Pandas直接读取sql脚本的方法
之前有群友反应同事给了他一个几百MB的sql脚本,导入数据库再从数据库读取数据有点慢,想了解下有没有可以直接读取sql脚本到pandas的方法。
解析sql脚本文本文件替换成csv格式并加载
我考虑了一下sql脚本也就只是一个文本文件而已,而且只有几百MB,现代的机器足以把它一次性全部加载到内存中,使用python来处理也不会太慢。
我简单研究了一下sql脚本的导出格式,并根据格式写出了以下sql脚本的读取方法。
注意:该读取方法只针对SQLyog导出的mysql脚本测试,其他数据库可能代码需要根据实际情况微调。
读取方法:
from io import StringIO
import pandas as pd
import re
def read_sql_script_all(sql_file_path, quotechar="'") -> (str, dict):
insert_check = re.compile(r"insert +into +`?(\w+?)`?\(", re.I | re.A)
with open(sql_file_path, encoding="utf-8") as f:
sql_txt = f.read()
end_pos = -1
df_dict = {}
while True:
match_obj = insert_check.search(sql_txt, end_pos+1)
if not match_obj:
break
table_name = match_obj.group(1)
start_pos = match_obj.span()[1]+1
end_pos = sql_txt.find(";", start_pos)
tmp = re.sub(r"\)( values |,)\(", "\n", sql_txt[start_pos:end_pos])
tmp = re.sub(r"[`()]", "", tmp)
df = pd.read_csv(StringIO(tmp), quotechar=quotechar)
dfs = df_dict.setdefault(table_name, [])
dfs.append(df)
for table_name, dfs in df_dict.items():
df_dict[table_name] = pd.concat(dfs)
return df_dict
参数:
- sql_file_path:sql脚本的位置
- quotechar:脚本中字符串是单引号还是双引号,默认使用单引号解析
返回:
一个字典,键是表名,值是该表对应的数据所组成的datafream对象
下面我测试读取下面这个sql脚本:
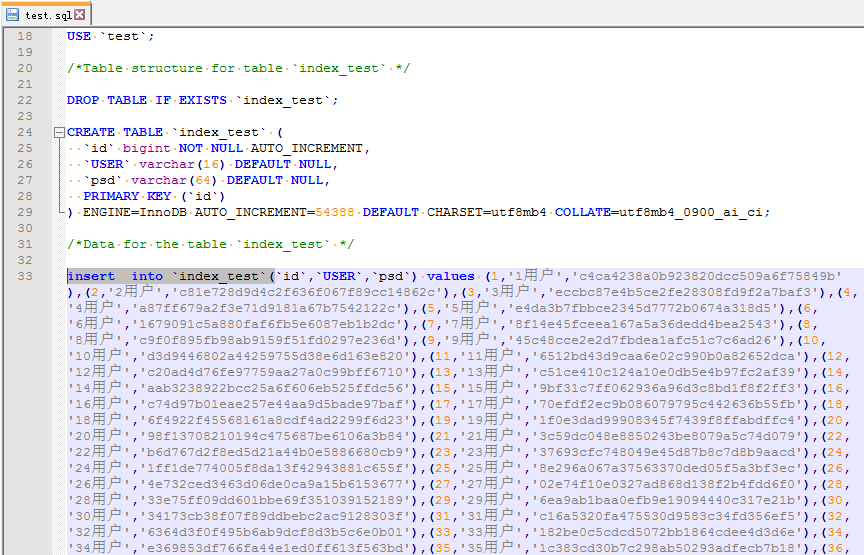
其中的表名是index_test:
df_dict = read_sql_script_all("D:/tmp/test.sql")
df = df_dict['index_test']
df.head(10)
结果:
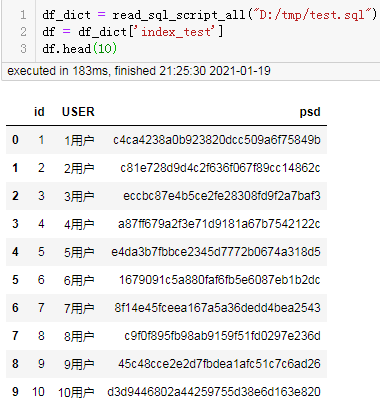
可以看到能顺利的直接从sql脚本中读取数据生成datafream。
当然上面写的方法是一次性读取整个sql脚本的所有表,结果为一个字典(键为表名,值为datafream)。但大部分时候我们只需要读取sql脚本的某一张表,我们可以改造一下上面的方法:
def read_sql_script_by_tablename(sql_file_path, table_name, quotechar="'") -> (str, dict):
insert_check = re.compile(r"insert +into +`?(\w+?)`?\(", re.I | re.A)
with open(sql_file_path, encoding="utf-8") as f:
sql_txt = f.read()
end_pos = -1
dfs = []
while True:
match_obj = insert_check.search(sql_txt, end_pos+1)
if not match_obj:
break
start_pos = match_obj.span()[1]+1
end_pos = sql_txt.find(";", start_pos)
if table_name != match_obj.group(1):
