浅谈PostgreSQL和SQLServer的一些差异
条件查询-模糊匹配
PostgreSQL和SQL Server的模糊匹配like是不一样的,PostgreSQL的like是区分大小写的,SQL Server不区分。
测试如下:
//构造数据SQL create table t_user ( id integer PRIMARY KEY, name varchar(50) not null, code varchar(10) ); insert into t_user values(1,'Zhangsan','77771'); insert into t_user values(2,'Lisi',null);
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user where name like '%zhang%';
PostgreSQL结果:

SQL Server结果:

如果想让PostgreSQL的like也不区分大小写的话,可以使用ilike
select * from t_user where name ilike '%zhang%';
或者使用lower或者upper都转换成小写或者大写再模糊匹配,这种方式的SQL两种数据库都兼容。
select * from t_user where upper(name) like upper('%zhang%');
select * from t_user where lower(name) like lower('%zhang%');
条件查询-弱类型匹配
PostgreSQL在做条件查询的时候是强类型校验的,但是SQL Server是弱类型。
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user where code = 77771;
code是一个varchar类型的数据。
PostgreSQL结果:

SQL Server结果:

条件查询-末尾空白
SQL Server的查询如果末尾有空白的话,SQL Server会忽略但是PostgreSQL不会。
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user where code = '77771 ';
PostgreSQL结果:

SQL Server结果:
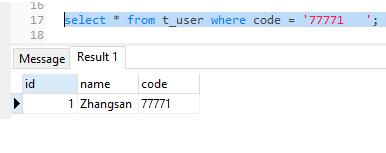
SQL Server是能查出数据的,但是PostgreSQL查不出来。
order by
1.PostgreSQL和SQL Server的默认order by行为是不一致的。
2.order by的字段如果是null,PostgreSQL会将其放在前面,SQL Server则将其放在后面。
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user order by code desc;
PostgreSQL:

SQL Server:

可以看出,查出来的数据的顺序是不同的。
某些情况下如果要求数据顺序在两个数据库中要一致的话,可以在PostgreSQL的查询SQL中增加nulls last来让null数据滞后。
select * from t_user order by code desc nulls last;
也可以使用case when来统一SQL:
ORDER BY (case when xxx is null then '' else xxx end) DESC;
字符串拼接
SQL Server使用" + “号来拼接字符串,并且在2012版本之前不支持concat函数。
PostgreSQL使用” || "来拼接字符串,同时支持concat函数。
查询表是否存在
//SQL Server select count(name) from sys.tables where type='u' and name='t_user'; //PostgreSQL select count(table_name) from information_schema.tables where table_name='t_user';
补充:SqlServer与Postgresql数据库字段类型对照表
如下所示:
sqlserver to postgresql type // "bigint", "bigint" // "binary", "bytea" // "bit", "boolean" // "char", "char" // "datetime", "timestamp" // "decimal", "numeric" // "float", "double precision" // "image", "bytea" // "int", "integer" // "money", "numeric(19,4)" // "nchar", "varchar" // "ntext", "text" // "numeric", "numeric" // "nvarchar", "varchar" // "real", "real" // "smalldatetime", "timestamp" // "smallint", "smallint" // "smallmoney", "numeric(10,4)" // "text", "text" // "timestamp", "bigint" // "tinyint", "smallint" // "uniqueidentifier", "uniqueidentifier" // "varbinary", "bytea" // "varchar", "varchar"
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

