对python中使用requests模块参数编码的不同处理方法
python中使用requests模块http请求时,发现中文参数不会自动的URL编码,并且没有找到类似urllib (python3)模块中urllib.parse.quote("中文")手动URL编码的方法.研究了半天发现requests模块对中文参数有3种不同的处理方式.
一、requests模块自动URL编码参数
要使参数自动URL编码,需要将请求参数以字典的形式定义,如下demo:
import requests
proxy = {"http":"http://127.0.0.1:8080",
"https":"http://127.0.0.1:8080"}
def reTest():
url = "http://www.baidu.com"
pdict = {"name":"中文测试"}
requests.post(url = url,data = pdict,proxies = proxy)
效果如下图,中文被URL编码正确处理
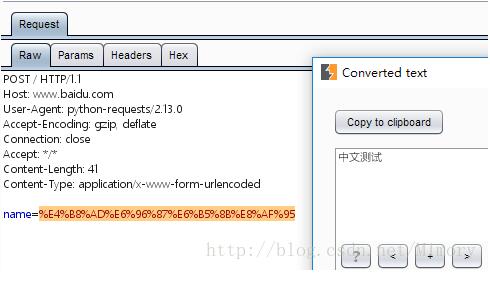
二、参数原样输出,不需要编码处理
使用dictionary定义参数,发送请求时requests模块会自动URL编码处理参数.但有些时候可能不需要编码,要求参数原样输出,这个时候将参数直接定义成字符串即可.
import requests
proxy = {"http":"http://127.0.0.1:8080",
"https":"http://127.0.0.1:8080"}
def reTest():
url = "http://www.baidu.com"
pstr1 = "name=中文".encode("utf-8")
requests.post(url = url,data = pstr1, proxies = proxy)
注:参数需要utf-8编码,否则会报错Use body.encode('utf-8') if you want to send it encoded in UTF-8.
最后效果如下图,参数原样输出:
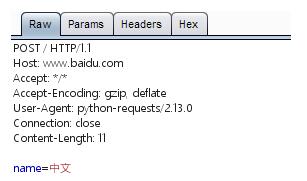
三、参数使用format或%格式化,导致参数str变成bytes
有些时候直接定义的字符串参数,其中有的参数是变量,需要format或%格式化控制变量.这个时候会发现格式化后的参数变成了bytes.
import requests
proxy = {"http":"http://127.0.0.1:8080",
"https":"http://127.0.0.1:8080"}
def reTest():
url = "http://www.baidu.com"
pstr2 = "name={0}".format("中文".encode("utf-8"))
requests.post(url = url,data = pstr2, proxies = proxy)
参数变成了bytes

在该种请求下:
1. 如果参数需要URL编码.当参数少的时候可以使用dict定义.如果参数太多,dict比较麻烦,可以针对参数使用urllib.parse.quote("中文")手动encode成URL编码.
2. 如果中文参数需要原样输出.将参数格式化完成后再编码即可.pstr2 = "name={0}".format("中文").encode("utf-8")
以上这篇对python中使用requests模块参数编码的不同处理方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python 使用requests模块发送GET和POST请求的实现代码
①GET # -*- coding:utf-8 -*- import requests def get(url, datas=None): response = requests.get(url, params=datas) json = response.json() return json 注:参数datas为json格式 ②POST # -*- coding:utf-8 -*- import requests def post(url, datas=None): response = re
-
Python3使用requests模块实现显示下载进度的方法详解
本文实例讲述了Python3使用requests模块实现显示下载进度的方法.分享给大家供大家参考,具体如下: 一.配置request 1. 相关资料 请求关键参数:stream=True.默认情况下,当你进行网络请求后,响应体会立即被下载.你可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性. tarball_url = 'https://github.com/kennethreitz/requests/tarball/master' r =
-
浅谈python中requests模块导入的问题
今天使用Pycharm来抓取网页图片时候,要导入requests模块,但是在pycharm中import requests 时候报错. 原因: python中还没有安装requests库 解决办法: 1.先找到自己python安装目录下的pip 2.在自己的电脑里打开cmd窗口. 先点击开始栏,在搜索栏输入cmd,按Enter,打打开cmd窗口.在cmd里将目录切换到你的pip所在路径. 比如我的在C:\Python27\Scripts这个目录下,先切换到d盘,再进入这个路径. 具体命令:cd.
