MongoDB特定类型的查询语句实例
目录
- null
- 正则表达式
- 查询数组
- “$all”
- “$size”
- “$slice”
- 返回一个匹配的数组元素
- 数组与范围查询的相互作用
- 查询内嵌文档
- 总结
MongoDB 在一个文档中可以使用多种类型的数据,其中一些类型在查询时会有特别的行为。
null
null 的行为有一些特别。它可以与自身匹配,所以如果有一个包含如下文档的集合:
> var documents = [
... {_id: 1, y: null},
... {_id: 2, y: 1},
... {_id: 3, y: 2}
... ]
> db.myCollection.insertMany(documents)
{ "acknowledged" : true, "insertedIds" : [ 1, 2, 3 ] }

那么可以按照预期的方式查询 “y” 键为 null 的文档:
> db.myCollection.find({y: null})

不过,null 同样会匹配“不存在”这个条件。因此,对一个键进行 null 值的请求还会返回缺少这个键的所有文档:
> db.myCollection.find({x: null})

如果仅想匹配键值为 null 的文档,则需要检查该键的值是否为 null,并且通过 "$exists"条件确认该键已存在。
> db.myCollection.find({x: {$eq: null, $exists: true}})

正则表达式
“$regex” 可以在查询中为字符串的模式匹配提供正则表达式功能。正则表达式对于灵活的字符串匹配非常有用。如果要查找所有用户名为 Joe 或 joe 的用户,那么可以使用正则表达式进行不区分大小写的匹配:
> db.users.find({name: {$regex: /joe/i}})
可以在正则表达式中使用标志(如 i),但这没有强制要求。如果除了匹配各种大小写组合形式的“joe”之外,还希望匹配如“joey”这样的键,那么可以改进一下刚刚的正则表达式:
> db.users.find({name: {$regex: /joey?/i}})
MongoDB 会使用 Perl 兼容的正则表达式(PCRE)库来对正则表达式进行匹配。任何PCRE 支持的正则表达式语法都能被 MongoDB 接受。在查询中使用正则表达式之前,最好先在 JavaScript shell 中检查一下语法,这样可以确保匹配与预想的一致。
MongoDB 可以利用索引来查询前缀正则表达式(如 /joey/)。索引不能用于不区分大小写的搜索(/joey/i)。当正则表达式以插入符号(^)或左锚点(\A)开头时,它就是“前缀表达式”。如果正则表达式使用了区分大小写的查询,那么当字段存在索引时,则可以对索引中的值进行匹配。如果它也是一个前缀表达式,那么可以将搜索限制在由该索引的前缀所形成的范围内的值。
正则表达式也可以匹配自身。虽然很少有人会将正则表达式插入数据库中,但是如果你这么做了,那么它也可以匹配到自身。
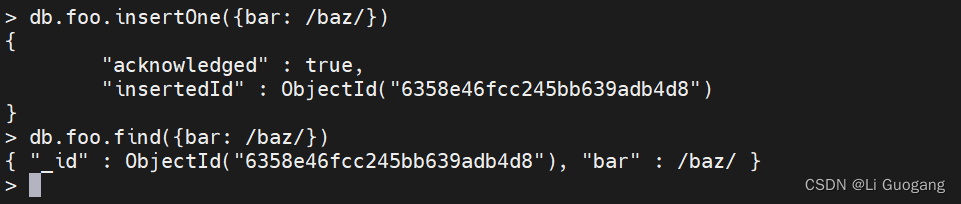
查询数组
查询数组元素的方式与查询标量值相同。假设有一个数组是水果列表,如下所示:
> db.food.insertOne({fruit: ["apple", "banana", "peach"]})
{
"acknowledged" : true,
"insertedId" : ObjectId("6358e513cc245bb639adb4d9")
}
则下面的查询可以成功匹配到该文档:
> db.food.find({fruit: "banana"}).pretty()

