通过Python实现一个A/B测试详解
目录
- / 01 / AB测试
- / 02 / 使用Python进行AB测试
- / 03 / 数据准备
- / 04 / AB测试找到最佳营销策略
- / 05 / 结论
A/B测试,通过分析两种不同的营销策略,以此来选择最佳的营销策略,可以高效地将流量转化为销售额(或转化为你的预期目标)。
有助于找到更好的方法来寻找客户、营销产品、扩大影响范围或将目标客户转化为实际客户。

A/B测试是每个学习数据分析同学,都应该知道且去学习的概念。
/ 01 / AB测试
举个例子,我在短视频App上购买流量推广我的视频(挂小黄车买课程),一共推了两次,其中两次的目标受众各不相同。
在分析了两次活动的结果后,我可能倾向于选择第二次的活动目标受众,因为它比第一次活动能够带来更好的销售额或涨粉或播放量。
我们的目标可以是提高销售额、粉丝数或流量等等。
当我们根据以前的营销活动结果选择最佳的营销策略时,这就是A/B测试。
本次使用的数据集是开源数据集,İLKER YILDIZ在Kaggle上提交的A/B测试的数据集。
下面是数据集中的所有特征:
1. Campaign Name: 活动名称
2. Date: 记录日期
3. Spend: 活动花费(单位:美元)
4. of Impressions: 广告在整个活动中的展示次数
5. Reach: 广告在整个活动中的展示人数(唯一)
6. of Website Clicks: 通过广告获得的网站点击次数
7. of Searches: 在网站上执行搜索的用户数量
8. of View Content: 查看网站内容产品的用户数量
9. of Add to Cart: 将产品添加到购物车的用户数量
10. of Purchase: 购买次数
一共是进行了两种类型的宣传营销活动:
1. Control Campaign: 对照活动
2. Test Campaign: 测试活动
通过执行A/B测试找到最适合的营销策略,以此来吸引获得更多的客户。
下面小F就带大家一起来学习下。