-
Python requests模块实例用法
1.Requests模块说明 Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务. 在Python的世界里,事情不应该这么麻烦. Requests 使用的是 urllib3,因此继承了它的所有特性.Request
-
Python常用模块之requests模块用法分析
本文实例讲述了Python常用模块之requests模块用法.分享给大家供大家参考,具体如下: 一. GET请求 1.访问一个页面 import requests r=requests.get('http://www.so.com') print(r.status_code) print(r.text) 2.带参数 import requests params = {'a':1,'b':2} r=requests.get('http://www.so.com', params=params) p
-

python3使用requests模块爬取页面内容的实战演练
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip. $ sudo apt install python-pip 安装成功,查看PIP版本: $ pip -V 2.安装requests模块 这里我是通过pip方式进行安装: $ pip install requests 运行import requests,如果没提示错误,那说明已经安装成功了! 检验是否安装成功 3.安装beautifulsou
-
Python使用lxml模块和Requests模块抓取HTML页面的教程
Web抓取 Web站点使用HTML描述,这意味着每个web页面是一个结构化的文档.有时从中 获取数据同时保持它的结构是有用的.web站点不总是以容易处理的格式, 如 csv 或者 json 提供它们的数据. 这正是web抓取出场的时机.Web抓取是使用计算机程序将web页面数据进行收集 并整理成所需格式,同时保存其结构的实践. lxml和Requests lxml(http://lxml.de/)是一个优美的扩展库,用来快速解析XML以及HTML文档 即使所处理的标签非常混乱.我们也将使用 Re
-
python中requests模块的使用方法
本文实例讲述了python中requests模块的使用方法.分享给大家供大家参考.具体分析如下: 在HTTP相关处理中使用python是不必要的麻烦,这包括urllib2模块以巨大的复杂性代价获取综合性的功能.相比于urllib2,Kenneth Reitz的Requests模块更能简约的支持完整的简单用例. 简单的例子: 想象下我们试图使用get方法从http://example.test/获取资源并且查看返回代码,content-type头信息,还有response的主体内容.这件事无论使用
-
python使用requests模块实现爬取电影天堂最新电影信息
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到.可以说,Requests 完全满足如今网络的需求.本文重点给大家介绍python使用requests模块实现爬取电影天堂最新电影信息,具体内容如下所示: 在抓取网络数据的时候,有时会用正则对结构化的数据进行提取,比如 href="https://www.1234.com"等.python的re模块的findall()函数会返回一个所有匹配到的内容的列表,在将数据存入数据库时,列表数据
-
对python中使用requests模块参数编码的不同处理方法
python中使用requests模块http请求时,发现中文参数不会自动的URL编码,并且没有找到类似urllib (python3)模块中urllib.parse.quote("中文")手动URL编码的方法.研究了半天发现requests模块对中文参数有3种不同的处理方式. 一.requests模块自动URL编码参数 要使参数自动URL编码,需要将请求参数以字典的形式定义,如下demo: import requests proxy = {"http":"
-
在python中使用requests 模拟浏览器发送请求数据的方法
如下所示: import requests url='http://####' proxy={'http':'http://####:80'} headers={ "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip, deflate, br", "Accept-Lang
-
python中以函数作为参数(回调函数)的实现方法
目录 python以函数作为参数(回调函数) python函数的参数类型 一.必须参数 二.关键字参数 三.默认参数 四.不定长参数 总结 python以函数作为参数(回调函数) 纯粹是自己学习总结之用.回调函数搭配了元组和字典.在注释中已经标明有些需要注意的细节. #以函数作为参数 def func_callback(func1,args): print("调用函数:") func1(args) print("____________________") def
-
在Python中通过threading模块定义和调用线程的方法
定义线程 最简单的方法:使用target指定线程要执行的目标函数,再使用start()启动. 语法: class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}) group恒为None,保留未来使用.target为要执行的函数名.name为线程名,默认为Thread-N,通常使用默认即可.但服务器端程序线程功能不同时,建议命名. #!/usr/bin/env python3 # coding=utf
-
用Python中的turtle模块画图两只小羊方法
这两天在一个公众号里看到好玩的turtle库,今天来学习一下. turtle.circle(radius, extent=None, steps=None) 描述: 以给定半径画圆 参数: radius(半径); 半径为正(负),表示圆心在画笔的左边(右边)画圆 extent(弧度) (optional); steps (optional) (做半径为radius的圆的内切正多边形,多边形边数为steps) radius > 0,逆时针画圆 radius < 0,顺时针画圆 extent &g
-
对python中的logger模块全面讲解
logging模块介绍 Python的logging模块提供了通用的日志系统,熟练使用logging模块可以方便开发者开发第三方模块或者是自己的Python应用.同样这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP.GET/POST,SMTP,Socket等,甚至可以自己实现具体的日志记录方式.下文我将主要介绍如何使用文件方式记录log. logging模块包括logger,handler,filter,formatter这四个基本概念. logging模块与log4
-
python中的sys模块和os模块
目录 1.sys模块 2.os模块(和操作系统相关数据) 1.sys模块 sys模块的常见函数列表: sys.argv: 实现从程序外部向程序传递参数. sys.exit([arg]): 程序中间的退出,arg=0为正常退出. sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii. sys.setdefaultencoding(): 设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 se
-
python中的json模块常用方法汇总
目录 一.概述 二.方法详解 1.dump() 2.dumps 3.load 4.loads 三.代码实战 1.dumps() 2.dump() 4.loads() 一.概述 推荐使用参考网站:json 在python中,json模块可以实现json数据的序列化和反序列化 序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式 实现方法:load() loads() 反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象 实现方法:dump() du
-
python中的sys模块详解
目录 前言 处理命令行参数 sys.stdin.readline()与input sys.stdout与print 总结 前言 sys模块是与python解释器交互的一个接口.sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分. 处理命令行参数 在解释器启动后, argv 列表包含了传递给脚本的所有参数, 列表的第一个元素为脚本自身的名称. sys.argv[0] 表示程序自身sys.argv[1] 表示程序的第一个参数sys.argv[2] 表示程序的第二个参数 可以做
-
Python中使用select模块实现非阻塞的IO
Socket的英文原义是"孔"或"插座".作为BSD UNIX的进程通信机制,取后一种意思.通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄.在Internet上的主机一般运行了多个服务软件,同时提供几种服务.每种服务都打开一个Socket,并绑定到一个端口上,不同的端口对应于不同的服务.Socket正如其英文原意那样,像一个多孔插座.一台主机犹如布满各种插座的房间,每个插座有一个编号,有的插座提供220伏交流电, 有的提供110