mysql的limit用法及逻辑分页和物理分页
目录
- 物理分页为什么用limit
- 解释limit
- limit的效率问题
- limit物理分页
物理分页为什么用limit
在讲解limit之间,我们先说说分页的事情。
分页有逻辑分页和物理分页,就像删除有逻辑删除和物理删除。逻辑删除就是改变数据库的状态,物理删除就是直接删除数据库的记录,而逻辑删除只是改变该数据库的状态。例如:

同理,逻辑分页和物理分页是有区别的
| 物理分页 | 逻辑分页 | Cool |
|---|---|---|
| 物理分页依赖的是某一物理实体,这个物理实体就是数据库,比如MySQL数据库提供了limit关键字,程序员只需要编写带有limit关键字的SQL语句,数据库返回的就是分页结果。 | 逻辑分页依赖的是程序员编写的代码。数据库返回的不是分页结果,而是全部数据,然后再由程序员通过代码获取分页数据,常用的操作是一次性从数据库中查询出全部数据并存储到List集合中,因为List集合有序,再根据索引获取指定范围的数据。 | 概念 |
| 每次都要访问数据库,对数据库造成的负担大 | 只需要访问一次数据库 | 数据库负担 |
| 每次只读取一部分数据,占用的内存空间较小 | 一次性将数据读取到内存,占用较大的内存空间。如果使用java开发,Java本身引用的框架就占用了很多内存,这无疑加重了服务器的负担。 | 服务器负担 |
| 每次需要数据时都访问数据库,能够获取数据库的最新状态,实时性强 | 因为一次性读入到内存,数据发生了改变,数据库逇最新状态无法实时反映到操作中 | 实时性 |
| 数据库量大、更新频繁的场合 | 数据量较小、数据稳定的场合 | 服务器负担 |
| 为什么逻辑分页占用较大的内存空间,比如我有一张表,表的信息是: |
-- ---------------------------- -- Table structure for vote_record_memory -- ---------------------------- DROP TABLE IF EXISTS `vote_record_memory`; CREATE TABLE `vote_record_memory` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(20) NOT NULL, `vote_id` int(11) NOT NULL, `group_id` int(11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `index_id` (`user_id`) USING HASH ) ENGINE=MEMORY AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8;
向该表中插入300万条数据后,再转储到桌面,查看转储后的SQL文件的属性:

这是多么庞大的数据,占用的内存多么可怕,为什么我们再选用数据库。这也是我们使用云服务器时,设定mysql的存储空间的大小。
我们一般不推荐使用逻辑分页,而使用物理分页。在使用物理分页的时候,就要考虑到limit的用法。
解释limit
limit X,Y ,跳过前X条数据,读取Y条数据
- X表示第一个返回记录行的偏移量,Y表示返回记录行的最大数目
- 如果X为0的话,即 limit 0, Y,相当于limit Y、
通过业务分析limit
我有一张工资表,只显示最新的前两条记录,同时进行员工姓名和工资提成备注查询
SELECT cue.real_name empName, zs.push_money AS pushMoney, zs.push_money_note AS pushMoneyNote, zs.create_datetime AS createTime FROM zq_salary zs //主表 LEFT JOIN core_user_ext cue ON cue.id = zs.user_id //从表 on之后是从表的条件 WHERE zs.is_deleted = 0 AND ( cue.real_name LIKE '%李%' OR zs.push_money_note LIKE '%测%' ) ORDER BY zs.create_datetime DESC LIMIT 2; 就相当于 ORDER BY zs.create_datetime DESC LIMIT 0,2;

limit的效率问题
我有一个需求,就是从vote_record_memory表中查出3600000到3800000的数据,此时在id上加个索引,索引的类型是Normal,索引的方法是BTREE,分别用两种方法查询
-- 方法1 SELECT * FROM vote_record_memory vrm LIMIT 3600000,20000 ; -- 方法2 SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT 20000
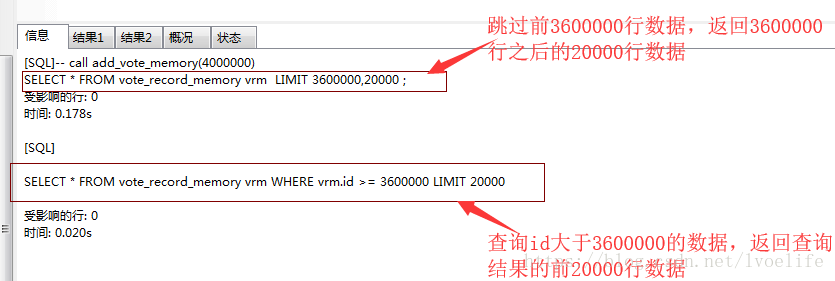
你会发现,方法2的执行效率远比方法1的执行效率高,几乎是方法1的九分之一的时间。
为什么方法1的效率低,而方法二的效率高呢?
