PostgreSQL之分区表(partitioning)
PostgreSQL有一项非常有用的功能,分区表,或者partitioning。当某个TABLE的记录非常的多,千万甚至更多的时候,我们其实需要将他分割成子表。一个庞大的TABLE,就像水果仓库杂乱无章地堆放着无数的苹果桃子和桔子,查找不方便,性能降低,比较合理的做法是将仓库分成三个子区域,分表放苹果桃子和桔子。一张大表就变成了三个小表的集合。
通过合理的设计,可以将选择一定的规则,将大表切分多个不重不漏的子表,这就是传说中的partitioning。比如,我们可以按时间切分,每天一张子表,比如我们可以按照某其他字段分割,总之了就是化整为零,提高查询的效能。
怎么实现这个分区表的功能呢?
1 建立大表。
2 创建分区继承
3 定义Rule或者Trigger?
下面根据一个简单的例子,描述这个过程。我们将学生按照低于60分和不低于60分切分成两张子表。
1 建立大表
CREATE TABLE student (student_id bigserial, name varchar(32), score smallint)
2 创建分区继承。
CREATE TABLE student_qualified (CHECK (score >= 60 )) INHERITS (student) ; CREATE TABLE student_nqualified (CHECK (score < 60)) INHERITS (student) ;
创建了两个分区表,student_qualified和student_nqualified,继承了大表student的一切字段,同时设定了约束,即CHECK条件。
3 定义Rule或者Trigger。
虽然我们定义了CHECK条件,但是往student插入数据时,PostgreSQL并不能根据score是否低于60插入的正确的子表,原因是,你并没有定义这种规则,来告诉数据这么做。我们需要定义Rule或者Trigger,将数据插入到正确的分区表。
先看下Rule的定义:
CREATE OR REPLACE RULE insert_student_qualified
AS ON INSERT TO student
WHERE score >= 60
DO INSTEAD
INSERT INTO student_qualified VALUES(NEW.*);
CREATE OR REPLACE RULE insert_student_nqualified
AS ON INSERT TO student
WHERE score < 60
DO INSTEAD
INSERT INTO student_nqualified VALUES(NEW.*);
这两个Rule告诉了PostgreSQL,当往总表插数据的时候,如果是score< 60,则插入student_nqualified,如果score>=60,则插入student_qualified.注意了,这个分割一定要不重不漏,如果我们不小心将>=60条件的“=”丢掉,等于60分的记录将会录入大表student,不在任何一个分区表中。
我们插入一些记录:
INSERT INTO student (name,score) VALUES('Jim',77);
INSERT INTO student (name,score) VALUES('Frank',56);
INSERT INTO student (name,score) VALUES('Bean',88);
INSERT INTO student (name,score) VALUES('John',47);
INSERT INTO student (name,score) VALUES('Albert','87');
INSERT INTO student (name,score) VALUES('Joey','60');
我们看下数据分布情况,是否分布到了正确的的分区表:
SELECT p.relname,c.tableoid,c.* FROM student c, pg_class p WHERE c.tableoid = p.oid
输出如下:
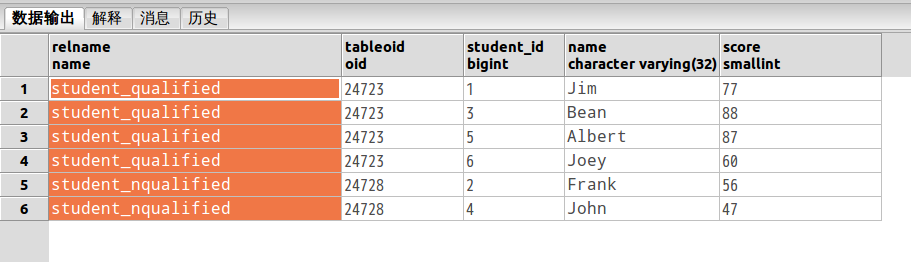
我们看到,虽然我们插入的是大表,但是数据却存在了对应的分区子表。符合我们的期望。同时还不影响查询。
Rule是一个分流的办法,还有TRIGGER也能做到让正确的数据流向正确的分区子表。
首先我们定义个function。
CREATE OR REPLACE FUNCTION student_insert_trigger()
