Java基础知识之BufferedReader流的使用
目录
- 一、BufferedReader类概念
- 二、BufferedReader类实例域
- 三、BufferedReader类构造函数
- 四、BufferedReader类API
- 五、BufferedReader类与InputStreamReader类比较
一、BufferedReader类概念
API文档描述:
BufferedReader类从字符输入流中读取文本并缓冲字符,以便有效地读取字符,数组和行
可以通过构造函数指定缓冲区大小也可以使用默认大小。对于大多数用途,默认值足够大
由Reader构成的每个读取请求都会导致相应的读取请求由基础字符或字节流构成,建议通过BufferedReader包装Reader的实例类以提高效率如
BufferedReader in = new BufferedReader(new FileReader(“foo.in”));
使用DataInputStreams进行文本输入的程序可以通过用适当的BufferedReader替换每个DataInputStream来进行本地化
1)从字符输入流中读取文本并缓冲字符,以便有效地读取字符,数组和行怎么理解?
说明该类存在缓冲字符数组并且是该类可以高效读取字符的关键
2)构造函数指定缓冲区大小也可以使用默认大小怎么理解?
意味着该类存在的构造方法既可以传递数值指定缓冲区大小也可以由类中的默认大小指定
3)由Reader构成的每个读取请求都会导致相应的读取请求由基础字符或字节流构成,建议通过BufferedReader包装Reader的实例类以提高效率?
Reader构成的对象是字符对象,每次的读取请求都会涉及到字节读取解码字符的过程,而BufferedReader类中有设计减少这样的解码次数的方法,进而提高转换效率
4)BufferedReader替代DataInputStreams进行本地化?
需要查看DataInputStreams源码后才可知
二、BufferedReader类实例域
// 字符输入流
private Reader in;
// 字符缓冲区
private char cb[];
//读取字符存储的最末下标+1
private int nChars;
//读取字符存储的起始下标
private int nextChar;
private static final int INVALIDATED = -2;
private static final int UNMARKED = -1;
private int markedChar = UNMARKED;
// 仅在markedChar为0时有效
private int readAheadLimit = 0;
// 如果下个字符是换行符,则跳过--专用于readLine()方法里面控制
private boolean skipLF = false;
// 设置标志时的markedSkipLF--用于mark()方法的变量
private boolean markedSkipLF = false;
// 默认的字符缓冲大小
private static int defaultCharBufferSize =8192;
//用于readLine()方法时初始化StringBuffer的初始容量
private static int defaultExpectedLineLength = 80;
三、BufferedReader类构造函数
1)使用默认的缓冲区大小来创建缓冲字符输入流,默认大小为8192个字符