这个查询就好像对一个这样的(不合法)文档进行查询:{“fruit” : “apple”, “fruit” :“banana”, “fruit” : “peach”}。
“$all”
如果需要通过多个元素来匹配数组,那么可以使用 “$all”。这允许你匹配一个元素列表。假设我们创建了一个包含 3 个元素的集合:
> db.food.insertMany([
... {_id: 1, fruit: ["apple", "banana", "peach"]},
... {_id: 2, fruit: ["apple", "kumquat", "orange"]},
... {_id: 3, fruit: ["cherry", "banana", "apple"]}
... ])
{ "acknowledged" : true, "insertedIds" : [ 1, 2, 3 ] }
> db.food.find().pretty()
{ "_id" : 1, "fruit" : [ "apple", "banana", "peach" ] }
{ "_id" : 2, "fruit" : [ "apple", "kumquat", "orange" ] }
{ "_id" : 3, "fruit" : [ "cherry", "banana", "apple" ] }
可以使用 “$all” 查询来找到同时包含元素 “apple” 和 “banana” 的文档:
> db.food.find({fruit: {$all: ["apple", "banana"]}})

这里的顺序无关紧要。注意,上面第二个结果中的 “banana” 在 “apple” 之前。如果在" a l l " 中使用只有一个元素的数组,那么这个效果和不使用 " all" 中使用只有一个元素的数组,那么这个效果和不使用 " all"中使用只有一个元素的数组,那么这个效果和不使用"all" 是一样的。例如,{fruit : {$all : [‘apple’]} 和 {fruit : ‘apple’} 会匹配相同的文档。
也可以使用整个数组进行精确匹配。不过,精确匹配无法匹配上元素丢失或多余的文档。
例如,下面这样可以匹配之前的第一个文档:
> db.food.find({fruit: ["apple", "banana", "peach"]})

但是下面这样就不行:
> db.food.find({"fruit" : ["apple", "banana"]})
这样也无法匹配:
> db.food.find({"fruit" : ["banana", "apple", "peach"]})
如果想在数组中查询特定位置的元素,可以使用 key.index 语法来指定下标:
> db.food.find({"fruit.2": "peach"})

数组下标都是从 0 开始的,因此这个语句会用数组的第 3 个元素与字符串 “peach” 进行匹配。
“$size”
“$size” 条件运算符对于查询数组来说非常有用,可以用它查询特定长度的数组,如下所示。
> db.food.find({fruit: {$size: 3}})

一种常见的查询是指定一个长度范围。“$size” 并不能与另一个 $ 条件运算符(如"$gt")组合使用,但这种查询可以通过在文档中添加一个 “size” 键的方式来实现。之后每次向指定数组添加元素时,同时增加 “size” 的值。如果原本的更新是这样:
> db.food.update({fruit: {$all: ["apple", "banana"]}}, {$push: {fruit: "strawberry"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.food.find()
{ "_id" : 1, "fruit" : [ "apple", "banana", "peach", "strawberry" ] }
{ "_id" : 2, "fruit" : [ "apple", "kumquat", "orange" ] }
{ "_id" : 3, "fruit" : [ "cherry", "banana", "apple" ] }
那么可以很容易地转换成这样:
> db.food.update({fruit: {$all: ["apple", "banana"]}},
... {$push: {fruit: "strawberry"}, $inc: {size: 1}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })

自增操作的速度非常快,因此任何性能损失都可以忽略不计。这样存储文档后就可以执行如下查询:
> db.food.find({size: {$eq: 1}})

