Kubernetes中Nginx服务启动失败排查流程分析(Error: ImagePullBackOff)
pod节点启动失败,nginx服务无法正常访问,服务状态显示为ImagePullBackOff。
[root@m1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-f89759699-cgjgp 0/1 ImagePullBackOff 0 103m
查看nginx服务的Pod节点详细信息。
[root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgp
Name: nginx-f89759699-cgjgp
Namespace: default
Priority: 0
Service Account: default
Node: n1/192.168.200.84
Start Time: Fri, 10 Mar 2023 08:40:33 +0800
Labels: app=nginx
pod-template-hash=f89759699
Annotations: <none>
Status: Pending
IP: 10.244.3.20
IPs:
IP: 10.244.3.20
Controlled By: ReplicaSet/nginx-f89759699
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ImagePullBackOff
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-zk8sj (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-zk8sj:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-zk8sj
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal BackOff 57m (x179 over 100m) kubelet Back-off pulling image "nginx"
Normal Pulling 7m33s (x22 over 100m) kubelet Pulling image "nginx"
Warning Failed 2m30s (x417 over 100m) kubelet Error: ImagePullBackOff
发现,获取nginx镜像失败。可能是由于Docker服务引起的。
于是,检查Docker是否正常启动
systemctl status docker
发现,docker服务启动失败,手动尝试重新启动。
systemctl restart docker
但是,重启docker服务失败,出现如下报错信息。
[root@m1 ~]# systemctl restart docker Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.
执行systemctl restart docker命令失效。
接着,当执行docker version命令时,发现未能连接到Docker daemon
[root@m1 ~]# docker version Client: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:03:11 2022 OS/Arch: linux/amd64 Context: default Experimental: true Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
于是,再次通过执行systemctl status docker命令,查看docker服务未能启动,阅读输出报错信息,如下所示。
[root@m1 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Fri 2023-03-10 10:28:16 CST; 4min 35s ago
Docs: https://docs.docker.com
Main PID: 2221 (code=exited, status=1/FAILURE)
Mar 10 10:28:13 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILURE
Mar 10 10:28:13 m1 systemd[1]: docker.service: Failed with result 'exit-code'.
Mar 10 10:28:13 m1 systemd[1]: Failed to start Docker Application Container Engine.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.
Mar 10 10:28:16 m1 systemd[1]: Stopped Docker Application Container Engine.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Start request repeated too quickly.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Failed with result 'exit-code'.
Mar 10 10:28:16 m1 systemd[1]: Failed to start Docker Application Container Engine.
[root@m1 ~]#
通过上述输出显示,Docker 服务进程的启动失败,状态为 1/FAILURE。
接下来,尝试通过以下步骤来排查和解决问题:
1️⃣查看 Docker 服务日志:使用以下命令查看 Docker 服务日志,以便更详细地了解失败原因。
sudo journalctl -u docker.service
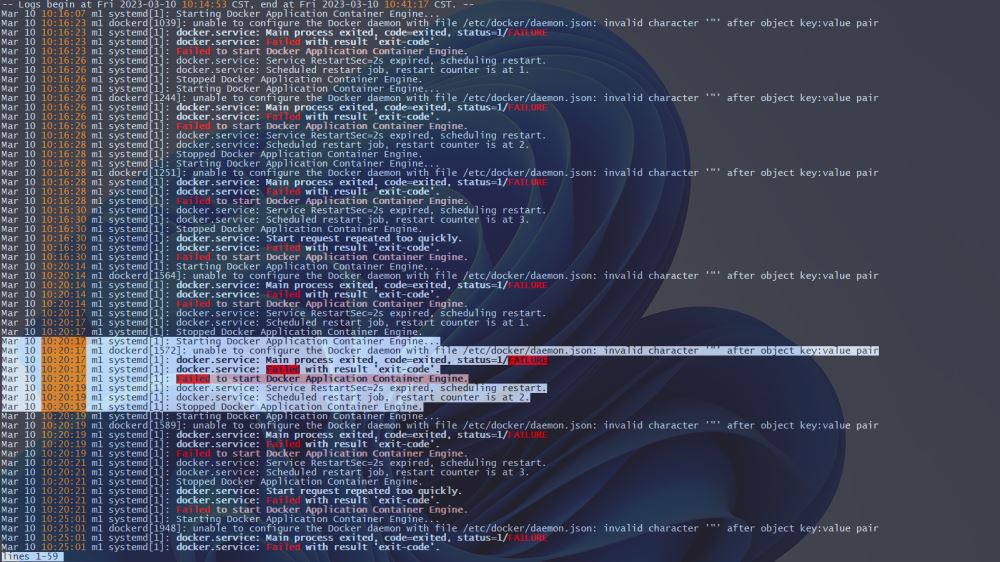
2️⃣ 通过输出Ddocker日志分析,提取到了相关报错信息片段,发现是配置daemon中的/etc/docker/daemon.json配置文件出错导致的。
Mar 10 10:20:17 m1 systemd[1]: Starting Docker Application Container Engine... Mar 10 10:20:17 m1 dockerd[1572]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character '"' after object key:value pair Mar 10 10:20:17 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILURE Mar 10 10:20:17 m1 systemd[1]: docker.service: Failed with result 'exit-code'. Mar 10 10:20:17 m1 systemd[1]: Failed to start Docker Application Container Engine. Mar 10 10:20:19 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart. Mar 10 10:20:19 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 2. Mar 10 10:20:19 m1 systemd[1]: Stopped Docker Application Container Engine.
