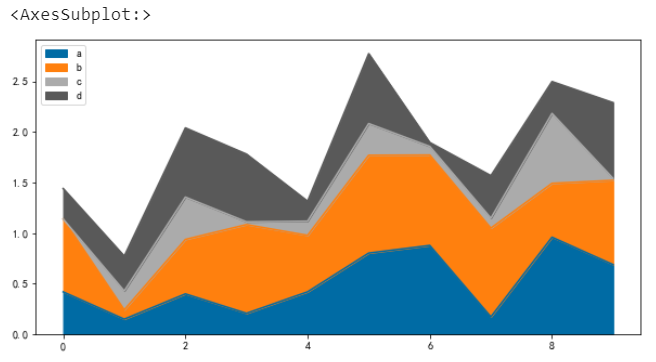
单个面积图
df.a.plot.area()
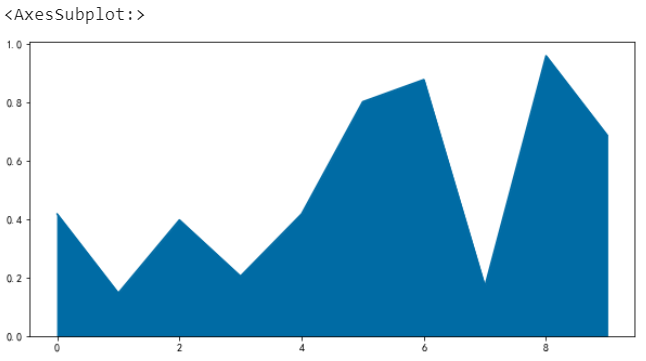
取消堆叠
# 取消堆叠 df.plot.area(stacked=False)
散点图
散点图就是将数据点展示在直角坐标系上,可以很好地反应变量之间的相互影响程度
np.random.seed(1) df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"]) df["species"] = pd.Categorical( ["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10 ) df.head()
指定一组数据
df.plot.scatter(x="a", y="b")

多组数据并用不同颜色标注
ax = df.plot.scatter(x="a", y="b", color="Blue", label="Group 1") df.plot.scatter(x="c", y="d", color="red", label="Group 2", ax=ax)
一组数据,x/y及z,其中x/y表示位置、z的值用于颜色区分
df.plot.scatter(x="a", y="b", c="c", s=50) # 参数s代表散点大小
一组数据,然后分类并用不同颜色(色系下)表示
df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50)
气泡图
df.plot.scatter(x="a", y="b", color="red", s=df["c"] * 200)
饼图
饼图主要用于不同分类的数据占总体的比例情况
np.random.seed(8) series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series") series

series.plot.pie(figsize=(6, 6), fontsize=20)
多子图展示
np.random.seed(8)
df = pd.DataFrame(
3 * np.random.rand(4, 2), index=["a", "b", "c", "d"], columns=["x", "y"]
)
df
df.plot.pie(subplots=True, figsize=(8, 4), fontsize=16)
指定显示样式
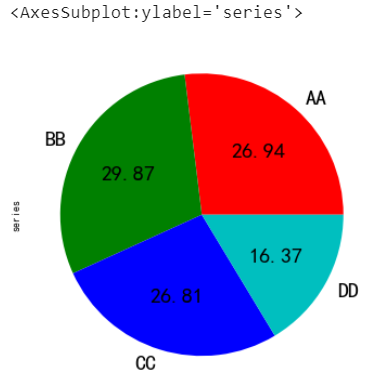
series.plot.pie(
labels=["AA", "BB", "CC", "DD"], # 标签
colors=["r", "g", "b", "c"], # 指定颜色
autopct="%.2f", # 数字格式(百分比)
fontsize=20,
figsize=(6, 6),
)
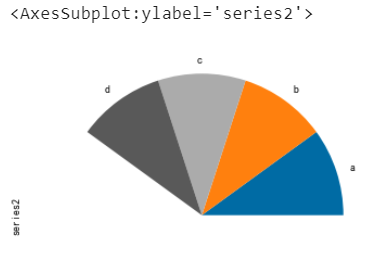
如果数据总和小于1,可以绘制扇形
series = pd.Series([0.1] * 4, index=["a", "b", "c", "d"], name="series2") series.plot.pie(figsize=(6, 6), normalize=False)
4. 其他图表类型
在常见图表中,有密度图和六边形箱型图 绘制过程报错,暂时没有解决(本机环境:pandas1.3.1)
本节主要介绍散点矩形图、安德鲁曲线等,更多资料大家可以查阅官方文档了解
