python中Pycharm 输出中文或打印中文乱码现象的解决办法
1. 确保文件开头加上以下代码:
# -*- coding:utf-8 -*-
还可以加上
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
确保以下。
如果还是没有解决中文乱码,那么进行方法2.
2. 进入setting

单击打开,单击
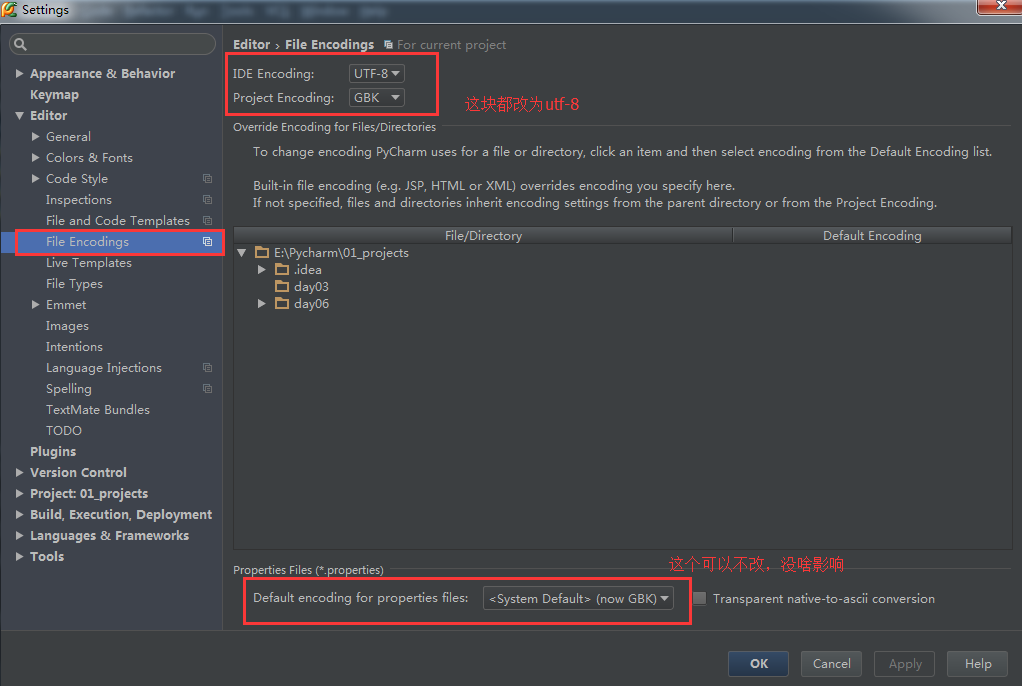
修改完成后,结果如下

单击“ok”。
成功。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python开发环境PyScripter中文乱码问题解决方案
PyScripter看起来还是挺不错的一个python ide 环境: PyScripter 2.6.0.0 python3.4 问题: PyScripter有个小坑,打开文件后中文都成了乱码.在PyScripter中新建的文件中文可以正常显示,但是重新打开后中文乱码. PyScripter中文乱码原因: 原因是如果文件头部没有编码声明,那么PyScripter会默认使用ANSI打开文件. 而PyScripter默认的文件模板也不带编码声明,重新打开文件时间不以UTF-8打开,所以乱码. 解决的
-
解决python2.7 查询mysql时出现中文乱码
问题: python2.7 查询或者插入中文数据在mysql中的时候出现中文乱码 --- 可能情况: 1.mysql数据库各项没有设置编码,默认为'latin' 2.使用MySQL.connect的时候没有设置默认编码 3.没有设置python的编码,python2.7默认为'ascii' 4.没有解码 --- 解决方法: 1.设置mysql的编码 ubuntu执行下列语句: ** sudo vim /etc/mysql/my.cnf ** 然后在里面插入语句: [client] default
-
python解决Fedora解压zip时中文乱码的方法
前言 很多时候在windows下压缩文件没问题,但是到了Linux下,出现乱码,很常见.以前在Ubuntu下,用`unzip -O GBK filename.zip` 就可以搞定. 换了Fedora后,暂时没发现乱码的压缩文件.晚上下载一本书的光盘,又碰到了乱码.尝试之前的方法没成功.看了下unzip的help,没-O那个参数了== 刚好找到一个用python解决的办法,分享下. 新建一个`.py`后缀的文件,直接复制粘贴代码: #!/usr/bin/env python # -*- codin
-
wxPython窗口中文乱码解决方法
本文实例讲述了wxPython窗口中文乱码解决方法,分享给大家供大家参考.具体方法如下: 文件保存为 utf-8 文件开头添加 # -*- coding: utf-8 -*- 在有中文字符串前加u或U,例如:u"我的网站:http://www.jb51.net" 示例如下: 复制代码 代码如下: # -*- coding: utf-8 -*- import wx class App(wx.App): def OnInit(self): frame = wx.
-
python查询mysql中文乱码问题
问题: python2.7 查询或者插入中文数据在mysql中的时候出现中文乱码 --- 可能情况: 1.mysql数据库各项没有设置编码,默认为'latin' 2.使用MySQL.connect的时候没有设置默认编码 3.没有设置python的编码,python2.7默认为'ascii' 4.没有解码 --- 解决方法: 1.设置mysql的编码 ubuntu执行下列语句: ** sudo vim /etc/mysql/my.cnf ** 然后在里面插入语句: [client] default
-
python中文乱码的解决方法
乱码原因:源码文件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了! 解决方法:1.print mystr.decode('utf-8').encode('gbk')2.比较通用的方法: 复制代码 代码如下: import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)
-
python 采集中文乱码问题的完美解决方法
近几日遇到采集某网页的时候大部分网页OK,少部分网页出现乱码的问题,调试了几日,终于发现了是含有一些非法字符造成的..特此记录 1. 在正常情况下..可以用 import chardet thischarset = chardet.detect(strs)["encoding"] 来获取该文件或页面的编码方式 或直接抓取页面的charset = xxxx 来获取 2. 遇到内容中有特殊字符时指定的编码一样会造成乱码..即内容中非法字符造成的,可以采用编码忽略非法字符的方式来处理. st
-