RETURNS TRIGGER AS
$$
BEGIN
IF(NEW.score >= 60) THEN
INSERT INTO student_qualified VALUES (NEW.*);
ELSE
INSERT INTO student_nqualified VALUES (NEW.*);
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql ;
然后定义TRIGGER,当插入到student之前,就会触发trigger:
CREATE TRIGGER insert_student BEFORE INSERT ON student FOR EACH row EXECUTE PROCEDURE student_insert_trigger() ;
我们首先通过删除TABLE student,测试下trigger方式。
DROP TABLE STUDENT CASCADE CREATE TABLE student (student_id bigserial, name varchar(32), score smallint) ; CREATE TABLE student_qualified (CHECK (score >= 60 )) INHERITS (student) ; CREATE TABLE student_nqualified (CHECK (score < 60)) INHERITS (student) ;
然后执行定义FUNCTION和定义TRIGGER的语句。就可以查看了。
为了确认我们的触发器的确触发了,我们打开存储过程的统计开关:
在postgresql.conf中,找到track_functions,改成all
track_functions = all
插入之前先看下function student_insert_trigger的统计信息:

执行插入:
INSERT INTO student (name,score) VALUES('Jim',77);
INSERT INTO student (name,score) VALUES('Frank',56);
INSERT INTO student (name,score) VALUES('Bean',88);
INSERT INTO student (name,score) VALUES('John',47);
INSERT INTO student (name,score) VALUES('Albert','87');
INSERT INTO student (name,score) VALUES('Joey','60');
插入后,看下function student_insert_trigger的统计信息

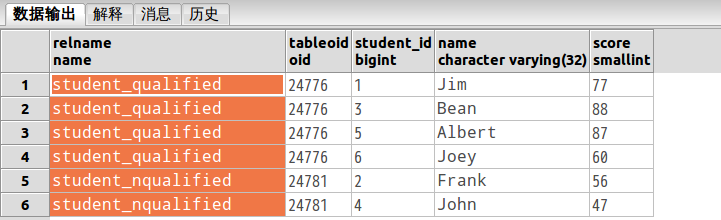
我们看到trigger触发了6次。
执行下查询:
SELECT p.relname,c.tableoid,c.* FROM student c, pg_class p WHERE c.tableoid = p.oid
输出如下:
参考文献
相关推荐
-

PostgreSQL分区表(partitioning)应用实例详解
前言 项目中有需求要垂直分表,即按照时间区间将数据拆分到n个表中,PostgreSQL提供了分区表的功能.分区表实际上是把逻辑上的一个大表分割成物理上的几小块,提供了很多好处,比如: 1.查询性能大幅提升 2.删除历史数据更快 3.可将不常用的历史数据使用表空间技术转移到低成本的存储介质上 那么什么时候该使用分区表呢?官方给出的指导意见是:当表的大小超过了数据库服务器的物理内存大小则应当使用分区表,接下来结合一个例子具体记录一下创建分区表的详细过程. 创建分区表 首先看一下需求,现在有一张日志表
-
PostgreSQL之分区表(partitioning)
PostgreSQL有一项非常有用的功能,分区表,或者partitioning.当某个TABLE的记录非常的多,千万甚至更多的时候,我们其实需要将他分割成子表.一个庞大的TABLE,就像水果仓库杂乱无章地堆放着无数的苹果桃子和桔子,查找不方便,性能降低,比较合理的做法是将仓库分成三个子区域,分表放苹果桃子和桔子.一张大表就变成了三个小表的集合. 通过合理的设计,可以将选择一定的规则,将大表切分多个不重不漏的子表,这就是传说中的partitioning.比如,我们可以按时间切分,每天一张子表,比如
-
PostgreSQL 10分区表及性能测试报告小结