/ 02 / 使用Python进行AB测试
先安装相关的Python可视化库plotly,在使用的时候发现报错,所以还要安装statsmodels库。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple statsmodels pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plotly
然后导入Python库,读取两种活动的数据文件。
import pandas as pd
import datetime
from datetime import date, timedelta
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
pio.templates.default = "plotly_white"
# 设置value的显示长度为200,默认为50
pd.set_option('max_colwidth', 300)
# 显示所有列,把行显示设置成最大
pd.set_option('display.max_columns', None)
# 显示所有行,把列显示设置成最大
pd.set_option('display.max_rows', None)
# 加载数据
control_data = pd.read_csv("control_group.csv", sep=";")
test_data = pd.read_csv("test_group.csv", sep=";")
来看看这两个数据集的情况。
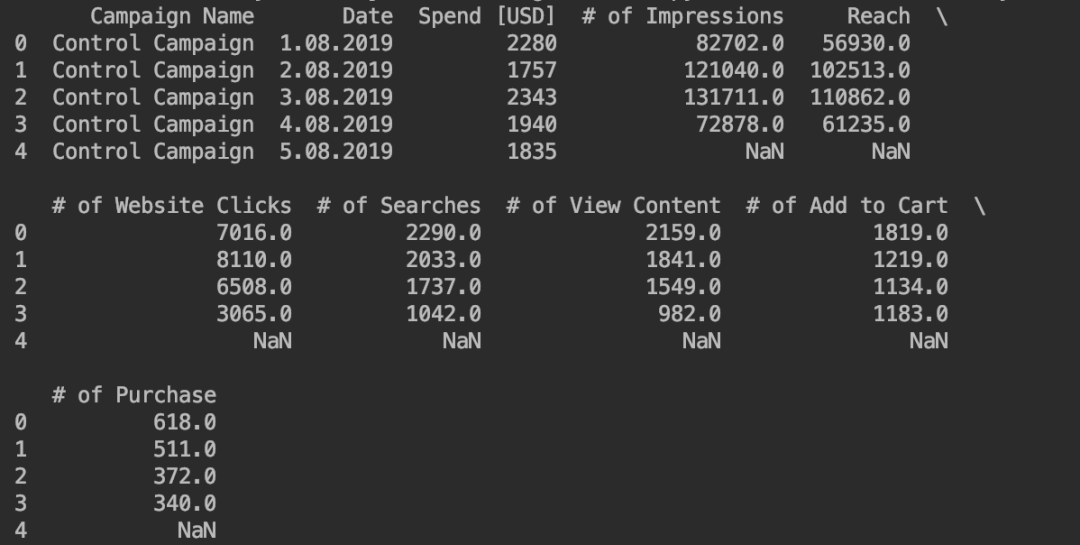
# 打印对照活动数据 print(control_data.head())
对照活动数据的情况如下。
打印测试活动数据。
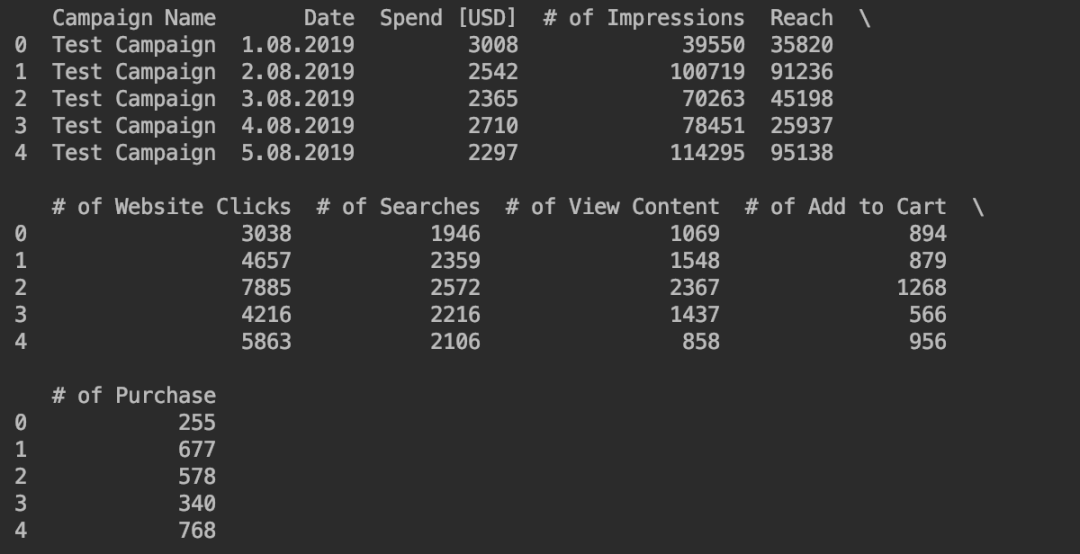
# 打印测试活动数据 print(test_data.head())
测试活动数据的情况如下。