分析一
因为在方法1中,我们使用的单纯的limit。limit随着行偏移量的增大,当大到一定程度后,会出现效率下降。而方法2用上索引加where和limit,性能基本稳定,受偏移量和行数的影响不大。
分析二
我们用explain来分析:

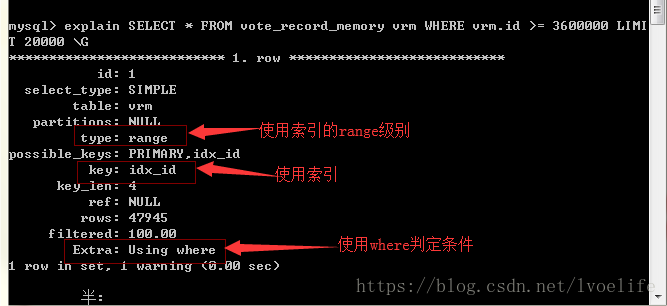
可见,limit语句的执行效率未必很高,因为会进行全表扫描,这就是为什么方法1扫描的的行数是400万行的原因。方法2的扫描行数是47945行,这也是为什么方法2执行效率高的原因。我们尽量避免全表扫描查询,尤其是数据非常庞大,这张表仅有400万条数据,方法1和方法就有这么大差距,可想而知上千万条的数据呢。
能用索引的尽量使用索引,type至少达到range级别,这不是我说的,这是阿里巴巴开发手册的5.2.8中要求的

我不用索引查询到的结果和返回的时间和方法1的时间差不多:
SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT
20000 受影响的行: 0 时间: 0.196s
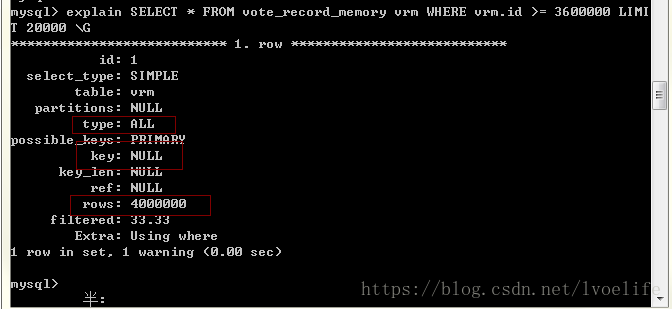
这也就是我们为什么尽量使用索引的原因。mysql索引方法一般有BTREE索引和HASH索引,hash索引的效率比BTREE索引的效率高,但我们经常使用BTREE索引,而不是hash索引。因为最重要的一点就是:Hash索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。
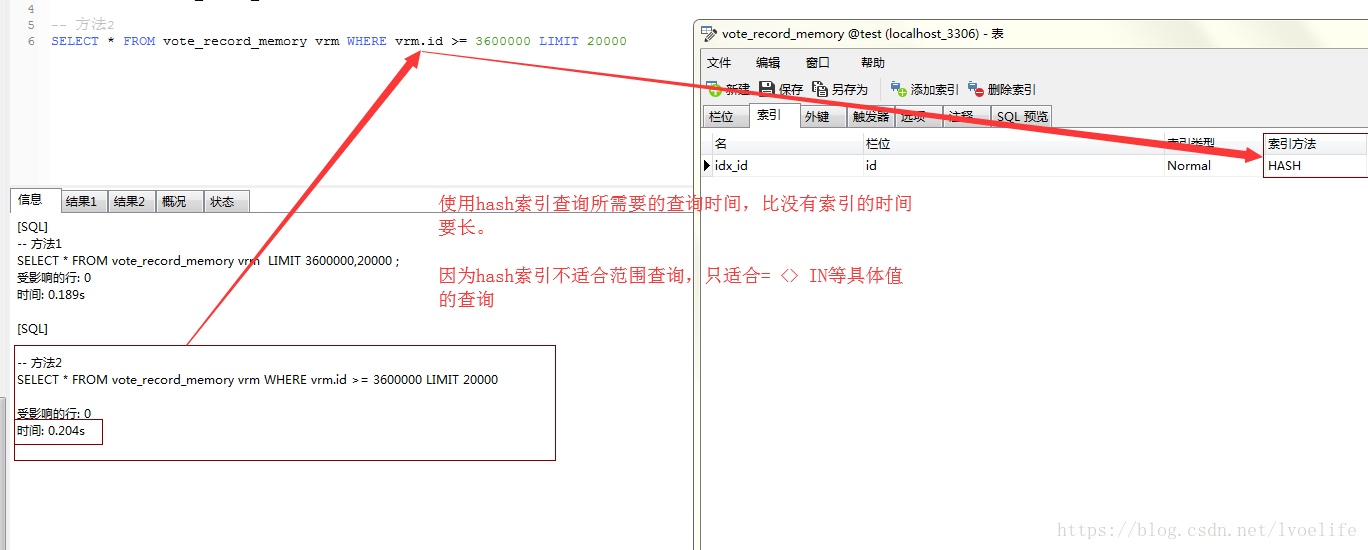
如果是范围查询,我们为什么用BTREE索引的原因。BTREE索引就是二叉树索引,学过数据结构的应该都清楚,这里就不赘述了。
limit物理分页
我们都知道limit一般有两个参数,X和Y,X表示跳过X个数据,读取Y个数据,我们就此来查询数据

| 页数 | 每页显示的行数 | limit语句 | 计算方式 |
|---|---|---|---|
| 第一页 | 20 | limit 0,20 | limit 0*20,20 |
| 第二页 | 20 | limit 20,20 | limit 1*20,20 |
| 第三页 | 20 | limit 40,20 | limit 2*20,20 |
| 第四页 | 20 | limit 60,20 | limit 3*20,20 |
| 如果是SQL语句来进行分页的话,我们可以看到的是: |
-- 首页 SELECT * from vote_record_memory LIMIT 0,20; -- 第二页 SELECT * from vote_record_memory LIMIT 20,20; -- 第三页 SELECT * from vote_record_memory LIMIT 40,20; -- 第四页 SELECT * from vote_record_memory LIMIT 60,20; -- n页 SELECT * from vote_record_memory LIMIT (n-1)*20,20;
因而,如果是用java的话,我们就可以写一个方法,有两个参数,一个是页数,一个每页显示的行数
/**
* @description 简单的模拟分页雏形
* @author zby
* @param currentPage 当前页
* @param lines 每页显示的多少条
* @return 数据的集合
*/
public List<Object> listObjects(int currentPage, int lines) {
String sql = "SELECT * from vote_record_memory LIMIT " + (currentPage - 1) * lines + "," + lines;