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}
public BufferedReader(Reader in, int sz) {
super(in);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.in = in;
cb = new char[sz];
nextChar = nChars = 0;
}
2)创建指定缓冲区大小的缓冲字符输入流,一般使用默认即可
public BufferedReader(Reader in, int sz) {
super(in);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.in = in;
cb = new char[sz];
nextChar = nChars = 0;
}
四、BufferedReader类API
1)read()方法:读取1个或多个字节,返回一个字符,当读取到文件末尾时,返回-1
/**
* 读取一个字符,若读取到末尾则返回-1
*/
public int read() throws IOException
{
synchronized (lock)
{
ensureOpen();
for (;;)
{
//一般条件为真,除非是使用了skip方法跳跃字节
if (nextChar >= nChars)
{
fill(); //调用该方法读取字符
if (nextChar >= nChars)
return -1;
}
//此方法暂时不用管,涉及跳过字节数和换行符问题
if (skipLF)
{
skipLF = false;
if (cb[nextChar] == '\n')
{
nextChar++;
continue;
}
}
return cb[nextChar++];
}
}
}
实际流程图解:

2)fill()方法:从底层输入流中填充字符到缓冲区中,此方法会调用StreamDecoder的方法实现字节到字符的转换
/**
* 填充字符缓冲区,若有效则将标记考虑在内
*/
private void fill() throws IOException
{
int dst;
//查看是否调用过make方法进行标记--若未使用make方法,则条件为真
if (markedChar <= UNMARKED)
{
dst = 0;
}
else
{
int delta = nextChar - markedChar;
if (delta >= readAheadLimit)
{
markedChar = INVALIDATED;
readAheadLimit = 0;
dst = 0;
}
else
{
if (readAheadLimit <= cb.length)
{
System.arraycopy(cb, markedChar, cb, 0, delta);
markedChar = 0;
dst = delta;
}
else
{
char ncb[] = new char[readAheadLimit];
System.arraycopy(cb, markedChar, ncb, 0, delta);
cb = ncb;
markedChar = 0;
dst = delta;
}
nextChar = nChars = delta;
}
}
int n;
do
{
//调用InputStreamReader的方法,实际是调用StreamDecoder的read(char cbuf[], int offset, int length)方法