https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html
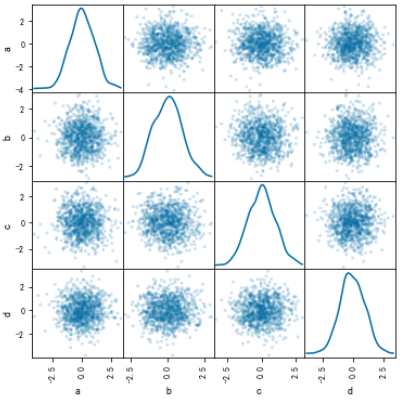
散点矩形图
from pandas.plotting import scatter_matrix df = pd.DataFrame(np.random.randn(1000, 4), columns=["a", "b", "c", "d"]) scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal="kde")
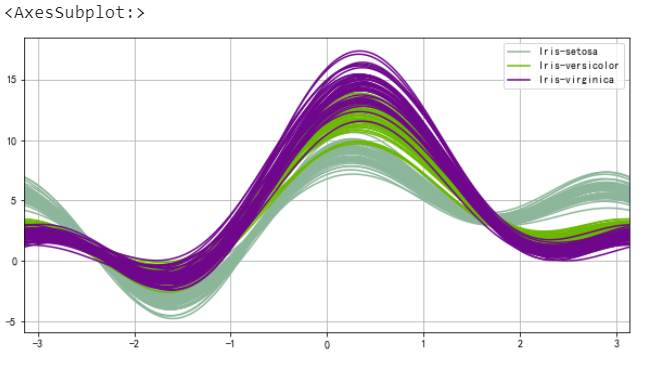
安德鲁曲线
from pandas.plotting import andrews_curves
data = pd.read_csv("iris.csv")
andrews_curves(data, "Name")
总结
到此这篇关于Pandas可视化图表的文章就介绍到这了,更多相关Pandas可视化图表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-

一篇文章让你快速掌握Pandas可视化图表
目录 前言 1. 概述 2. 图表元素设置 3. 常见图表类型 4. 其他图表类型 总结 前言 今天简单介绍一下Pandas可视化图表的一些操作,Pandas其实提供了一个绘图方法plot(),可以很方便的将Series和Dataframe类型数据直接进行数据可视化. 1. 概述 这里我们引入需要用到的库,并做一些基础设置. import pandas as pd import numpy as np import matplotlib.pyplot as plt # 设置 可视化风格 plt.
-
一篇文章快速了解Python的GIL
前言:博主在刚接触Python的时候时常听到GIL这个词,并且发现这个词经常和Python无法高效的实现多线程划上等号.本着不光要知其然,还要知其所以然的研究态度,博主搜集了各方面的资料,花了一周内几个小时的闲暇时间深入理解了下GIL,并归纳成此文,也希望读者能通过次本文更好且客观的理解GIL. GIL是什么 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念.就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执
-
一篇文章教你学会使用Python绘制甘特图
目录 优点 局限 一日一书 用来制作甘特图的专业工具也不少,常见的有:Microsoft Office Project.GanttProject.WARCHART XGantt.jQuery.Gantt.Excel等,网络上也有一些优质工具支持在线绘制甘特图. 可是这种现成的工具,往往也存在一些弊端,让编程人员不知所措.比如说,花里胡哨的UI,让人目不暇接,不知点哪个才好: 比如说,有些基于浏览器的图表需要掌握HTML.JS等编程语言,只会点Python的我直接被劝退: 再比如,进来就是注册.登
-
一篇文章入门Python生态系统(Python新手入门指导)
译者按:原文写于2011年末,虽然文中关于Python 3的一些说法可以说已经不成立了,但是作为一篇面向从其他语言转型到Python的程序员来说,本文对Python的生态系统还是做了较为全面的介绍.文中提到了一些第三方库,但是Python社区中强大的第三方库并不止这些,欢迎各位Pytonistas补充. •原文链接:http://mirnazim.org/writings/python-ecosystem-introduction/ •译文链接:http://codingpy.com/artic