return null;
}
参考https://www.cnblogs.com/tonghun/p/7122801.html
到此这篇关于mysql的limit用法及逻辑分页和物理分页的文章就介绍到这了,更多相关mysql limit逻辑分页和物理分页内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈MySQL分页Limit的性能问题
MySQL的分页查询通常通过limit来实现.limit接收1或2个整数型参数,如果是2个参数,第一个是指定第一个返回记录行的偏移量,第二个是返回记录行的最大数目.初始记录行的偏移量是0.为了与PostgreSQL兼容,limit也支持limit # offset #. 问题: 对于小的偏移量,直接使用limit来查询没有什么问题,但随着数据量的增大,越往后分页,limit语句的偏移量就会越大,速度也会明显变慢. 优化思想:避免数据量大时扫描过多的记录 解决:子查询的分页方式或者JOIN分页方式
-

mysql分页的limit参数简单示例
Mysql的分页的两个参数 select * from user limit 1,2 1表示从第几条数据开始查(默认索引是0,如果写1,从第二条开始查) 2,表示这页显示几条数据 到此这篇关于mysql分页的limit参数的文章就介绍到这了,更多相关mysql分页limit参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
mysql limit分页优化详细介绍
mysql limit分页优化 同样是取10条数据 select * from yanxue8_visit limit 10000,10 和 select * from yanxue8_visit limit 0,10 就不是一个数量级别的. 网上也很多关于limit的五条优化准则,都是翻译自MySQL手册,虽然正确但不实用.今天发现一篇文章写了些关于limit优化的,很不错. 文中不是直接使用limit,而是首先获取到offset的id然后直接使用limit size来获取数据.根据他的数据,
-
详解MySQL的limit用法和分页查询语句的性能分析
limit用法 在我们使用查询语句的时候,经常要返回前几条或者中间某几行数据,这个时候怎么办呢?不用担心,mysql已经为我们提供了这样一个功能. SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数.LIMIT 接受一个或两个数字参数.参数必须是一个整数常量.如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目.初始记
-
mysql limit分页优化方法分享
同样是取10条数据 select * from yanxue8_visit limit 10000,10 和 select * from yanxue8_visit limit 0,10 就不是一个数量级别的. 网上也很多关于limit的五条优化准则,都是翻译自MySQL手册,虽然正确但不实用.今天发现一篇文章写了些关于limit优化的,很不错. 文中不是直接使用limit,而是首先获取到offset的id然后直接使用limit size来获取数据.根据他的数据,明显要好于直接使用limit.这
-
在MySQL中使用LIMIT进行分页的方法
今天看一个水友说他的MySQL现在变的很慢.问什么情况时.说单表超过2个G的一个MyISAM.真垃圾的回答方式. 简单答复:换一个强劲的服务器.换服务器很管用的:) --- 最终让取到慢查询: SELECT * FROM pw_gbook WHERE uid='N' ORDER BY postdate DESC LIMIT N,N; SELECT * FROM pw_gbook WHERE uid='N' ORDER BY postdate DESC LIMIT N,N; 如: S