n = in.read(cb, dst, cb.length - dst);
}
while (n == 0);
if (n > 0) //当读取到字符时
{
nChars = dst + n; //字符缓冲区存储读到的字符的最末下标
nextChar = dst; //字符缓冲区存储读到的字符的起始下标
}
}
实际流程图解:注意根据read()方法先理解变量nChars和nextChar的意义

3)read(char cbuf[], int off, int len):将最多length个字符读入数组中,返回实际读入的字符个数,当读取到文件末尾时,返回-1,
/**
* 字符读入数组的一部分,
*/
public int read(char cbuf[], int off, int len) throws IOException
{
synchronized (lock)
{
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0)
|| ((off + len) > cbuf.length) || ((off + len) < 0))
{
throw new IndexOutOfBoundsException();
}
else if (len == 0)
{
return 0;
}
int n = read1(cbuf, off, len); // 调用read1(cbuf, off, len)
if (n <= 0)
return n;
while ((n < len) && in.ready()) // 注意该while循环,多次测试发现并未进入该方法,即使进入,本质还是调用read1(cbuf, off, len)
{
int n1 = read1(cbuf, off + n, len - n);
if (n1 <= 0)
break;
n += n1;
}
return n;
}
}
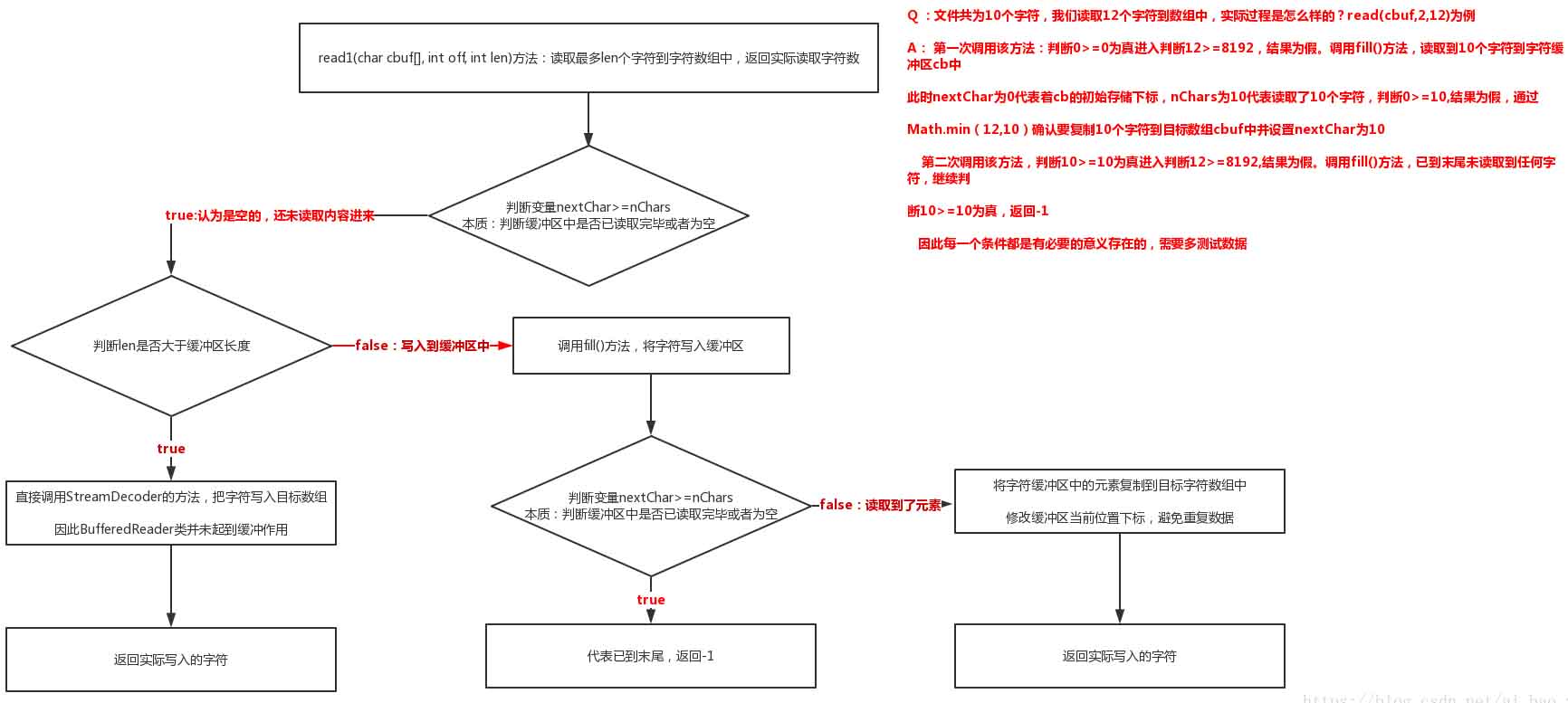
private int read1(char[] cbuf, int off, int len) throws IOException
{
if (nextChar >= nChars)
{
// 若请求的长度与缓冲区长度一样大时,直接会把字符读取到数组中,并未使用该类的字符缓冲区
if (len >= cb.length && markedChar <= UNMARKED && !skipLF)
{
return in.read(cbuf, off, len);
}
fill();
}
if (nextChar >= nChars)
return -1;
if (skipLF) //若使用了换行、跳过字节数等才会考虑判断,暂时不用管
{
skipLF = false;
if (cb[nextChar] == '\n')
{
nextChar++;
if (nextChar >= nChars)
fill();
if (nextChar >= nChars)
return -1;
}
}
int n = Math.min(len, nChars - nextChar); //取实际读取字符数与目标字符数len的最小数
System.arraycopy(cb, nextChar, cbuf, off, n); //从字符缓冲区中复制字符到目标数组中
nextChar += n; //字符缓冲区存储下标位置前诺,避免重复取一样数据
return n;
}
实际流程图解:图解read1(cbuf, off, len)方法即可,本质是该方法在起作用