-
一篇文章读懂Python赋值与拷贝
变量与赋值 在 Python 中,一切皆为对象,对象通过「变量名」引用,「变量名」更确切的叫法是「名字」,好比我们每个人都有自己的名字一样,咱们通过名字来代指某个人,代码里面通过名字来指代某个对象. 变量赋值就是给对象绑定一个名字,赋值并不会拷贝对象.好比我们出生的时候父母就要给我们取一个名字一样,给人取个绰号并不来多出一个人来,只是多一个名字罢了. 两个对象做比较有两种方式,分别是:is 与 == ,is比较的是两个对象是否相同,通过对象的ID值可识别是否为相同对象,==比较的是两个对象的值是
-
一篇文章学会Vue中间件管道
通常,在构建SPA时,需要保护某些路由.例如假设有一个只允许经过身份验证的用户访问的 dashboard 路由,我们可以通过使用 auth 中间件来确保合法用户才能访问它. 在本教程中,我们将学到怎样用 Vue-Router[1] 为Vue应用程序实现中间件管道. 什么是中间件管道? 中间件管道(middleware pipeline) 是一堆彼此并行运行的不同的中间件. 继续前面的案例,假设在 /dashboard/movies 上有另一个路由,我们只希望订阅用户可以访问.我们已经知道要访问
-
一篇文章理解阻塞、非阻塞、同步、异步
目录 理解阻塞.非阻塞.同步.异步 阻塞 非阻塞 同步 异步 总结 理解阻塞.非阻塞.同步.异步 首先说明,这些都是在特点场景下或者相对情况的词汇,OK,接下来开门见山. 阻塞 可以很直观的理解,就如节假日高速路出口收费站一样,上图片: 9个收费亭,同时来了一大波车,这时候同一时刻只能有9辆车在收费,剩下的车都在只能在后面排队等待,这就是现实中很直观的阻塞现象.这9个收费亭,就是一个瓶颈,或许画为这样更符合大家对瓶颈二字的理解: 第1张图中,高速公路源源不断的车辆到来,和第二张图的效果其实表示一
-
一篇文章学会java死锁与CPU 100%的排查
目录 01 Java死锁排查和解决 1.啥是死锁? 2.为啥子会出现死锁? 3.怎么排查代码中出现了死锁?[重点来了] 第一个姿势:使用 jps + jstack 第二个姿势:使用jconsole 第三个姿势:使用Java Visual VM 4.如何避免死锁? 02.Java CPU 100% 排查技巧 第一个姿势,步骤有点多,难度四星 第二个姿势,待开发[奸笑脸] 03 推荐两个高效排查问题工具 04 总结 05 彩蛋-另一个姿势 00 本文简介 作为一名搞技术的程序猿或者是攻城狮,想必你应
-
一篇文章读懂Java哈希与一致性哈希算法
目录 哈希 Hash 算法介绍 分布式存储场景 场景描述: 实现思路: 缺点: 一致性Hash算法 节点增加场景 节点减少场景 节点分布不均匀 虚拟节点 增加节点 节点减少 总结 哈希 Hash 算法介绍 哈希算法也叫散列算法, 不过英文单词都是 Hash, 简单一句话概括, 就是可以把任意长度的输入信息通过算法变换成固定长度的输出信息, 输出信息也就是哈希值, 通常哈希值的格式是16进制或者是10进制, 比如下面的使用 md5 哈希算法的示例 md5("123456") =>
-
一篇文章搞懂Go语言中的Context
目录 0 前置知识sync.WaitGroup 1 简介 2 context.Context引入 3 context包的其他常用函数 3.1 context.Background和context.TODO 3.2 context.WithCancel和 3.3 context.WithTimeout 3.4 context.WithDeadline 3.5 context.WithValue 4 实例:请求浏览器超时 5 Context包都在哪些地方使用 6 小结 0 前置知识sync.Wait