-
mysql limit 分页的用法及注意要点
mysql limit 分页的用法及注意事项: 在我们使用查询语句的时候,经常要返回前几条或者中间某几行数据,这个时候怎么办呢?不用担心,mysql已经为我们提供了这样一个功能. SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数.LIMIT 接受一个或两个数字参数.参数必须 是一个整数常量.如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参
-
MySQL limit使用方法以及超大分页问题解决
前言 日常开发中,我们使用mysql来实现分页功能的时候,总是会用到mysql的limit语法.而怎么使用却很有讲究的,今天来总结一下. limit语法 limit语法支持两个参数,offset和limit,前者表示偏移量,后者表示取前limit条数据. 例如: ## 返回符合条件的前10条语句 select * from user limit 10 ## 返回符合条件的第11-20条数据 select * from user limit 10,20 从上面也可以看出来,limit n 等价于l
-
为什么MySQL分页用limit会越来越慢
目录 一.测试实验 二. 对limit分页问题的性能优化方法 2.1 利用表的覆盖索引来加速分页查询 2.2 利用 id>=的形式: 2.3 利用join 总结: 阿牛新入职了一家新公司,第一个任务是根据条件导出订单表中的数据到文件中,阿牛心想:这也太简单了,于是很快写好了如下语句,并且告诉测试自己的代码是免测产品. 语句如下: select * from orders where name='lilei' and create_time>'2020-01-01 00:00:00' limit
-
mysql的limit用法及逻辑分页和物理分页
目录 物理分页为什么用limit 解释limit limit的效率问题 limit物理分页 物理分页为什么用limit 在讲解limit之间,我们先说说分页的事情. 分页有逻辑分页和物理分页,就像删除有逻辑删除和物理删除.逻辑删除就是改变数据库的状态,物理删除就是直接删除数据库的记录,而逻辑删除只是改变该数据库的状态.例如: 同理,逻辑分页和物理分页是有区别的 物理分页 逻辑分页 Cool 物理分页依赖的是某一物理实体,这个物理实体就是数据库,比如MySQL数据库提供了limit关键字,程序员只
-
详解mysql的limit经典用法及优化实例
用法一 复制代码 代码如下: SELECT `keyword_rank`.* FROM `keyword_rank` WHERE (advertiserid='59') LIMIT 2 OFFSET 1; 比如这个SQL ,limit后面跟的是2条数据,offset后面是从第1条开始读取. 用法二 复制代码 代码如下: SELECT `keyword_rank`.* FROM `keyword_rank` WHERE (advertiserid='59') LIMIT 2,1; 而这个SQL
-
mysql中的limit用法有哪些(推荐)
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows; 1.m代表从m+1条记录行开始检索,n代表取出n条数据.(m可设为0) 如:SELECT * FROM 表名 limit 6,5; 表示:从第7条记录行开始算,取出5条数据 2.值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据. 如:SELECT * FROM 表名 limit 6,-1; 表示:取出第6条记录行以