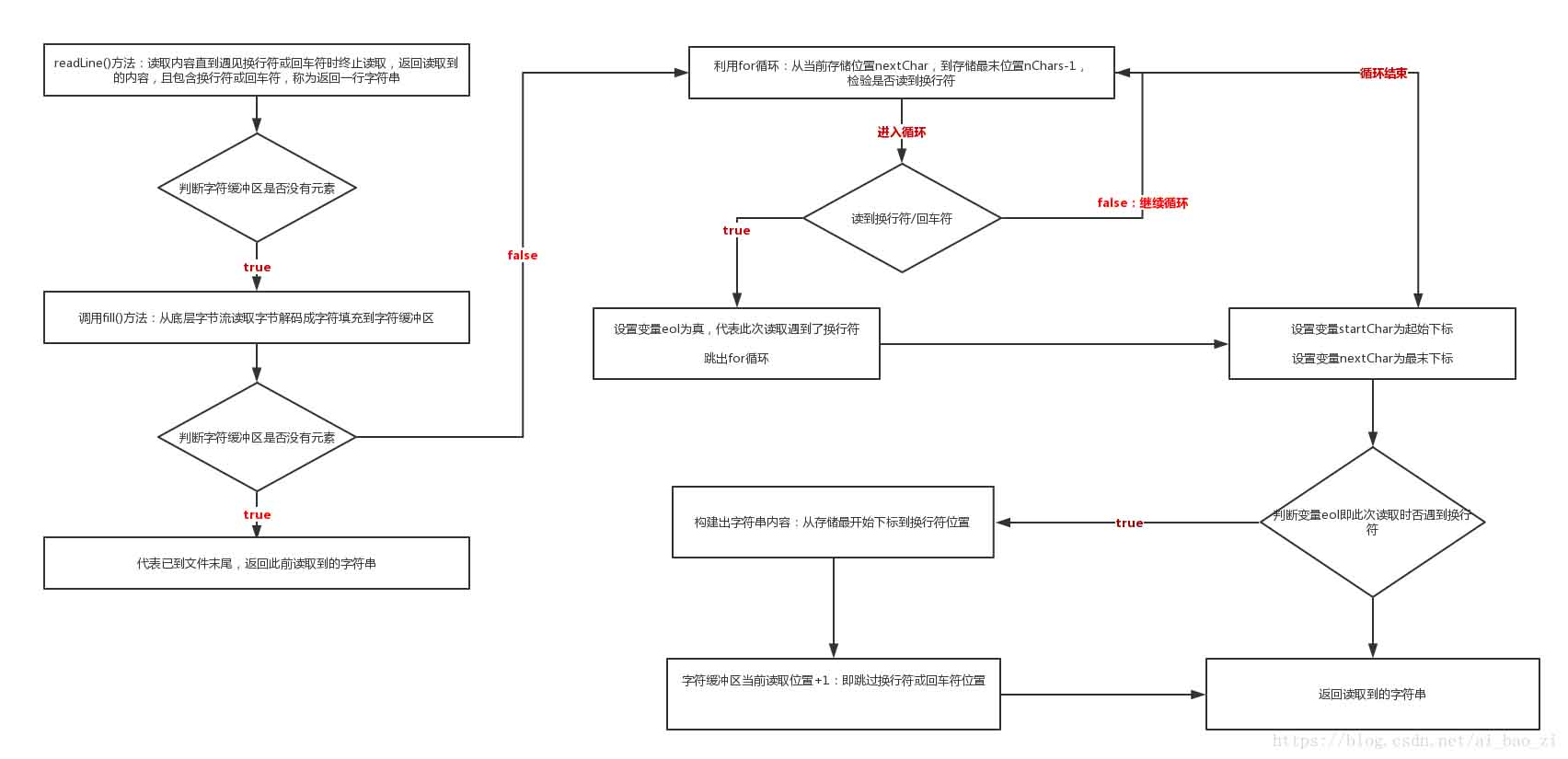
4)读一行文字并返回该行字符,若读到文件末尾,则返回null:即当遇到换行符('\ n'),回车符('\ r')时会终止读取表示该行文字读取完毕且返回该行文字(不包含换行符和回车符)
/**
* 阅读一行文字,任何一条线都被视为终止,返回包含该行内容的字符串,但是不含换行符等
*/
public String readLine() throws IOException
{
return readLine(false);
}
String readLine(boolean ignoreLF) throws IOException
{
StringBuffer s = null;
int startChar;
synchronized (lock)
{
ensureOpen();
boolean omitLF = ignoreLF || skipLF;
bufferLoop: for (;;)
{
if (nextChar >= nChars) //判断是否有元素,没有则调用fill()方法取元素
fill();
if (nextChar >= nChars) //判断是否已到文件末尾,若到文件末尾,则返回S
{
if (s != null && s.length() > 0)
return s.toString();
else
return null;
}
boolean eol = false;
char c = 0;
int i;
//如果遇到过换行符,则跳过该换行符继续读取
if (omitLF && (cb[nextChar] == '\n'))
nextChar++;
skipLF = false;
omitLF = false;
charLoop: for (i = nextChar; i < nChars; i++)
{
c = cb[i];
if ((c == '\n') || (c == '\r'))
{
eol = true;
break charLoop;
}
}
startChar = nextChar;
nextChar = i;
if (eol)
{
String str;
if (s == null)
{
str = new String(cb, startChar, i - startChar);
}
else
{
s.append(cb, startChar, i - startChar);
str = s.toString();
}
nextChar++;
if (c == '\r')
{
skipLF = true;
}
return str;
}
if (s == null)
s = new StringBuffer(defaultExpectedLineLength);
s.append(cb, startChar, i - startChar);
}
}
}
实际流程图解:
5)close()方法:关闭资源释放链接
public void close() throws IOException
{
synchronized (lock)
{
if (in == null)
return;
in.close();
in = null;
cb = null;
}
}
6)其它的skip()、make()方法等暂时不了解
五、BufferedReader类与InputStreamReader类比较
InputStreamReader中的文档说明提到过:为了获得最高效率,请考虑在BufferedReader中包装InputStreamReader?