postgresql 实现查询出的数据为空,则设为0的操作
我就废话不多说了~ select name,price from odoo_sale; select name,COALESCE(price, 0) from odoo_sale; 补充:postgresql查询某列的最大值时,对查询结果为空做默认为0的处理 实例如下: select coalesce(max(max_grade),0) from exam_grade where examinee_id = 12345 and exam_id = 1; 查询某个考生在某个指定试卷的最高分,如果没
-
postgresql 12版本搭建及主备部署操作
postgresql 12版本主备部署 环境搭建 centos 7+ postgresql 12.0 # 网络检查 ping -c2 baidu.com #关闭防火墙,selinux systemctl stop firewalld && sudo systemctl disable firewalld sed -ri s/SELINUX=enforcing/SELINUX=disabled/g /etc/selinux/config setenforce 0 ### 配置阿里云yum源
-
postgresql 性能参数配置方式
查询Linux服务器配置 在进行性能调优之前,需要清楚知道服务器的配置信息,比如说 CPU,内存,服务器版本等信息. 查询系统版本信息 root@ubuntu160:~# lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 14.04.3 LTS Release: 14.04 Codename: trusty Linux查看物理CPU个数.核数.逻辑CPU个数 # 总核数
-
Postgresql去重函数distinct的用法说明
在项目中我们常会对数据进行去重处理,有时候会用in或者EXISTS函数.或者通过group by也是可以实现查重 不过Postgresql还有自带去重函数:distinct 下面是distinct 的实例: 1.创建表:user CREATE TABLE `user` ( `name` varchar(30) DEFAULT NULL, `age` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `us
-
Postgresql中xlog生成和清理逻辑操作
0 前言 1.2部分是对XLOG生成和清理逻辑的分析,XLOG暴涨的处理直接看第3部分. 1 WAL归档 # 在自动的WAL检查点之间的日志文件段的最大数量 checkpoint_segments = # 在自动WAL检查点之间的最长时间 checkpoint_timeout = # 缓解io压力 checkpoint_completion_target = # 日志文件段的保存最小数量,为了备库保留更多段 wal_keep_segments = # 已完成的WAL段通过archive_comm
-
postgresql 补齐空值、自定义查询字段并赋值操作
查询出的数据自定义url字段并赋值 select id,name,'/index/' url from table_name 补充:postgresql 判断是空的_postgresql 数字类型存空值或null值.字段查询处理 1.存储数字类型,包含Integer,Double等,拼接字符串时,数字类型的值拼接成以下 一个stqyghmj 为数据库字段名,第二个stqyghmj 是值变量 stqyghmj = cast(nullif(" + stqyghmj + ", null)AS
-
postgresql SQL语句变量的使用说明
一般变量使用我们都是放在函数里面,这里开发需求,要在SQL直接使用变量,方便查找一些问题,比如时间变量,要根据时间进行筛选 这里有三种方法可以实现 1.psql命令使用变量 表数据如下: hank=> select * from tb2; c1 | c2 | c3 ----+-------+---------------------------- 1 | hank | 2018-02-06 10:08:00.787503 2 | dazui | 2018-02-06 10:08:08.54248
-
浅谈PostgreSQL和SQLServer的一些差异
条件查询-模糊匹配 PostgreSQL和SQL Server的模糊匹配like是不一样的,PostgreSQL的like是区分大小写的,SQL Server不区分. 测试如下: //构造数据SQL create table t_user ( id integer PRIMARY KEY, name varchar(50) not null, code varchar(10) ); insert into t_user values(1,'Zhangsan','77771'); insert i
-
浅谈PostgreSQL表分区的三种方式
目录 一.简介 二.三种方式 2.1.Range范围分区 2.2.List列表分区 2.3.Hash哈希分区 三.总结 一.简介 表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案.一般建议当单表大小超过内存就可以考虑表分区了.PostgreSQL的表分区有三种方式: Range:范围分区: List:列表分区: Hash:哈希分区. 本文通过示例讲解如何进行这三种方式的分区. 二.三种方式 为方便,我们通过Docker的方式启动一个Postg