-
深入分析Mysql中limit的用法
Mysql中limit的用法:在我们使用查询语句的时候,经常要返回前几条或者中间某几行数据,这个时候怎么办呢?不用担心,mysql已经为我们提供了这样一个功能. SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数.LIMIT 接受一个或两个数字参数.参数必须是一个整数常量.如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行
-
详细介绍mysql中limit与offset的用法
目录 mysql limit与offset用法 附:Mysql limit offset用法举例 总结 有的时候我们在学习或者工作中会使用到SQL语句,那么介绍一下limit和offset的使用方法. mysql limit与offset用法 mysql里分页一般用limit来实现,例如: 1.select* from user limit 3 表示直接取前三条数据 2.select * from user limit 1,3; 表示取1后面的第2,3,4三条条数据 3.select * fro
-
MySQL切分查询用法分析
本文实例讲述了MySQL切分查询用法.分享给大家供大家参考,具体如下: 对于大查询有时需要'分而治之',将大查询切分为小查询: 每个查询功能完全一样,但只完成原来的一小部分,每次查询只返回一小部分结果集. 删除旧的数据就是一个很好地例子.定期清理旧数据时,如果一条sql涉及了大量的数据时,可能会一次性锁住多个表或行,耗费了大量的系统资源,却阻塞了其他很多小的但重要的查询.将一个大得DELETE语句切分为较小的查询时,可以尽量减少影响msql的性能,同时减少mysql复制造成的延迟. 例如,每个月
-
浅谈mysql使用limit分页优化方案的实现
Mysql limit分页语句用法 与Oracle和MS SqlServer相比,mysql的分页方法简单的让人想哭. --语法: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset --举例: select * from table limit 5; --返回前5行 select * from table limit 0,5; --同上,返回前5行 select * from table limit 5,10; --返回6
-
php中mysql操作buffer用法详解
本文实例讲述了php中mysql操作buffer用法.分享给大家供大家参考.具体分析如下: php与mysql的连接有三种方式,mysql,mysqli,pdo.不管使用哪种方式进行连接,都有使用buffer和不使用buffer的区别. 什么叫使用buffer和不使用buffer呢? 客户端与mysql服务端进行查询操作,查询操作的时候如果获取的数据量比较大,那个这个查询结果放在哪里呢? 有两个地方可以放:客户端的缓冲区和服务端的缓冲区. 我们这里说的buffer指的是客户端的缓冲区,如果查询结
-
mysql delete limit 使用方法详解
mysql delete limit优点: 用于DELETE的MySQL唯一的LIMIT row_count选项用于告知服务器在控制命令被返回到客户端前被删除的行的最大值.本选项用于确保一个DELETE语句不会占用过多的时间.您可以只重复DELETE语句,直到相关行的数目少于LIMIT值为止. 如果DELETE语句包括一个ORDER BY子句,则各行按照子句中指定的顺序进行删除.此子句只在与LIMIT联用是才起作用.例如,以下子句用于查找与WHERE子句对应的行,使用timestamp_colu