3️⃣此时,查看daemon配置文件/etc/docker/daemon.json是否配置正确。
[root@m1 ~]# cat /etc/docker/daemon.json
{
# 设置 Docker 镜像的注册表镜像源为阿里云镜像源。
"registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"]
# 指定 Docker 守护进程使用 systemd 作为 cgroup driver。
"exec-opts": ["native.cgroupdriver=systemd"]
}
咋一看,配置信息没有什么问题,都是正确的,但仔细一看,就会发现应该在"registry-mirrors"选项的结尾添加逗号。犯了缺少逗号(,)导致的语法错误,终于找到了问题根源。
相关推荐
-
使用Kubernetes部署Springboot或Nginx的详细教程
1 前言 经过<Maven一键部署Springboot到Docker仓库,为自动化做准备>,Springboot的Docker镜像已经准备好,也能在Docker上成功运行了,是时候放上Kubernetes跑一跑了.这非常简单,一个yaml文件即可. 2 一键部署Springboot 2.1 准备yaml文件 当准备好镜像文件后,要部署到Kubernetes就非常容易了,只需要一个yaml格式的文件即可,这个文件能描述你所需要的组件,如Deployment.Service.Ingress等.定义
-

记录一次nginx启动失败的解决过程
周日领导说docker nginx起不来了,导致jira域名映射失败,记录一下解决过程 操作 首先nginx不是自己部署,要先启动一下 docker start nginx 发现打印出了nginx 但是 docker ps 发现 nginx还是启动失败 于是准备查看日志 docker logs -f nginx 报了一堆错误,也不知道是什么时候打的日志,后来解决之后猜测是因为配置文件为空的原因,因为没有找到event模块 所以首先看一下nginx的容器信息 docker inspect ngin
-
Nginx启动、重启失败的一般解决方法和步骤
概述 今天在do的VPS配置Nginx虚拟主机时,修改配置文件后,重启Nginx后一直报告失败,但是不知道哪里错了,直觉觉得是配置文件配置错了,google了下解决方案. 解决方案 Nginx启动或重启失败,一般是因为配置文件出错了,我们可以使用nginx -t方法查看配置文件出错的地方. 也可以通过查看Nginx日志文件定位到Nginx重启失败的原因,Nginx日志文件的路径一般在:/var/log/nginx目录下 总结 文章没什么技术含量,每天都攒一点基础知识
-
详解Nginx启动失败的几种错误处理
使用Nginx做Web服务器过程中,碰到过以下几个问题: 1.nginx启动失败 systemctl start nginx.service 启动nginx失败,报错信息如下: Starting nginx: nginx: [emerg] bind() to 0.0.0.0:**** failed (13: Permission denied) 这通常是因为开启了SELinux的原因,使用命令 getenforce 可以查看SELinux状态,如果输出为 enforcing 表示已开启.用以下方
-
Kubernetes中Nginx服务启动失败排查流程分析(Error: ImagePullBackOff)
pod节点启动失败,nginx服务无法正常访问,服务状态显示为ImagePullBackOff. [root@m1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-f89759699-cgjgp 0/1 ImagePullBackOff 0 103m 查看nginx服务的Pod节点详细信息. [root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgp Name: nginx-f
-
Kubernetes中Nginx配置热加载的全过程
目录 前言 使用方法 总结 前言 Nginx本身是支持热更新的,通过nginx -s reload指令,实际通过向进程发送HUB信号实现不停服重新加载配置,然而在Docker或者Kubernetes中,每次都需要进容器执行nginx -s reload指令,单docker容器还好说,可以在外面通过exec指定容器执行该指令进行热加载,Kubernetes的话,就比较难受了 今天介绍一下Kubernetes中Nginx热加载配置的处理方法——reloader reloader地址:https://
-
详解RocketMQ中的消费者启动与消费流程分析
目录 一.简介 1.1 RocketMQ 简介 1.2 工作流程 二.消费者启动流程 2.1 实例化消费者 2.2 设置NameServer和订阅topic过程 2.2.1 添加tag 2.2.2 发送心跳至Broker 2.2.3上传过滤器类至FilterServer 2.3 注册回调实现类 2.4 消费者启动 三.pull/push 模式消费 3.1 pull模式-DefaultMQPullConsumer 3.2 push模式-DefaultMQPushConsumer 3.3 小结 四.