-
浅谈tempdb在SqlServer系统中的重要作用
简介: tempdb是SQLServer的系统数据库一直都是SQLServer的重要组成部分,用来存储临时对象.可以简单理解tempdb是SQLServer的速写板.应用程序与数据库都可以使用tempdb作为临时的数据存储区.一个实例的所有用户都共享一个Tempdb.很明显,这样的设计不是很好.当多个应用程序的数据库部署在同一台服务器上的时候,应用程序共享tempdb,如果开发人员不注意对Tempdb的使用就会造成这些数据库相互影响从而影响应用程序. 特性: 1. tempdb中的任何数据在系统
-
浅谈Mysql、SqlServer、Oracle三大数据库的区别
一.MySQL 优点: 体积小.速度快.总体拥有成本低,开源: 支持多种操作系统: 是开源数据库,提供的接口支持多种语言连接操作 : MySQL的核心程序采用完全的多线程编程.线程是轻量级的进程,它可以灵活地为用户提供服务,而不过多的系统资源.用多线程和C语言实现的mysql能很容易充分利用CPU: MySql有一个非常灵活而且安全的权限和口令系统.当客户与MySql服务器连接时,他们之间所有的口令传送被加密,而且MySql支持主机认证: 支持ODBC for Windows, 支持所有的ODB
-
浅谈postgresql数据库varchar、char、text的比较
如下所示: 名字 描述 character varying(n), varchar(n) 变长,有长度限制 character(n), char(n) 定长,不足补空白 text 变长,无长度限制 简单来说,varchar的长度可变,而char的长度不可变,对于postgresql数据库来说varchar和char的区别仅仅在于前者是变长,而后者是定长,最大长度都是10485760(1GB) varchar不指定长度,可以存储最大长度(1GB)的字符串,而char不指定长度,默认则为1,这点需要
-
浅谈PostgreSQL消耗的内存计算方法
wal_buffers默认值为-1,此时wal_buffers使用的是shared_buffers,wal_buffers大小为shared_buffers的1/32 autovacuum_work_mem默认值为-1,此时使用maintenance_work_mem的值 1 不使用wal_buffers.autovacuum_work_mem 计算公式为: max_connections*work_mem + max_connections*temp_buffers +shared_buffe
-
浅谈PostgreSQL的客户端认证pg_hba.conf
大家都知道防火墙主要是用来过滤客户端并保护服务器不被恶意访问攻击,那在pg中同样存在一个类似于防火墙的工具用来控制客户端的访问,也就是pg_hba.conf这个东东. 在initdb初始化数据文件时,默认提供pg_hba.conf. 通过配置该文件,能够指定哪些ip可以访问,哪些ip不可以访问,以及访问的资源和认证方式,该文件类似于oracle中的监听中的白名单黑名单功能,且同样可以reload在线生效. 记录可以是下面七种格式之一: local database user auth-metho
-
浅谈PostgreSQL中大小写不敏感问题
本文主要讨论PostgreSQL中大小写不敏感存在的问题. 默认情况下,PostgreSQL会将列名和表名全部转换为小写状态. 图1 Person与person 如图1所示,我们创建表person,其中包含name列.然后插入一条记录.执行SELECT查询时,使用列名Name和表名Person而不是name和person,发现仍然可以正常获取刚刚插入表person中的记录. 图2 创建表Person? 此时如果我们再想创建表Person,会得到一个错误,因为此时PostgreSQL实际上把表名从
-
浅谈Postgresql默认端口5432你所不知道的一点
关于Postgresql端口5432的定义: 5432端口,已经在IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)注册, 并把该端口唯一分配给Postgres. 这意味着,一台安装了linux OS的服务器,哪怕没有安装过postgresql数据库,也会有这个预留端口. 查看这个预留端口的方法如下: new@newdb-> cat /etc/services |grep 5432 postgres 5432/tcp postgresq
-
浅谈PostgreSQL中的孤儿文件用法(orphaned data files)
创建一个测试表 postgres=# create table t1(a int); CREATE TABLE postgres=# select pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/75062/75297 (1 row) postgres=# 在操作系统上已经可以看到该文件. $ ls -la $PGDATA/base/75062/75297 -rw------- 1 post