/ 03 / 数据准备
发现数据集的列名不太规范,所以对列名进行修改。
# 更改列名
control_data.columns = ["Campaign Name", "Date", "Amount Spent",
"Number of Impressions", "Reach", "Website Clicks",
"Searches Received", "Content Viewed", "Added to Cart",
"Purchases"]
test_data.columns = ["Campaign Name", "Date", "Amount Spent",
"Number of Impressions", "Reach", "Website Clicks",
"Searches Received", "Content Viewed", "Added to Cart",
"Purchases"]
现在让我们看看数据集是否有空值。
# 查看空值 print(control_data.isnull().sum()) print(test_data.isnull().sum())


发现对照活动的数据集有数据缺失,可以用每列的平均值来填充这些缺失值。
# 数据清洗
control_data["Number of Impressions"].fillna(value=control_data["Number of Impressions"].mean(),
inplace=True)
control_data["Reach"].fillna(value=control_data["Reach"].mean(),
inplace=True)
control_data["Website Clicks"].fillna(value=control_data["Website Clicks"].mean(),
inplace=True)
control_data["Searches Received"].fillna(value=control_data["Searches Received"].mean(),
inplace=True)
control_data["Content Viewed"].fillna(value=control_data["Content Viewed"].mean(),
inplace=True)
control_data["Added to Cart"].fillna(value=control_data["Added to Cart"].mean(),
inplace=True)
control_data["Purchases"].fillna(value=control_data["Purchases"].mean(),
inplace=True)
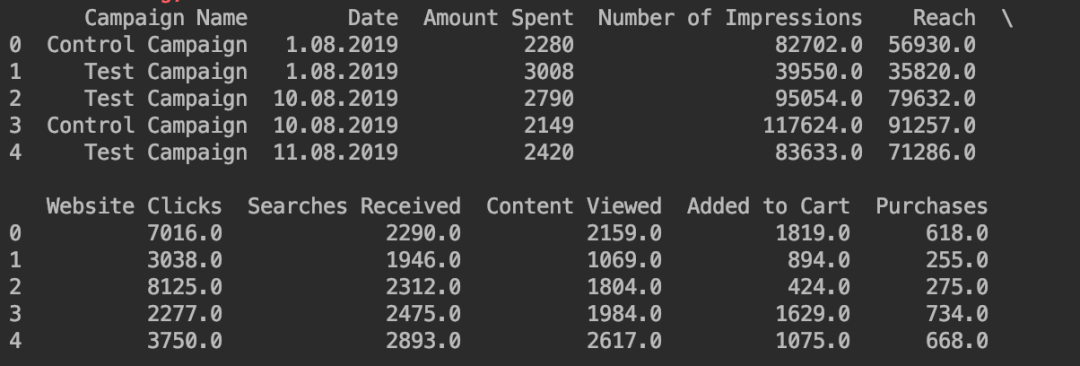
通过合并两个数据集来创建一个新的数据集。
# 合并数据
ab_data = control_data.merge(test_data,
how="outer").sort_values(["Date"])
ab_data = ab_data.reset_index(drop=True)
print(ab_data.head())
查看数据集中,两种活动的样本数量是否相同。
# 类型计数 print(ab_data["Campaign Name"].value_counts())

可以看出,每种活动都有30个样本数据,满足样本均衡的条件。
/ 04 / AB测试找到最佳营销策略
01 展示次数-活动花费
首先分析两种活动中「展示次数」和「活动花费」之间的关系。
figure = px.scatter(data_frame = ab_data,
x="Number of Impressions",
y="Amount Spent",
size="Amount Spent",
color= "Campaign Name",
trendline="ols")
figure.show()
