SQL select distinct的使用方法
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 distinct用于返回唯一不同的值。
表A:
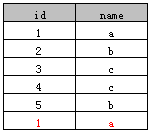
示例1
select distinct name from A
执行后结果如下:

示例2
select distinct name, id from A
执行后结果如下:

实际上是根据“name+id”来去重,distinct同时作用在了name和id上,这种方式Access和SQL Server同时支持。
示例3:统计
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持
select count(distinct name, id) from A; --SQL Server和Access都不支持
示例4
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
其他
distinct语句中select显示的字段只能是distinct指定的字段,其他字段是不可能出现的。例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。
但可以通过其他方法实现关于SQL Server将一列的多行内容拼接成一行的问题讨论
相关推荐
-

SQL中distinct的用法(四种示例分析)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只 用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的,所以浪费了我大量时间. 在表中,可能会包含重复值.这并不成问题,不过,有时您也许希
-
distinct 多列问题结合group by的解决方法
表 table1 id RegName PostionSN PersonSN 1 山东齐鲁制药 223 2 2 山东齐鲁制药 224 2 3 北京城建公司 225 2 4 科技公司 225 2 我想获得结果是 id RegName PostionSN PersonSN 1 山东齐鲁制药 223 2 3 北京城建公司 225 2 4 科技公司 225 2 select distinct RegName,PostionSN,PersonSN from table1 如果查询的是多列 distinct
-
使用GROUP BY的时候如何统计记录条数 COUNT(*) DISTINCT
例如这样一个表,我想统计email和passwords都不相同的记录的条数 复制代码 代码如下: CREATE TABLE IF NOT EXISTS `test_users` ( `email_id` int(11) unsigned NOT NULL auto_increment, `email` char(100) NOT NULL, `passwords` char(64) NOT NULL, PRIMARY KEY (`email_id`) ) ENGINE=MyISAM DEFAUL
-
针对distinct疑问引发的一系列思考
有人提出了这样一个问题,整理出来给大家也参考一下 假设有如下这样一张表格: 这里的数据,具有如下的特征:在一个DepartmentId中,可能会有多个Name,反之也是一样.就是说Name和DepartmentId是多对多的关系. 现在想实现这样一个查询:按照DepartmentID排完序之后(第一步),再获取Name列的不重复值(第二步),而且要保留在第一步后的相对顺序.以本例而言,应该返回三个值依次是:ACB 我们首先会想到下面这样一个写法 select distinct name from
-
使用distinct在mysql中查询多条不重复记录值的解决办法
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的.所以我花了很多时间来研究这个问题,网上也查不到解决方案,期间把容容拉来帮忙,结果是
-
mongodb中使用distinct去重的简单方法
MongoDB的destinct命令是获取特定字段中不同值列表.该命令适用于普通字段,数组字段和数组内嵌文档. mongodb的distinct的语句: 复制代码 代码如下: db.users.distinct('last_name') 等同于 SQL 语句: 复制代码 代码如下: select DISTINCT last_name from users 表示的是根据指定的字段返回不同的记录集. 一个简单的实例: // > db.addresses.insert({"zip-code&qu
-
sqlserver中distinct的用法(不重复的记录)
下面先来看看例子: table表 字段1 字段2 id name 1 a 2 b 3 c 4 c 5 b 库结构大概这样,这只是一个简单的例子,实际情况会复杂得多. 比如我想用一条语句查询得到name不重复的所有数据,那就必须 使用distinct去掉多余的重复记录. select distinct name from table得到的结果是: ---
-
为何Linq的Distinct实在是不给力
假设我们有一个类:Productpublic class Product{ public string Id { get; set; } public string Name { get; set; }}Main函数如下:static void Main(){ List<Product> products = new List<Product>() { new Product(){ Id="1", Name="n1
-
oracle sql 去重复记录不用distinct如何实现
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外distinct关键字会排序,效率很低 . select distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值. select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录 所以用distinct达不到想要的效果,用group by 可以解决这个问题. 例如要显示的字
-
oracle中distinct的用法详解
下面先来看看例子: table表 字段1 字段2 id name 1 a 2 b 3 c 4 c 5 b 库结构大概这样,这只是一个简单的例子,实际情况会复杂得多. 比如我想用一条语句查询得到name不重复的所有数据,那就必须使用distinct去掉多余的重复记录. select distinct name from table 得到的结果
-
MongoDB教程之聚合(count、distinct和group)
1. count: 复制代码 代码如下: --在空集合中,count返回的数量为0. > db.test.count() 0 --测试插入一个文档后count的返回值. > db.test.insert({"test":1}) > db.test.count() 1 > db.test.insert({"test":2}) > db.test.count() 2
-
解析mysql中:单表distinct、多表group by查询去除重复记录
单表的唯一查询用:distinct多表的唯一查询用:group bydistinct 查询多表时,left join 还有效,全连接无效,在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重复记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的