Python 抓取动态网页内容方案详解
用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字。如下所示:
import urllib2
url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"
up=urllib2.urlopen(url)#打开目标页面,存入变量up
cont=up.read()#从up中读入该HTML文件
key1='<a href="http'#设置关键字1
key2="target"#设置关键字2
pa=cont.find(key1)#找出关键字1的位置
pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)
urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)
print urlx
但是,在动态页面中,所显示的内容往往不是通过HTML页面呈现的,而是通过调用js等方式从数据库中得到数据,回显到网页上。以发改委网站上的“备案信息”(http://beian.hndrc.gov.cn/)为例,要抓取此页面中的某些备案项目。例如“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”。
那么,在浏览器中打开此页面:
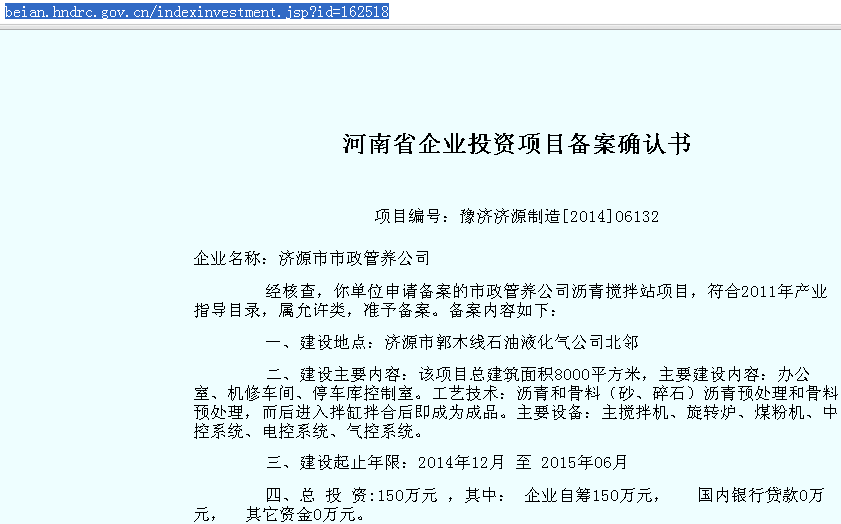
相关信息都显示的很全了,但是如果按照之前的办法:
up=urllib2.urlopen(url)
cont=up.read()
就抓取不到上述内容了。
我们查看一下这个页面对应的源码:

由源码可以看出,这个《备案确认书》属于“填空”形式的,HTML提供文字模板,js根据不同的id提供不同的变量,“填入”到文字模板中,形成了一个具体的《备案确认书》。所以单纯抓取此HTML,只能得到一些文字模板,而无法得到具体内容。
那么,该如何找到那些具体内容呢?可以利用Chrome的“开发者工具”来寻找谁是真正的内容提供者。
打开Chrome浏览器,按下键盘F12即可呼出此工具。如下图:
此时选中“Network”标签,在地址栏中输入此页面“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”,浏览器会分析出此次响应的全过程,而红框内的文件,就是此次响应中,浏览器和web后端的所有通信。
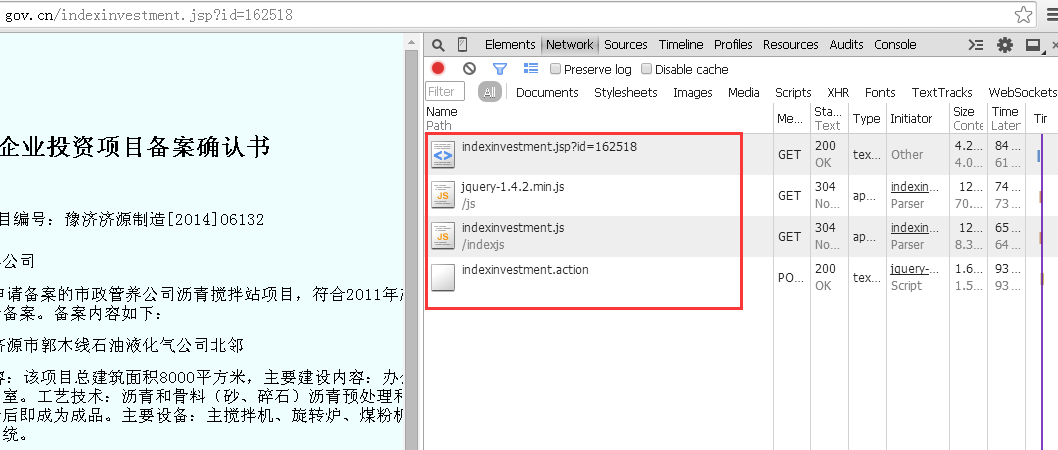
因为要获得不同企业对应的不同信息,那么浏览器发送给服务器的请求里面一定会有一个和当前企业id有关的参数。
那么,参数是多少呢?URL上有,是“jsp?id=162518”,问号表示要调用参数,后面跟的是id号即是被调用的参数。而通过对这几个文件的分析,很显然,企业信息存在于“indexinvestment.action”文件中。
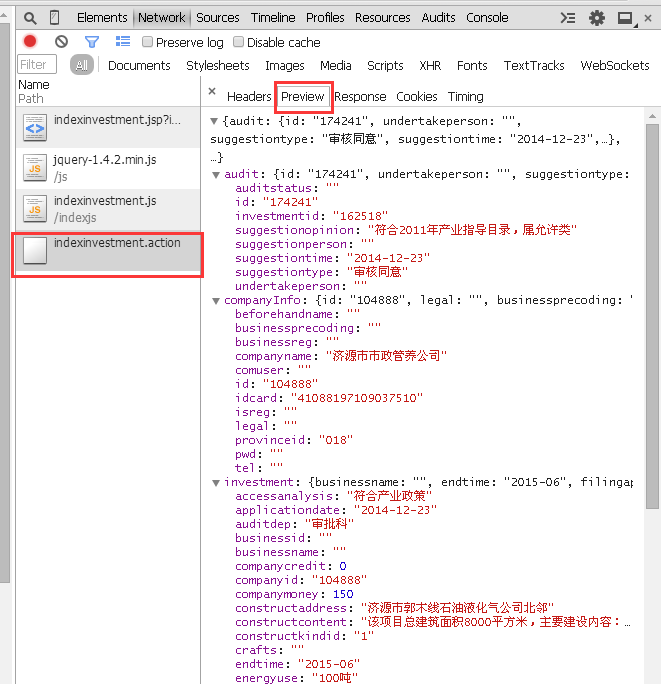
然而,双击打开此文件并不能获得企业信息,而是一堆代码。因为没有对应的参数为它指明要显示第几号的信息。如图:

那么,应该如何将参数传递给它呢?这时我们仍旧看F12窗口:
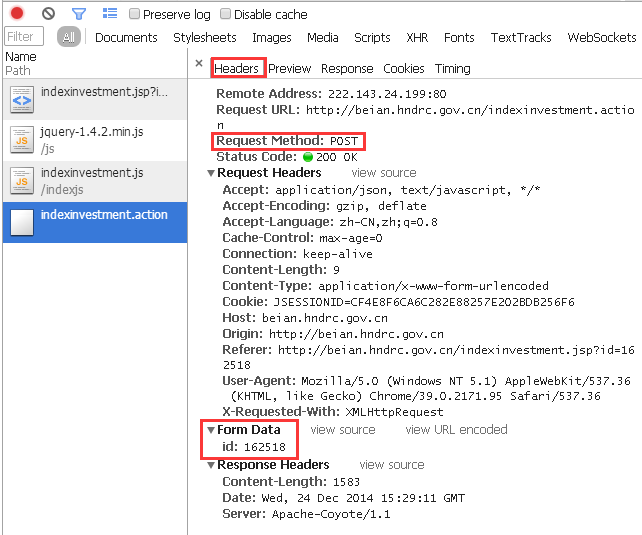
“Header”一栏中明确地显示出了此次响应的过程:
对目标URL,用POST的方式,传递了一个id为162518的参数。
我们先手工操作一下。js是如何调用参数的呢?对,上面说过:问号+变量名+等号+变量对应的数字。也就是说,向“http://beian.hndrc.gov.cn/indexinvestment.action”这个页面提交id为162518的参数时,应该在URL后面加上