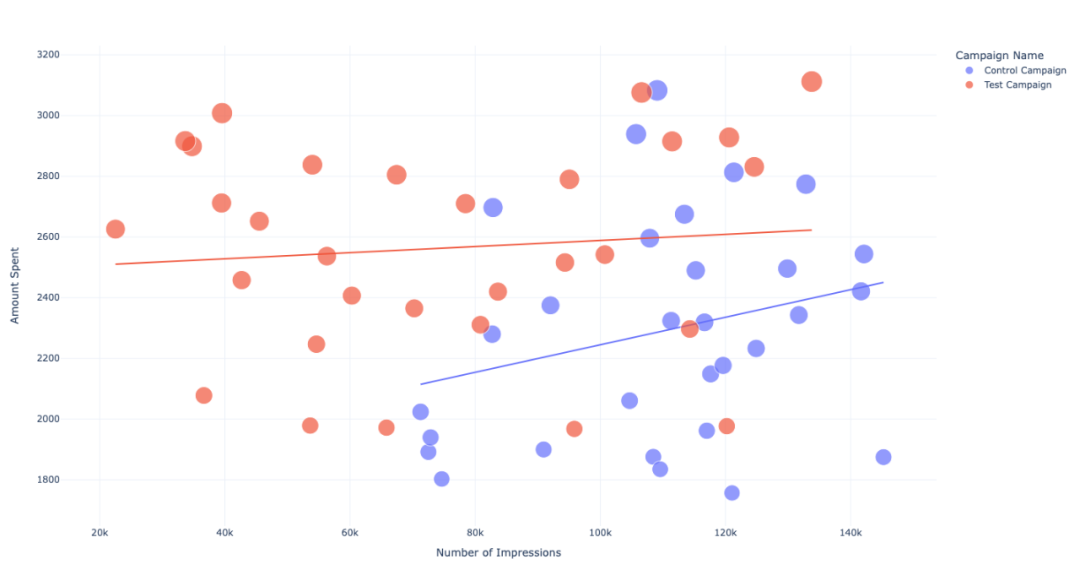
发现在花费相同的情况下,「对照活动」的展示次数更多。
02 搜索量
两种类型活动的网站总搜索量对比。
label = ["Total Searches from Control Campaign",
"Total Searches from Test Campaign"]
counts = [sum(control_data["Searches Received"]),
sum(test_data["Searches Received"])]
colors = ['gold', 'lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Searches')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
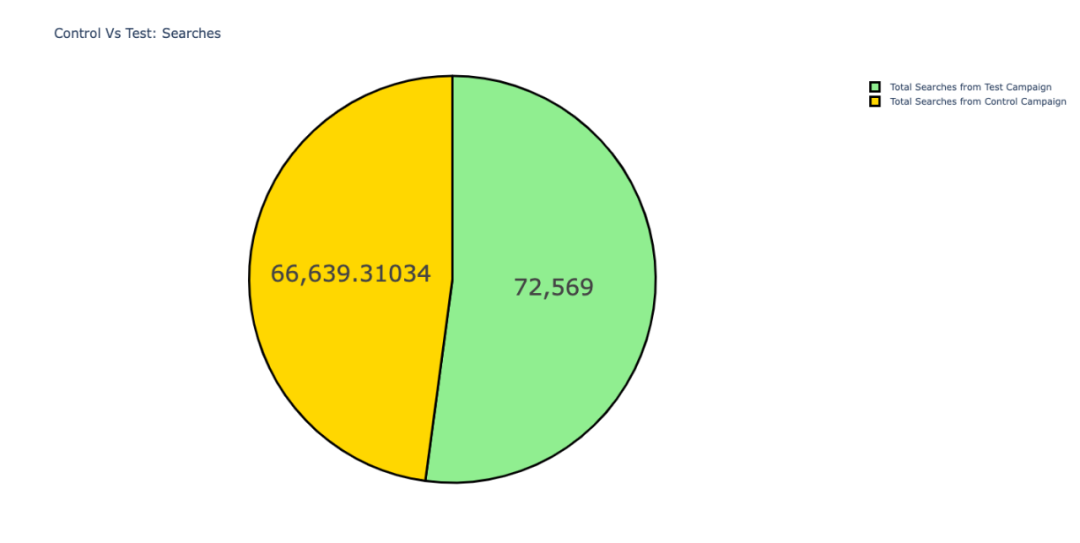
在网站的搜索量上,「测试活动」略多于对照活动。
03 点击量
两种类型活动的网站总点击量对比。
label = ["Website Clicks from Control Campaign",
"Website Clicks from Test Campaign"]
counts = [sum(control_data["Website Clicks"]),
sum(test_data["Website Clicks"])]
colors = ['gold', 'lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Website Clicks')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
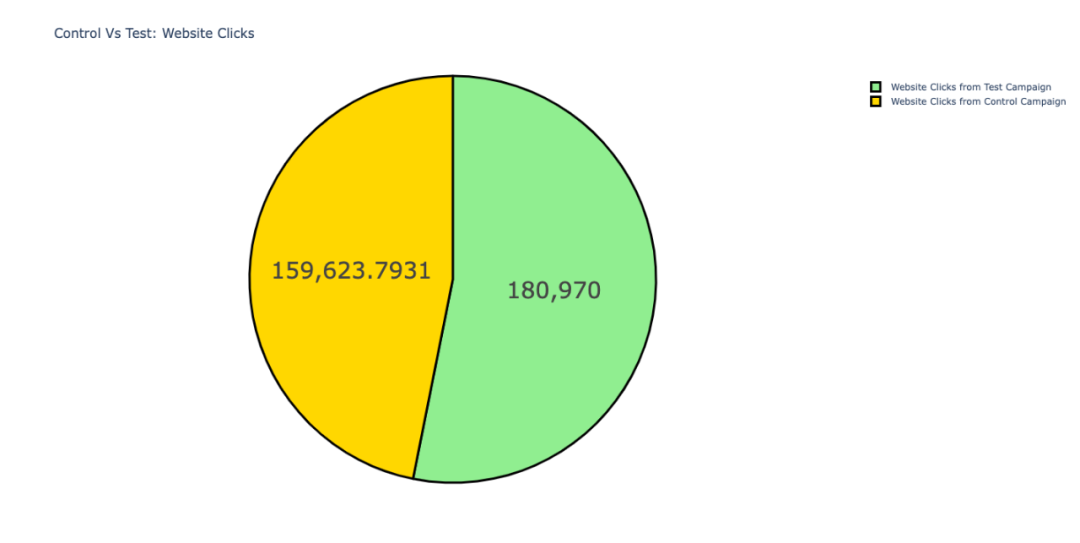
在网站的点击量上,「测试活动」略多于对照活动。
04 内容产品查看量