很遗憾,这种技巧无法与 “$addToSet” 运算符联合使用。
“$slice”
“$slice” 运算符可以返回一个数组键中元素的子集。
假设现在有一个关于博客文章的文档,我们希望返回前 10 条评论:
> db.blog.findOne(criteria, {"comments" : {"$slice" : 10}})
同样,如果想返回后 10 条评论,则可以使用 -10:
> db.blog.findOne(criteria, {"comments" : {"$slice" : -10}})
“$slice” 也可以指定偏移量和返回的元素数量来获取数组中间的结果:
> db.blog.findOne(criteria, {"comments" : {"$slice" : [23, 10]}})
这个操作会略过前 23 个元素,返回第 24~33 个元素。如果数组中的元素少于 33 个,则会返回尽可能多的元素。
除非特别指定,否则在使用 “$slice” 时会返回文档中的所有键。
可以使用 “$slice” 来获取最后一条评论,如下所示:
> db.blog.findOne(criteria, {"comments" : {"$slice" : -1}})
返回一个匹配的数组元素
如果知道数组元素的下标,那么 “$slice” 非常有用。但有时我们希望返回与查询条件匹配的任意数组元素。这时可以使用 $ 运算符来返回匹配的元素。对于前面的博客文章示例,可以这样获得 Bob 的评论:
> db.blog.find({"comments.name": "bob"}, {"comments.$": 1})
注意,这种方式只会返回每个文档中第一个匹配的元素:如果 Bob 在这篇博客中留下了多条评论,那么只有 “comments” 数组中的第一个会被返回。
数组与范围查询的相互作用
文档中的标量(非数组元素)必须与查询条件中的每一条子句相匹配。如果使用 {“x” :{“ g t " : 10 , " gt" : 10, " gt":10,"lt” : 20}} 进行查询,那么 “x” 必须同时满足大于 10 且小于 20。然而,如果文档中的 “x” 字段是一个数组,那么当 “x” 键的某一个元素与查询条件的任意一条语句相匹配(查询条件中的每条语句可以匹配不同的数组元素)时,此文档也会被返回。
理解这种行为最好的方式就是来看一个例子。假设现在有如下几个文档:
{"x" : 5}
{"x" : 15}
{"x" : 25}
{"x" : [5, 25]}
如果想找出 “x” 的值在 10 和 20 之间的所有文档,那么你可能会本能地构建这样的查询,即 db.test.find({“x” : {“ g t " : 10 , " gt" : 10, " gt":10,"lt” : 20}}),然后期望它会返回一个文档:{“x” :15}。然而,当实际运行时,我们得到了两个文档,如下所示:
> db.test.find({"x" : {"$gt" : 10, "$lt" : 20}})
{"x" : 15}
{"x" : [5, 25]}
5 和 25 都不在 10 和 20 之间,但由于 25 与查询条件中的第一个子句(“x” 的值大于10)相匹配,5 与查询条件中的第二个子句(“x” 的值小于 20)相匹配,因此这个文档会被返回。
这样就使得针对数组的范围查询基本上失去了作用:一个范围会匹配任何多元素数组。有几种方法可以获得预期的行为。
可以使用 “ e l e m M a t c h " 强制 M o n g o D B 将这两个子句与单个数组元素进行比较。不过,这里有一个问题, " elemMatch" 强制 MongoDB 将这两个子句与单个数组元素进行比较。不过,这里有一个问题," elemMatch"强制MongoDB将这两个子句与单个数组元素进行比较。不过,这里有一个问题,"elemMatch” 不会匹配非数组元素:
> db.test.find({"x" : {"$elemMatch" : {"$gt" : 10, "$lt" : 20}}})
> // 没有结果
文档 {“x” : 15} 不再与查询条件匹配了,因为它的 “x” 字段不是一个数组。也就是说,你应该有充分的理由在一个字段中混合数组和标量值,而这在很多场景中并不需要。对于这样的情况,“$elemMatch” 为数组元素的范围查询提供了一个很好的解决方案。
如果在要查询的字段上有索引,那么可以使用 min 和 max 将查询条件遍历的索引范围限制为 “ g t " 和 " gt" 和 " gt"和"lt” 的值:
> db.test.find({"x" : {"$gt" : 10, "$lt" : 20}}).min({"x" : 10}).max({"x" : 20})
{"x" : 15}
现在,这条查询语句只会遍历值在 10 和 20 之间的索引,不会与值为 5 和 25 的这两个条目进行比较。但是,只有在要查询的字段上存在索引时,才能使用 min 和 max,并且必须将索引的所有字段传递给 min 和 max。