continue
tmp = re.sub(r"\)( values |,)\(", "\n", sql_txt[start_pos:end_pos])
tmp = re.sub(r"[`()]", "", tmp)
df = pd.read_csv(StringIO(tmp), quotechar=quotechar)
dfs.append(df)
return pd.concat(dfs)
参数:
- sql_file_path:sql脚本的位置
- table_name:被读取的表名
- quotechar:脚本中字符串是单引号还是双引号,默认使用单引号解析
返回:
该表所对应的datafream对象
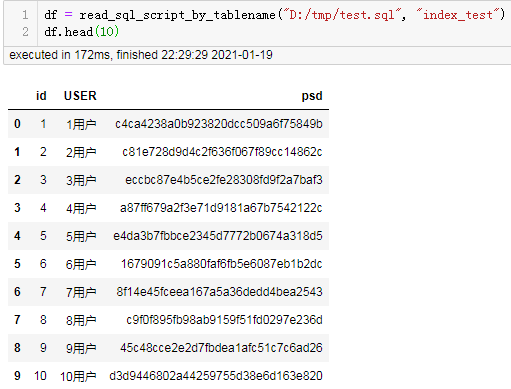
读取代码:
df = read_sql_script_by_tablename("D:/tmp/test.sql", "index_test")
df.head()
结果:
将sql脚本转换为sqlite格式并通过本地sql连接读取
在写完上面的方法后,我又想到另一种解决思路,就是将sql脚本转换成sqlite语法的sql语句,然后直接加载。各种类型的数据库的sql语句变化较大,下面的方法仅针对SQLyog导出的mysql脚本测试通过,如果是其他的数据库,可能下面的方法仍然需要微调。最好是先自行将sql脚本转换为sqlite语法的sql语句后,再使用我写的方法加载。
加载sql脚本的方法:
from sqlalchemy import create_engine
import pandas as pd
import re
def load_sql2sqlite_conn(sqltxt_path):
create_rule = re.compile("create +table [^;]+;", re.I)
insert_rule = re.compile("insert +into [^;]+;", re.I)
with open(sqltxt_path, encoding="utf-8") as f:
sqltxt = f.read()
engine = create_engine('sqlite:///:memory:')
pos = -1
while True:
match_obj = create_rule.search(sqltxt, pos+1)
if match_obj:
pos = match_obj.span()[1]
sql = match_obj.group(0).replace("AUTO_INCREMENT", "")
sql = re.sub("\).+;", ");", sql)
engine.execute(sql)
match_obj = insert_rule.search(sqltxt, pos+1)
if match_obj:
pos = match_obj.span()[1]
sql = match_obj.group(0)
engine.execute(sql)
else:
break
tablenames = [t[0] for t in engine.execute(
"SELECT tbl_name FROM sqlite_master WHERE type='table';").fetchall()]
return tablenames, engine.connect()
参数:
sql_file_path:sql脚本的位置
返回:
两个元素的元组,第一个元素是表名列表,第二个元素是sqlite内存虚拟连接
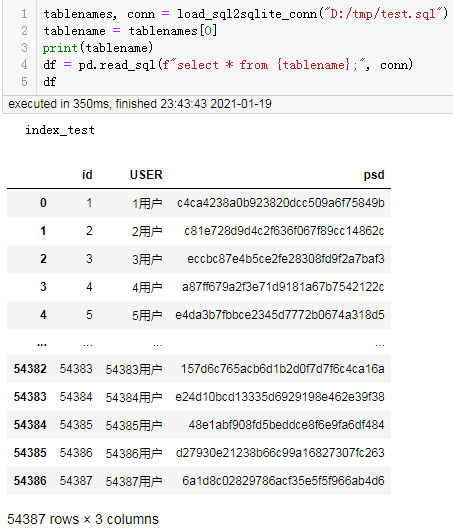
测试读取:
tablenames, conn = load_sql2sqlite_conn("D:/tmp/test.sql")
tablename = tablenames[0]
print(tablename)
df = pd.read_sql(f"select * from {tablename};", conn)
df
结果:
到此这篇关于Pandas直接读取sql脚本的文章就介绍到这了,更多相关Pandas读取sql脚本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现从SQL型数据库读写dataframe型数据的方法【基于pandas】