两种类型活动的网站内容和产品的查看量对比。
label = ["Content Viewed from Control Campaign",
"Content Viewed from Test Campaign"]
counts = [sum(control_data["Content Viewed"]),
sum(test_data["Content Viewed"])]
colors = ['gold', 'lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Content Viewed')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
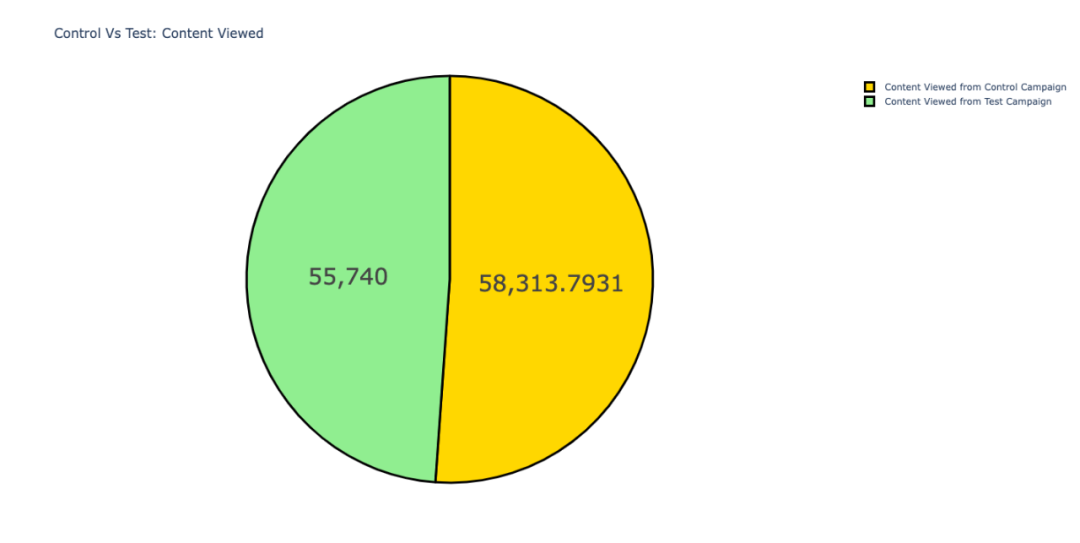
可以看出「对照活动」的内容产品查看量比测试活动多。
虽然差距不是很大,但是由于对照活动的网站点击率相对较低,这便意味着「对照活动」的用户参与度(粘性)高于测试活动。
05 加购物车量
两种类型活动,将产品添加到购物车的数量。
label = ["Products Added to Cart from Control Campaign",
"Products Added to Cart from Test Campaign"]
counts = [sum(control_data["Added to Cart"]),
sum(test_data["Added to Cart"])]
colors = ['gold','lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Added to Cart')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
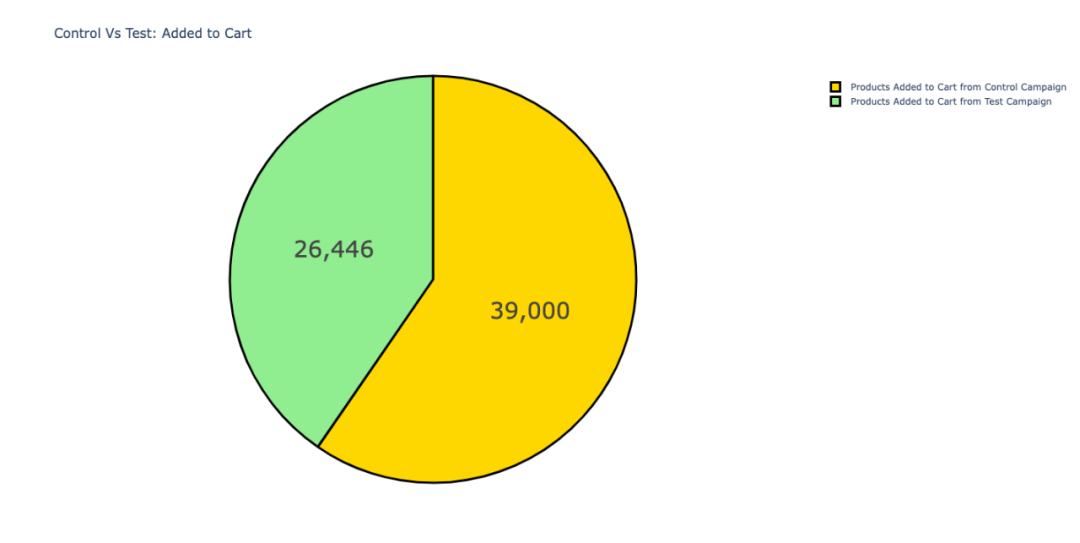
尽管「对照活动」的点击率相对较低,但是却有更多的产品被添加到购物车中。