在查询可能包含数组的文档的范围时,使用 min 和 max 通常是一个好主意。在整个索引范围内对数组使用 “ g t " / " gt"/" gt"/"lt” 进行查询是非常低效的。它基本上接受任何值,因此会搜索每个索引项,而不仅仅是索引范围内的值。
查询内嵌文档
查询内嵌文档的方法有两种:查询整个文档或针对其单个键–值对进行查询。
查询整个内嵌文档的工作方式与普通查询相同。假设有这样一个文档:
{
"name" : {
"first" : "Joe",
"last" : "Schmoe"
},
"age" : 45
}
可以像下面这样查询姓名为 Joe Schmoe 的人:
> db.people.find({"name" : {"first" : "Joe", "last" : "Schmoe"}})
然而,如果要查询一个完整的子文档,这个子文档就必须精确匹配。如果 Joe 决定添加一个代表中间名的字段,这个查询就无法工作了,因为查询条件不再与整个内嵌文档相匹配。而且这种查询还是与顺序相关的:{“last” : “Schmoe”, “first” : “Joe”} 就无法匹配。
如果可能,最好只针对内嵌文档的特定键进行查询。这样,即使数据模式变了,也不会导致所有查询因为需要精确匹配而无法使用。可以使用点表示法对内嵌文档的键进行查询:
> db.people.find({"name.first" : "Joe", "name.last" : "Schmoe"})
这时,如果 Joe 增加了更多的键,那么这个查询仍然可以匹配他的姓和名。
这种点表示法是查询文档和其他文档类型的主要区别。查询文档可以包含点,表示“进入内嵌文档内部”的意思。点表示法也是待插入文档不能包含 . 字符的原因。当人们试图将URL 保存为键时,常常会遇到这种限制。解决这个问题的一种方法是在插入前或者提取后始终执行全局替换,用点字符替换 URL 中不合法的字符。
随着文档结构变得越来越复杂,内嵌文档的匹配可能会变得有点儿棘手。假设我们正在存储博客文章,要找到 Joe 发表的 5 分以上的评论。可以按照以下方式对文章进行建模:
> db.blog.find()
{
"content" : "...",
"comments" : [
{
"author" : "joe",
"score" : 3,
"comment" : "nice post"
},
{
"author" : "mary",
"score" : 6,
"comment" : "terrible post"
}
]
}
这时,不能直接使用 db.blog.find({“comments” : {“author” : “joe”, “score” : {“KaTeX parse error: Expected 'EOF', got '}' at position 8: gte" :5}̲}}) 进行查询。内嵌文档的匹…gte” : 5}})也不行,因为符合作者条件的评论与符合分数条件的评论可能不是同一条。也就是说,这会返回上面显示的那个文档:因为它匹配了第一条评论中的 “author” : “joe” 和第二条评论中的 “score” : 6。
要正确指定一组条件而无须指定每个键,请使用 “$elemMatch”。这种模糊的命名条件允许你在查询条件中部分指定匹配数组中的单个内嵌文档。正确的查询如下所示:
> db.blog.find({"comments" : {"$elemMatch" : {"author" : "joe", "score" : {"$gte" : 5}}}})
“$elemMatch” 允许你将限定条件进行“分组”。仅当需要对一个内嵌文档的多个键进行操作时才会用到它。
总结
到此这篇关于MongoDB特定类型的查询语句的文章就介绍到这了,更多相关MongoDB特定类型查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MongoDB特定类型的查询语句实例
目录 null 正则表达式 查询数组 “$all” “$size” “$slice” 返回一个匹配的数组元素 数组与范围查询的相互作用 查询内嵌文档 总结 MongoDB 在一个文档中可以使用多种类型的数据,其中一些类型在查询时会有特别的行为. null null 的行为有一些特别.它可以与自身匹配,所以如果有一个包含如下文档的集合: > var documents = [ ... {_id: 1, y: null}, ... {_id: 2, y: 1}, ... {_id: 3, y: 2}
-
java 中mongodb的各种操作查询的实例详解
java 中mongodb的各种操作查询的实例详解 一. 常用查询: 1. 查询一条数据:(多用于保存时判断db中是否已有当前数据,这里 is 精确匹配,模糊匹配 使用regex...) public PageUrl getByUrl(String url) { return findOne(new Query(Criteria.where("url").is(url)),PageUrl.class); } 2. 查询多条数据:linkUrl.id 属于分级查询 public Lis
-