python 中文乱码问题深入分析
在本文中,以'哈'来解释作示例解释所有的问题,"哈"的各种编码如下: 1. UNICODE (UTF8-16),C854: 2. UTF-8,E59388: 3. GBK,B9FE. 一.python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢? 在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为 u'\u54c8
-
Python2.x中文乱码问题解决方法
Python中乱码问题是一个很头痛的问题. 在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文.否则会出现乱码 [问题原因] 在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码.Python默认采取的ASCII编码,字母.标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求. 复制代码 代码如下: >>> import sys >>> sys.getdefaultencoding
-
关于backbone url请求中参数带有中文存入数据库是乱码的快速解决办法
最近项目用到了backbone 做前后端的分离方案,遇见了中文乱码问题,解决方案总结如下: 假设需要存一条课程记录到后台 model定义如下: var AddCourse= Backbone.Model.extend({ url:path+"/course/add", parse : function(response){ return response.data; } }); encodeURIComponent 函数 将中文的内容进行编码 $('#addCourseBtn' ).c
-
python中Pycharm 输出中文或打印中文乱码现象的解决办法
1. 确保文件开头加上以下代码: # -*- coding:utf-8 -*- 还可以加上 import sys reload(sys) sys.setdefaultencoding('utf-8') 确保以下. 如果还是没有解决中文乱码,那么进行方法2. 2. 进入setting 单击打开,单击 修改完成后,结果如下 单击"ok". 成功. 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.
-
JS中页面与页面之间超链接跳转中文乱码问题的解决办法
在原页面一张图片上添加了一个链接,链接中有中文,于是出现下面的情况: 解决办法是在tomcat的server.xml文件的中加入URIEncoding="utf-8",如下: <Connector URIEncoding="utf-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443&q
-
用ajax传递json到前台中文出现问号乱码问题的解决办法
我使用的Springmvc,在controller层传输一个json到前台,后台显示没问题,中文正常显示而到了前台 中文就变成了问号. 后来发现,因为在controller中返回json用了@ResponseBody,而spring源码中@ResponseBody 的实现类发现其默认的编码是 iso-8859-1,而项目用的编码为utf-8,所以传中文会出现乱码. 这里我使用了注解来解决: @RequestMapping(value="/echarts.do", produces =
-
Ajax传输中文乱码问题的解决办法
AJAX简介 AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML). AJAX 不是新的编程语言,而是一种使用现有标准的新方法. AJAX 是与服务器交换数据并更新部分网页的艺术,在不重新加载整个页面的情况下. ajax传输中文乱码问题描述: 我是在一个jsp页面有一个保存按钮,点击时会触发saveForm()的js函数,在saveForm()函数里经过校验后,会通过ajax发送数据请求,这样就不用通过提交表单来传输数据了,aj
-
jQuery使用serialize()表单序列化时出现中文乱码问题的解决办法
序列化中文时之所以乱码是因为.serialize()调用了encodeURLComponent方法将数据编码了 解决方法就是进行解码 原因:.serialize()自动调用了encodeURIComponent方法将数据编码了 解决方法:调用decodeURIComponent(XXX,true);将数据解码 例如: var params = jQuery("#formId").serialize(); // http request parameters. params = deco
-
Android Retrofit 中文乱码问题的解决办法
Android Retrofit 中文乱码问题的解决办法 使用retrofit和rxjava,提交数据时需注意,当数据中有中文时,传到后台,可能会是乱码,需处理: 解决: 1.GET请求改成POST; 2.参数Field改成Query 3.加上@FormUrlEncoded 如下: @FormUrlEncoded @POST("/test/test") Call<Response> register(@Field("name") String name)
-
在Ajax中使用get和post所遇到的问题及解决办法
使用get遇到的问题: 1.问题一. 缓存:当每次访问的url相同,客户端直接读取本地缓存里面的内容,即使后台数据变化前台也不会有变化: 解决方法:在?后面链接一个num=[随机数Math.random()]或者num=[时间戳new Date().getTime()],'1.php?username="May"&'+num(这里没有变量名,避免和后台参数冲突) 2.问题二. 乱码,当传递中文或者特殊字符的时候,前台显示出现乱码 解决办法:使用编码encodeURI('蜗牛')
-
Pycharm虚拟环境pip时报错:no suchoption:--bulid-dir的解决办法
目录 创作背景 讲解 解决办法 注 结尾 创作背景 最近本人在 PyCharm 的虚拟环境安装第三方库的时候报了错,说 no such option: --bulid-dir ,如下图所示: 这是怎么回事呢? 讲解 PyCharm 依赖于 --build-dir 安装第三方库,但该标志在 20.2 版本以后的版中已被删除. 解决办法 命令行中切换到虚拟环境的路径,并使用 activate 切换为虚拟环境.输入命令 python -m pip install pip==20.2.4 来切换 pip
-
python抓取并保存html页面时乱码问题的解决方法
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法.分享给大家供大家参考,具体如下: 在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问题.出现该问题的原因一方面是自己的代码中编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码和标示的编码不符合造成的.html页面标示的编码在这里: 复制代码 代码如下: <meta http-equiv="Content-Type" content="text/html;