本文实例讲述了Python实现从SQL型数据库读写dataframe型数据的方法.分享给大家供大家参考,具体如下: Python的pandas包对表格化的数据处理能力很强,而SQL数据库的数据就是以表格的形式储存,因此经常将sql数据库里的数据直接读取为dataframe,分析操作以后再将dataframe存到sql数据库中.而pandas中的read_sql和to_sql函数就可以很方便得从sql数据库中读写数据. read_sql 参见pandas.read_sql的文档,read_sql主
-
pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见: # -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
Pandas读取MySQL数据到DataFrame的方法
方法一: #-*- coding:utf-8 -*- from sqlalchemy import create_engine class mysql_engine(): user='******' passwd='******' host='******' port = '******' db_name='******' engine = create_engine('mysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user,passwd,ho
-
python3 pandas 读取MySQL数据和插入的实例
python 代码如下: # -*- coding:utf-8 -*- import pandas as pd import pymysql import sys from sqlalchemy import create_engine def read_mysql_and_insert(): try: conn = pymysql.connect(host='localhost',user='user1',password='123456',db='test',charset='utf8')
-

pandas实现to_sql将DataFrame保存到数据库中
目的 在数据分析时,我们有中间结果,或者最终的结果,需要保存到数据库中:或者我们有一个中间的结果,如果放到数据库中通过sql操作会更加的直观,处理后再将结果读取到DataFrame中.这两个场景,就需要用到DataFrame的to_sql操作. 具体的操作 连接数据库代码 import pandas as pd from sqlalchemy import create_engine # default engine = create_engine('mysql+pymysql://ledao:
-
Pandas直接读取sql脚本的方法
之前有群友反应同事给了他一个几百MB的sql脚本,导入数据库再从数据库读取数据有点慢,想了解下有没有可以直接读取sql脚本到pandas的方法. 解析sql脚本文本文件替换成csv格式并加载 我考虑了一下sql脚本也就只是一个文本文件而已,而且只有几百MB,现代的机器足以把它一次性全部加载到内存中,使用python来处理也不会太慢. 我简单研究了一下sql脚本的导出格式,并根据格式写出了以下sql脚本的读取方法. 注意:该读取方法只针对SQLyog导出的mysql脚本测试,其他数据库可能代码需要
-
Python读取excel指定列生成指定sql脚本的方法
需求 最近公司干活,收到一个需求,说是让手动将数据库查出来的信息复制粘贴到excel中,在用excel中写好的公式将指定的两列数据用update这样的语句替换掉. 例如: 有个A库,其中有两个A.01和A.02字段,需要将这两个字段替换到下面的sql语句中, update A set A.01 = 'excel第一列的值' where A.02 = 'excel第二列的值' 虽然excel中公式写好了,但是还需要将总计的那行复制粘贴到txt文档中,所以索性太麻烦,果断用Python写了一个自动化
-
C#创建数据库及导入sql脚本的方法
本文实例讲述了C#创建数据库及导入sql脚本的方法.分享给大家供大家参考,具体如下: C#创建数据库: /// <summary> /// 创建数据库 /// </summary> /// <param name="connStr">连接字符串</param> /// <param name="_strDBName">数据库名称</param> /// <returns></r