-
spring cloud eureka 服务启动失败的原因分析及解决方法
目录 环境: 错误log 环境: <spring-boot-version>2.3.5.RELEASE</spring-boot-version> <spring-cloud-version>Hoxton.SR8</spring-cloud-version> 错误log Unable to start web server; nested exception is org.springframework.boot.web.server.WebServerEx
-
CentOS 7下MySQL服务启动失败的快速解决方法
今天,启动MySQL服务器失败,如下所示: [root@spark01 ~]# /etc/init.d/mysqld start Starting mysqld (via systemctl): Job for mysqld.service failed because the control process exited with error code. See "systemctl status mysqld.service" and "journalctl -xe&qu
-
win2003的“由于下列错误,Parallel port driver 服务启动失败”的解决方法
开机弹出一个错误窗口,让查看事件查看器.找到一个红叉的记录:由于下列错误,Parallel port driver 服务启动失败: 无法启动服务,原因可能是已被禁用或与其相关联的设备没有启动." 不知道怎么解决,搜索一下,搞定.转文如下: 有人说找到系统服务把这项关了就可以,但我怀疑他们没有亲自实践过,因为系统服务中根本找不到对应的服务.这个错误出现的原因可能是并口已经在bios 中关闭了,但是系统或者某个软件中还会有个虚拟的并口.解决这个问题,只需要在注册表HKEY_LOCAL_MACHINE
-
真正解决win2003的“由于下列错误,Parallel port driver 服务启动失败的解决方法”
开机弹出一个错误窗口,让查看事件查看器.找到一个红叉的记录:由于下列错误,Parallel port driver 服务启动失败: 无法启动服务,原因可能是已被禁用或与其相关联的设备没有启动." 不知道怎么解决,搜索一下,搞定.转文如下: 有人说找到系统服务把这项关了就可以,但我怀疑他们没有亲自实践过,因为系统服务中根本找不到对应的服务.这个错误出现的原因可能是并口已经在bios 中关闭了,但是系统或者某个软件中还会有个虚拟的并口.解决这个问题,只需要在注册表HKEY_LOCAL_MACHINE
-
mysql5.7.18安装时mysql服务启动失败的解决方法
MySQL 是一个非常强大的关系型数据库.但有些初学者在安装配置的时候,遇到种种的困难,在此就不说安装过程了,说一下配置过程.在官网下载的mysql时候,有msi格式和zip格式.Msi直接运行安装即可,zip则解压在自己喜欢的目录地址即可.在安装这两种的时候,都需要配置才能用.以下介绍主要是msi格式默认的地址:C:\Program Files\ mysql-5.7.18-win32. 一.在安装或者解压后,需要配置环境变量,过程如下:我的电脑->属性->高级系统设置->高级->
-
win2003 HookPort 服务启动失败的解决办法!
问题描述:Win2003系统每次开机启动时都弹出个对话框报HookPort 服务启动失败,很多网友都遇到同类问题,问题根源是360安全卫士引起的,官方一直没有给出解决方案,去他们论坛上发贴也没人理,哥只有自己处理了,现在发上来和广大网友们共享! 解决办法: 1.删除360安全卫士或升级他们的软件试下: 2.如果上面的办法不中那就用哥的吧,把下面的代码存成一个bat文件,然后双击即可,双击后再重启一次看看,是不是不报了?是不是很神奇呀,哈哈! ,哥的QQ285584,欢迎交流! 程序代码 复制代码
-
python脚本当作Linux中的服务启动实现方法
脚本服务化目的: python 在 文本处理中有着广泛的应用,为了满足文本数据的获取,会每天运行一些爬虫抓取数据.但是网上买的服务器会不定时进行维护,服务器会被重启.这样我们的爬虫服务就无法运行.这个时候我们可以把python脚本服务化,服务器重启后,脚本就会自动运行.解决服务器维护后需要手动运行python脚本. 实现方法: 1,给编写好的python脚本开头加上 #!/usr/bin/python 2,启动shell 脚本 编写 vi pystock.sh #vim /etc/init.d/
-
解决redis服务启动失败的问题
最近学redis,就遇到了各种坑,在这里分享一下 我是将redis做成后台 安装,配置环境变量统统省略掉了. 做成后台服务呢,首先,cd到redis的安装目录下,再cd到util,接着执行 ./install_server.sh 然后修改服务名称,将原来的redis_6379更名为redisd,这样下次启动比较方便,命令如下: cd /etc/init.d/ mv redis_6379 redisd 然后,就可以启动redis服务了 service redisd start 启动之后,就可以进入