06 活动花费
两种类型的活动花费对比。
label = ["Amount Spent in Control Campaign",
"Amount Spent in Test Campaign"]
counts = [sum(control_data["Amount Spent"]),
sum(test_data["Amount Spent"])]
colors = ['gold','lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Amount Spent')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
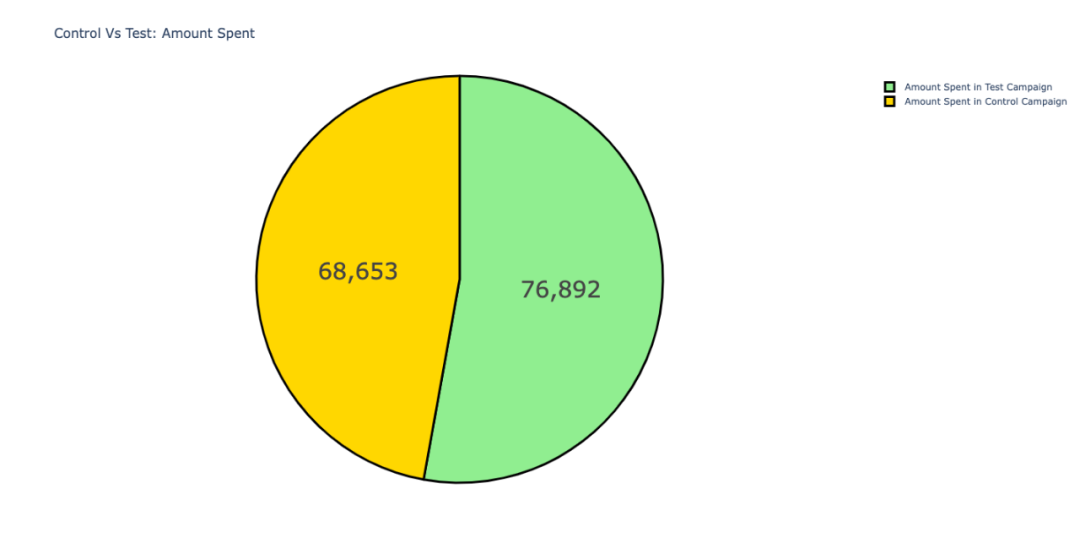
在测试活动上的花费要高于对照活动。
基于上面的分析,对照活动带来了更多的内容浏览量和产品添加到购物车,「对照活动」比测试活动更有效。
07 销售额
两种类型活动的销售情况对比。
label = ["Purchases Made by Control Campaign",
"Purchases Made by Test Campaign"]
counts = [sum(control_data["Purchases"]),
sum(test_data["Purchases"])]
colors = ['gold','lightgreen']
fig = go.Figure(data=[go.Pie(labels=label, values=counts)])
fig.update_layout(title_text='Control Vs Test: Purchases')
fig.update_traces(hoverinfo='label+percent', textinfo='value',
textfont_size=30,
marker=dict(colors=colors,
line=dict(color='black', width=3)))