从read()方法理解,若使用InputStreamReader的read()方法,可以发现存在每2次就会调用一次解码器解码,但若是使用 BufferedReader包装InputStreamReader后调用read()方法,可以发现只会调用一次解码器解码,其余时候都是直接从BufferedReader的缓冲区中取字符即可
从read(char cbuf[], int offset, int length)方法理解,若使用InputStreamReader的方法则只会读取leng个字符,但是使用BufferedReader类则会读取读取8192个字符,会尽量提取比当前操作所需的更多字节;
例如文件中有20个字符,我们先通过read(cbuf,0,5)要读取5个字符到数组cbuf中,然后再通过read()方法读取1个字符。那么使用InputStreamReader类的话,则会调用一次解码器解码然后存储5个字符到数组中,然后又调用read()方法调用一次解码器读取2个字符,然后返回1个字符;等于是调用了2次解码器,若使用BufferedReader类的话则是先调用一次解码器读取20个字符到字符缓冲区中,然后复制5个到数组中,在调用read()方法时,则直接从缓冲区中读取字符,等于是调用了一次解码器
因此可以看出BufferedReader类会尽量提取比当前操作所需的更多字节,以应该更多情况下的效率提升,
因此在设计到文件字符输入流的时候,我们使用BufferedReader中包装InputStreamReader类即可
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java BufferedReader相关源码实例分析
1.案例代码 假设b.txt存储了abcdegfhijk public static void main(String[] args) throws IOException { //字符缓冲流 BufferedReader bufferedReader=new BufferedReader(new FileReader (new File("H:\\ioText\\b.txt")),8); //存储读取的数据 char[] charsRead=new char[5]; //读取数据 b
-
Java中BufferedReader类获取输入输入字符串实例
使用Scanner来取得使用者的输入很方便,但是它以空白来区隔每一个输入字符串,在某些时候并不适用,因为使用者可能输入一个字符串,中间会包括空白字元,而您希望取得完整的字符串. 您可以使用BufferedReader类别,它是java.io包中所提供的一个类,所以使用这个类时必须先import java.io包:使用BufferedReader对象的readLine()方法必须处理IOException异常(exception),异常处理机制是Java提供给程序设计人员捕捉程序中可能发生的错误所
-
Java中BufferedReader与BufferedWriter类的使用示例
BufferedReader BufferedReader 是缓冲字符输入流.它继承于Reader. BufferedReader 的作用是为其他字符输入流添加一些缓冲功能. 创建BufferReader时,我们会通过它的构造函数指定某个Reader为参数.BufferReader会将该Reader中的数据分批读取,每次读取一部分到缓冲中:操作完缓冲中的这部分数据之后,再从Reader中读取下一部分的数据. 为什么需要缓冲呢?原因很简单,效率问题!缓冲中的数据实际上是保存在内存中,而原始数据可能
-
Java 中的 BufferedReader 介绍_动力节点Java学院整理
BufferedReader 介绍 BufferedReader 是缓冲字符输入流.它继承于Reader. BufferedReader 的作用是为其他字符输入流添加一些缓冲功能. BufferedReader 函数列表 BufferedReader(Reader in) BufferedReader(Reader in, int size) void close() void mark(int markLimit) boolean markSupported() int read() int
-
Java输入流Scanner/BufferedReader使用方法示例
1.使用Scanner 使用时需要引入包import java.util.Scanner;首先定义Scanner对象 Scanner sc = new Scanner(System.in);如果要输入整数,则 int n = sc.nextInt();String类型的,则String temp = sc.next(); 比如: 复制代码 代码如下: import java.util.Scanner; public class Test { @SuppressWarnings("resou
-

Java中BufferedReader与Scanner读入的区别详解
java.util.Scanner类是一个简单的文本扫描类,它可以解析基本数据类型和字符串.它本质上是使用正则表达式去读取不同的数据类型. Java.io.BufferedReader类为了能够高效的读取字符序列,从字符输入流和字符缓冲区读取文本. 在Java中,我们都知道Java的标准输入串是System.in.但是我们却很少在Java中看到谁使用它,这是因为我们平时输入的都是一个字符串或者是一个数字等等.而System.in提供的read方法是通过字节来读取数据的,所以对我们来说不方便处理!