目录 一. 测试环境 二. 编译安装PostgreSQL 10 range分区表 list分区表 多级分区表 使用ALTER TABLE xxx ATTACH[DETACH] PARTITION 增加或删除分区 添加外部表作为分区表 四.建立测试业务表 五.性能测试 数据导入 查询某个时间范围的数据 查询某个月里某个用户数据--直接从cache里取数据 索引维护 删除整个分区数据 全表扫描 增加新的分区并导入数据 作者简介: 中国比较早的postgresql使用者,2001年就开始使用postg
-
PostgreSQL怎么创建分区表详解
目录 前言 列分区表 范围分区表 总结 前言 PG 假如我们想像Hive那也创建动态分区是不能实现的. 那么需要我们手动通过脚本来创建分区表,创建分区表必须要创建主表和分区表. 因此我们可以根据我们需求提前用脚本把分区表生成即可,也可以用触发器来实现. 主表:定义我们的一些约束,以及分区键,实质上不存储数据 分区表:主要是用来存储数据的.所有列及约束都跟随主表 注意:如果我们指定分区表不存在会报错,因此一定要提前创建好分区表,并且要数据不能有遗漏的分区键. 列分区表 就是我们指定
-
PostgreSQL教程(三):表的继承和分区表详解
一.表的继承: 这个概念对于很多已经熟悉其他数据库编程的开发人员而言会多少有些陌生,然而它的实现方式和设计原理却是简单易懂,现在就让我们从一个简单的例子开始吧. 1. 第一个继承表: 复制代码 代码如下: CREATE TABLE cities ( --父表 name text, population float, altitude int ); CREATE TABLE capitals (
-
MySQL分区表的局限和限制详解
禁止构建 分区表达式不支持以下几种构建: 存储过程,存储函数,UDFS或者插件 声明变量或者用户变量 可以参考分区不支持的SQL函数 算术和逻辑运算符 分区表达式支持+,-,*算术运算,但是不支持DIV和/运算(还存在,可以查看Bug #30188, Bug #33182).但是,结果必须是整形或者NULL(线性分区键除外,想了解更多信息,可以查看分区类型). 分区表达式不支持位运算:|,&,^,<<,>>,~ . HANDLER语句 在MySQL 5.7.1之前的分区表不
-
ORACLE 分区表的设计
分区表的概念 分区致力于解决支持极大表和索引的关键问题.它采用他们分解成较小和易于管理的称为分区的片(piece)的方法.一旦分区被定义,SQL语句就可以访问的操作某一个分区而不是整个表,因而提高管理的效率.分区对于数据仓库应用程序非常有效,因为他们常常存储和分析巨量的历史数据. 分区表的分类 Range partitioning(范围分区) Hash partitioning(哈希分区) List partitioning(列表分区) Composite range-hash partitio
-
Mysql分区表的管理与维护
改变一个表的分区方案只需使用alter table 加 partition_options 子句就可以了.和创建分区表时的create table语句很像. 创建表 CREATE TABLE trb3 (id INT, name VARCHAR(50), purchased DATE) PARTITION BY RANGE( YEAR(purchased) ) ( PARTITION p0 VALUES LESS THAN (1990), PARTITION p1 VALUES LESS THA
-
通过实例学习MySQL分区表原理及常用操作
1.分区表含义 分区表定义指根据可以设置为任意大小的规则,跨文件系统分配单个表的多个部分.实际上,表的不同部分在不同的位置被存储为单独的表.用户所选择的.实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数. 分表与分区的区别在于:分区从逻辑上来讲只有一张表,而分表则是将一张表分解成多张表 2.分区表优点 1)分区表更容易维护.对于那些已经失去保存意义的数据,通常可以通过删除与那些数据
-
postgresql 按小时分表(含触发器)的实现方式
本人后端开发,因为业务需求需要使用分表方式进行数据存储.结合网上的资料最后使用的以下方式: CREATE OR REPLACE FUNCTION auto_insert_into_tbl_partition() RETURNS trigger AS $BODY$ DECLARE time_column_name text ; -- 父表中用于分区的时间字段的名称[必须首先初始化!!] curMM varchar(16); -- 'YYYYMM'字串,用做分区子表的后缀 isExist boole