“?id=162518”,即
“http://beian.hndrc.gov.cn/indexinvestment.action?id=162518”。
我们把这个URL粘贴到浏览器中来看:

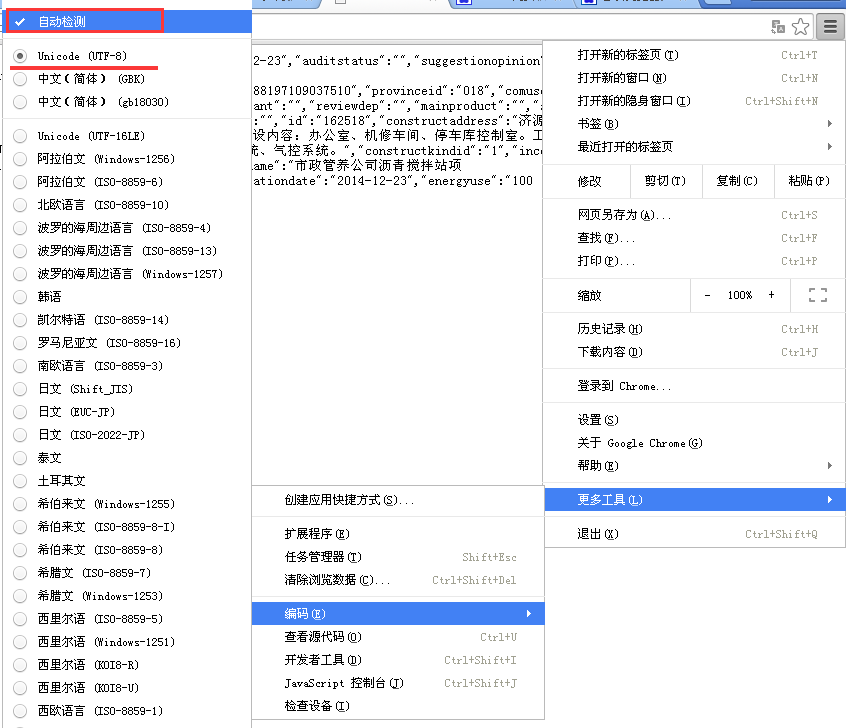
似乎有了点内容,可是都是乱码啊,怎么破?熟悉的朋友可能一眼就看出来,这是编码的问题。是因为响应回来的内容与浏览器默认的编码方式不同。只需要在Chrome右上角菜单——更多工具——编码——“自动检测”即可。(其实这是UTF-8的编码,而Chrome默认的是中文简体)。如下图:
好了,真正的信息源已经被挖出,剩下的就是用Python处理这些页面上的字符串,然后剪切、拼接,重新组成新的《项目备案书》了。
再然后使用for、while等循环,批量获取这些《备案书》。
正如“不论是静态网页,动态网页,模拟登陆等,都要先分析、搞懂逻辑,再去写代码”所说,编程语言只是一个工具,重要的是解决问题的思路。有了思路,再寻找趁手的工具去解决,就OK了。
相关推荐
-

Python使用tablib生成excel文件的简单实现方法
本文实例讲述了Python使用tablib生成excel文件的方法.分享给大家供大家参考,具体如下: import tablib headers = ('lie1', 'lie2', 'lie3', 'lie4', 'lie5') mylist = [('23','23','34','23','34'),('sadf','23','sdf','23','fsad')] mylist = tablib.Dataset(*mylist, headers=headers) with open('exc
-
Python实现抓取网页并且解析的实例
本文以实例形式讲述了Python实现抓取网页并解析的功能.主要解析问答与百度的首页.分享给大家供大家参考之用. 主要功能代码如下: #!/usr/bin/python #coding=utf-8 import sys import re import urllib2 from urllib import urlencode from urllib import quote import time maxline = 2000 wenda = re.compile("href=\"htt
-
Python实现导出数据生成excel报表的方法示例
本文实例讲述了Python实现导出数据生成excel报表的方法.分享给大家供大家参考,具体如下: #_*_coding:utf-8_*_ import MySQLdb import xlwt from datetime import datetime def get_data(sql): # 创建数据库连接. conn = MySQLdb.connect(host='127.0.0.1',user='root'\ ,passwd='123456',db='test',port=3306,char
-
python通过openpyxl生成Excel文件的方法
本文实例讲述了python通过openpyxl生成Excel文件的方法.分享给大家供大家参考.具体如下: 使用前请先安装openpyxl: easy_install openpyxl 通过这个模块可以很方便的导出数据到Excel from openpyxl.workbook import Workbook from openpyxl.writer.excel import ExcelWriter from openpyxl.cell import get_column_letter from o