-
Java BufferedWriter BufferedReader 源码分析
一:BufferedWriter 1.类功能简介: BufferedWriter.缓存字符输出流.他的功能是为传入的底层字符输出流提供缓存功能.同样当使用底层字符输出流向目的地中写入字符或者字符数组时.每写入一次就要打开一次到目的地的连接.这样频繁的访问不断效率底下.也有可能会对存储介质造成一定的破坏.比如当我们向磁盘中不断的写入字节时.夸张一点.将一个非常大单位是G的字节数据写入到磁盘的指定文件中的.没写入一个字节就要打开一次到这个磁盘的通道.这个结果无疑是恐怖的.而当我们使用Buffered
-
Java基础知识之BufferedReader流的使用
目录 一.BufferedReader类概念 二.BufferedReader类实例域 三.BufferedReader类构造函数 四.BufferedReader类API 五.BufferedReader类与InputStreamReader类比较 一.BufferedReader类概念 API文档描述: BufferedReader类从字符输入流中读取文本并缓冲字符,以便有效地读取字符,数组和行 可以通过构造函数指定缓冲区大小也可以使用默认大小.对于大多数用途,默认值足够大 由Reader构
-
Java基础知识之CharArrayWriter流的使用
目录 Java CharArrayWriter流 一.CharArrayWriter流定义 二.CharArrayWriter流构造函数 三.CharArrayWriter流实例域 四.CharArrayWriter流方法 四.CharArrayWriter流的作用 Java基础之什么是CharArrayWriter 下面的例子阐述了CharArrayWriter Java CharArrayWriter流 一.CharArrayWriter流定义 API说明:该类实现了一个可用作字符输出流的字
-
java基础知识I/O流使用详解
"流"概念源于UNIX中的管道(pipe)的概念.在UNIX中,管道是一条不间断的字节流,用来实现程序或进程间的通信,或读写外围设备.外部文件等,它屏蔽了实际的I/O设备中处理数据的细节. 一个流,必有源端和目的端,它们可以是计算机内存的某些区域,也可以是磁盘文件,甚至可以是Internet上的某个URL. 流的方向是重要的,根据流的方向,流可以分为两类:输入流和输出流.其实输入/输出是想对于内存来说的.实际上,流的源端和目的端可简单地看成是字节的生产者和消费者,对于输入流,可不必
-
java基础知识之FileInputStream流的使用
目录 一.File流概念 二.FileInputStream 1)FileInputStream概念 2)构造方法 3)FileInputStream常用API 三.三种read方法效率比较 一.File流概念 JAVA中针对文件的读写操作设置了一系列的流,其中主要有FileInputStream,FileOutputStream,FileReader,FileWriter四种最为常用的流 二.FileInputStream 1)FileInputStream概念 FileInputStream
-
Java基础知识之ByteArrayOutputStream流的使用
目录 Java ByteArrayOutputStream流的使用 一.ByteArrayOutputStream流定义 二.ByteArrayOutputStream流实例域 三.ByteArrayOutputStream流构造函数 四.ByteArrayOutputStream流方法 五.ByteArrayOutputStream流的作用 ByteArrayOutputStream 理解 ByteArrayOutputStream的用法 ByteArrayInputStream的用法 Jav
-
Java基础知识之StringWriter流的使用
目录 Java StringWriter流的使用 一.StringWriter流定义 二.StringWriter流实例域 三.StringWriter流构造函数 四.StringWriter流方法 五.StringWriter流的作用 使用StringWriter和StringReader的好处 Java StringWriter流的使用 一.StringWriter流定义 API说明:在字符串缓冲区中收集输出的字符流,可用于构造字符串, 关闭流无效,关闭后调用其他方法不会报异常 二.Stri
-
Java基础知识之StringReader流的使用
目录 Java StringReader流的使用 一.StringReader流定义 二.StringReader的实例域 三.StringReader流构造函数 四.StringReader流的API 五.StringReader流的作用 StringReader分析 IO流分类图 StringReader Java StringReader流的使用 一.StringReader流定义 API说明:字符串输入流.其本质就是字符串 二.StringReader的实例域 //流对象 private
-
Java基础知识之ByteArrayInputStream流的使用
目录 Java ByteArrayInputStream流 一.ByteArrayInputStream流定义 二.ByteArrayInputStream流实例域 三.ByteArrayInputStream流构造函数 四.ByteArrayInputStream流方法 五.ByteArrayInputStream流的作用 ByteArrayInputStream的用法解析 Java ByteArrayInputStream流 一.ByteArrayInputStream流定义 API说明:B
-
Java基础知识之CharArrayReader流的使用
目录 Java CharArrayReader流 一.CharArrayReader流定义 二.CharArrayReader流的构造函数 三.CharArrayReader流的实例域 四.CharArrayReader流的API 四.CharArrayReader流的作用 什么是CharArrayReader Java CharArrayReader流 一.CharArrayReader流定义 API说明:该类实现了一个可用作字符输入流的字符缓冲区,即该类可利用字符缓冲区当做字符输入流进行读取
-
详解Java基础知识——JDBC
JDBC Java DataBase Connectivity,java数据库连接,为了降低操作数据的难度,java提供jdbc,按照java面向对象特点,对操作进行了很多封装. JDBC提供了很多接口,然后不同数据库厂商去实现这个接口,到底底层如何去实现,不同的数据库不一样,不同的数据库厂商需要提供接口实现类(驱动类.驱动程序 Driver.驱动) 我们连接不同的数据库,我们只需要使用不同的驱动即可. J:Java:提供访问数据库的规范(接口), DBC:接口的实现,厂商去实现这个接口. JD