MongoDB多表关联查询操作实例详解
本文实例讲述了MongoDB多表关联查询操作.分享给大家供大家参考,具体如下: Mongoose的多表关联查询 首先,我们回忆一下,MySQL多表关联查询的语句: student表: calss表: 通过student的classId关联进行查询学生名称,班级的数据: SELECT student.name,student.age,class.name FROM student,class WHERE student.classId = class.id Mongoose多表联合查询(还是以众所
-
mybatis-plus实现自定义SQL、多表查询与多表分页查询语句实例
目录 前言 1.自定义SQL 2.多表查询 3.多表分页查询 4.多表分页条件查询 总结 前言 本文介绍了在mybatis-plus中如何实现:自定义SQL语句,多表查询语句,多表分页查询语句 在说怎么实现之前我们要先明白一个概念,就是mybatis-plus是在mybatis的基础上进行增强,并不做改变,所以mybatis的操作在mybatis-plus中也是一样可以使用的,咱们直接上代码 1.自定义SQL 在mapper中自定义一个方法即可 @Repository public interf
-
MSSQL中递归SQL查询语句实例说明-
一张表(ColumnTable)的结构如下图所示 当前需要实现的功能:通过Number的值为67来获取当前的节点ID.父节点ID 递归实现SQL语句: 复制代码 代码如下: with znieyu as ( select c.Id,c.FatherId,0 as lv1 from ColumnTable c where c.Number=67 union all select c.Id,c.FatherId,lv1-1 from znieyu z inner join ColumnTable c
-
php mysqli查询语句返回值类型实例分析
本文实例分析了php mysqli查询语句返回值类型.分享给大家供大家参考,具体如下: <?php $link = new mysqli('localhost', 'root','123','test'); $sql = 'select uName from userInfo'; $a = $link->query($sql); echo '<pre>'; echo '有结果集<br>'; var_dump($a); echo '</pre>'; $sql
-
常用的MongoDB查询语句的示例代码
背景 最近做了几个规则逻辑.用到mongo查询比较多,就是查询交易信息跑既定规则筛选出交易商户,使用聚合管道进行统计和取出简单处理后的数据,用SQL代替业务代码逻辑的判断. 方法 MongoDB聚合使用aggregate,聚合管道采取自动向下子执行方式,基本语法格式: db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION) 聚合框架中常用的操作: $project:修改输入文档的结构.可以用来重命名.增加或删除域,也可以用于创建计算结果以及嵌套文档.
-
java操作mongoDB查询的实例详解
java操作mongo查询的实例详解 前言: MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型.Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且
-
ThinkPHP查询语句与关联查询用法实例
本文实例讲述了ThinkPHP查询语句与关联查询用法.分享给大家供大家参考.具体如下: 在thinkphp框架页面中我们可以直接拼写sql查询语句来实现数据库查询读写操作,下面就对此加以实例说明. 普通查询除了字符串查询条件外,数组和对象方式的查询条件是非常常用的,这些是基本查询所必须掌握的. 一.使用数组作为查询条件 复制代码 代码如下: $User = M("User"); //实例化User对象 $condition['name'] = 'thinkphp'; // 把查询条件传
-
Mybatis 查询语句条件为枚举类型时报错的解决
目录 Mybatis查询语句条件为枚举类型报错 通常这个错误是 Mybatis处理枚举类型 1.枚举 2.包含枚举的实体类 3.书写枚举处理器 4.配置枚举处理器 5.dao层 6.mapper文件 7.测试 Mybatis查询语句条件为枚举类型报错 通常我们对于数据库中一些枚举字段使用tinyInt类型,而java对象对应的字段很多时候会为了方便定义成short或者int.但这样显然不美观方便,让后面维护的人抠破脑袋找你的常量定义在哪儿,要是没有注释简直让人崩溃.时间久后,没有人知道这里面的值