-
python 自动提交和抓取网页
下面是用python写的,使用lxml来做html分析,从网上看到的,说是分析速度最快的哦,不过没有验证过.好了,上代码. 复制代码 代码如下: import urllib import urllib2 import urlparse import lxml.html def url_with_query(url, values): parts = urlparse.urlparse(url) rest, (query, frag) = parts[:-2], parts[-2:] return
-
python抓取网页图片并放到指定文件夹
python抓取网站图片并放到指定文件夹 复制代码 代码如下: # -*- coding=utf-8 -*-import urllib2import urllibimport socketimport osimport redef Docment(): print u'把文件存在E:\Python\图(请输入数字或字母)' h=raw_input() path=u'E:\Python\图'+str(h) if not os.path.exists(path):
-
python抓取网页中图片并保存到本地
在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情. #-*-coding:utf-8-*- import os import uuid import urllib2 import cookielib '''获取文件后缀名''' def get_file_extension(file): return os.path.splitext(file)[1] '''創建文件目录,并返回该目录''' def mkdir(path): # 去除左右两边的
-
python 读取excel文件生成sql文件实例详解
python 读取excel文件生成sql文件实例详解 学了python这么久,总算是在工作中用到一次.这次是为了从excel文件中读取数据然后写入到数据库中.这个逻辑用java来写的话就太重了,所以这次考虑通过python脚本来实现. 在此之前需要给python添加一个xlrd模块,这个模块是专门用来操作excel文件的. 在mac中可以通过easy_install xlrd命令实现自动安装模块 import xdrlib ,sys import xlrd def open_excel(fil
-
Python实现抓取网页生成Excel文件的方法示例
本文实例讲述了Python实现抓取网页生成Excel文件的方法.分享给大家供大家参考,具体如下: Python抓网页,主要用到了PyQuery,这个跟jQuery用法一样,超级给力 示例代码如下: #-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行
-
python抓取网页图片示例(python爬虫)
复制代码 代码如下: #-*- encoding: utf-8 -*-'''Created on 2014-4-24 @author: Leon Wong''' import urllib2import urllibimport reimport timeimport osimport uuid #获取二级页面urldef findUrl2(html): re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?<!photos).tuchong.co