-
使用pandas read_table读取csv文件的方法
read_csv是pandas中专门用于csv文件读取的功能,不过这并不是唯一的处理方式.pandas中还有读取表格的通用函数read_table. 接下来使用read_table功能作一下csv文件的读取尝试,使用此功能的时候需要指定文件中的内容分隔符. 查看csv文件的内容如下: In [10]: cat data.csv index,name,comment,,,, 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,come
-
shell中循环调用hive sql 脚本的方法
脚本tt.sh的内容如下: #!/bin/bash params=$1 for param in $params do echo $param done 运行方式为:sh tt.sh "1 2 3 4 5" 输出为: 1 2 3 4 5 所以参考上面的命令,可以把hql的脚本写为如下方式,就可以循环执行sql: 功能:查找字符串 comments 中的param第一次出现的位置 ,返回的是位置数字 #!/bin/bash params=$1 for param in $params d
-
对pandas写入读取h5文件的方法详解
1.引言 通过参考相关博客对hdf5格式简要介绍. hdf5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的. 使用压缩可以提磁盘利用率,节省空间. 开启压缩也没有什么劣势,只会慢一点点. 压缩在小数据量的时候优势不明显,数据量大了才有优势. 同时发现hdf读取文件的时候只能是一次写,写的时候可以append,可以put,但是写完成了之后关闭文件,就不能再写了, 会覆盖. 另外,为什么单独说pandas,主要因为本人目前对于h5py这个包的理解不是很深入,不
-
SpringBoot启动时自动执行sql脚本的方法步骤
需要配置项目下的yml文件: 在文件下加如如下配置: data: classpath:code-generator-data.sql initialization-mode: always spring.datasource.initialization-mode: 初始化模式(springboot2.0),其中有三个值: always为始终执行初始化 embedded只初始化内存数据库(默认值),如h2等 never为不执行初始化 spring.datasource.data: 数据初始化,默
-
Spring Boot中自动执行sql脚本的方法实例
目录 背景 实现核心 实现方法 注意 总结 说明:所有的代码基于SpringBoot 2.0.3版本 背景 在应用程序启动后,可以自动执行建库.建表等SQL脚本.下文中以要自动化执行people.sql脚本为例说明,脚本在SpringBoot工程中的路径为:classpath:people.sql,脚本的具体内容如下: CREATE TABLE IF NOT EXISTS people( persion_id BIGINT NOT NULL AUTO_INCREMENT, first_name
-
使用pandas生成/读取csv文件的方法实例
前言 csv是我接触的比较早的一种文件,比较好的是这种文件既能够以电子表格的形式查看又能够以文本的形式查看. 先引入pandas库 import pandas as pd 方法一: 1.我构造了一个cont_list,结构为列表嵌套字典,字典是每一个样本,类似于我们爬虫爬下来的数据的结构 2.利用pd.DataFrame方法先将数据转换成一个二维结构数据,如下方打印的内容所示,cloumns指定列表,列表必须是列表 3.to_csv方法可以直接保存csv文件,index=False表示csv文件
-
sqlserver 使用SSMS运行sql脚本的六种方法
摘要: 下文讲述五种运行sql脚本的方法,如下所示: 实验环境:sql server 2008 R2 在一次会议讨论中,大家咨询我使用SSMS运行sql脚本的方法,下文我将依次举例讲述sql脚本的运行方法,如下所示: 1.选中待运行sql脚本,按快捷键"F5" 2.选中待运行sql脚本,点击右键,选中"执行" 3.选中待运行sql脚本,按工具栏中的运行图标 4.选中待运行sql脚本,依次点击"查询"-->"!执行" 5.