fig.show()
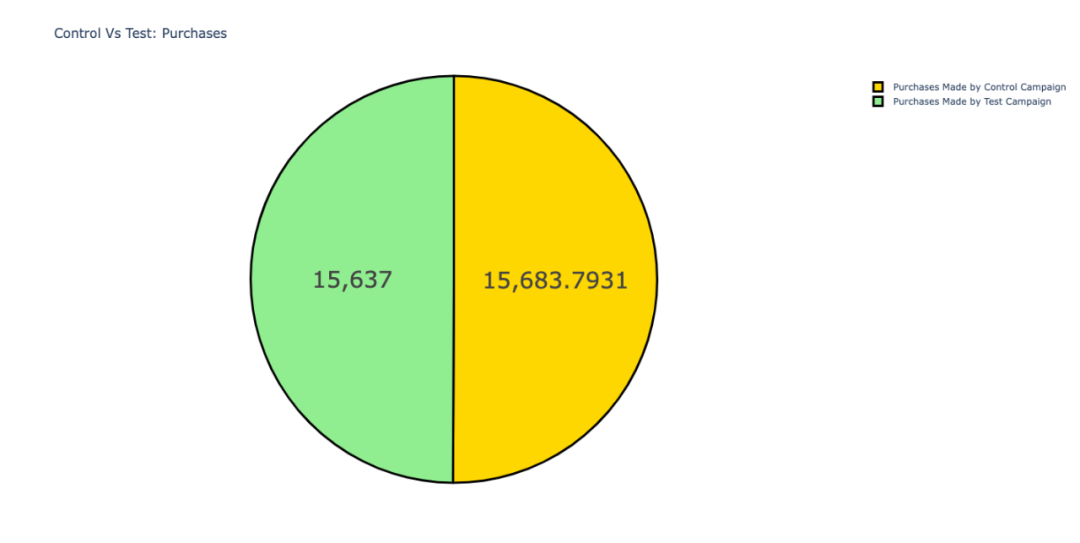
在这两种广告活动当中,消费者的购买量仅相差1%左右。
由于对照活动能以更少的营销支出获得了更多的销售,所以在营销策略上,我们可以选择对照活动类型。
最后让我们分析其它指标,看看哪种广告活动的转化率更高。
08 内容产品查看量和点击量
两种类型活动网站内容查看和点击量的关系。
figure = px.scatter(data_frame=ab_data,
x="Content Viewed",
y="Website Clicks",
size="Website Clicks",
color="Campaign Name",
trendline="ols")
figure.show()
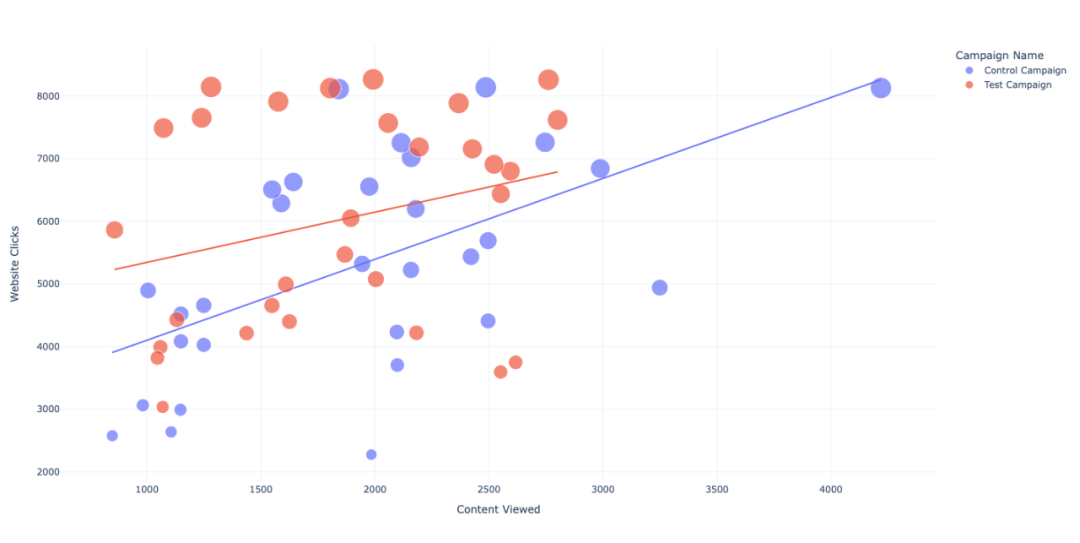
在测试活动中,虽然网站点击率高,但是内容查看量少,所以优先选择「对照活动」。
09 内容产品查看量和添加购物车
分析网站内容查看和添加购物车之间的关系。
figure = px.scatter(data_frame=ab_data,
x="Added to Cart",
y="Content Viewed",
size="Added to Cart",
color="Campaign Name",
trendline="ols")
figure.show()
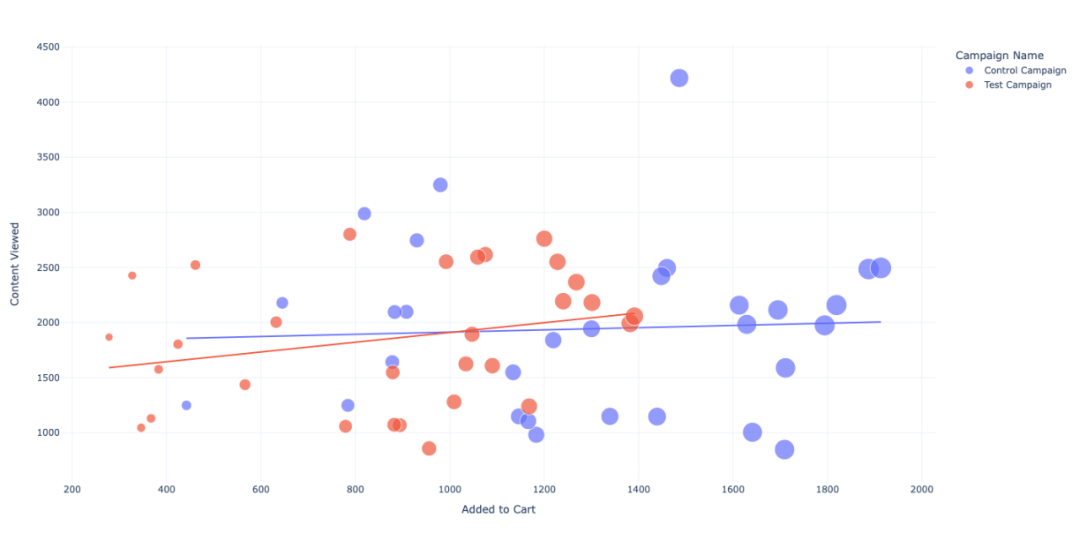
再一次的,「对照活动」的效果还是很好,加入购物车的意向较高。
10 添加购物车和销售额
分析添加到购物车的产品数量和销售额之间的关系。
figure = px.scatter(data_frame=ab_data,
x="Purchases",
y="Added to Cart",
size="Purchases",
color="Campaign Name",
trendline="ols")
figure.show()
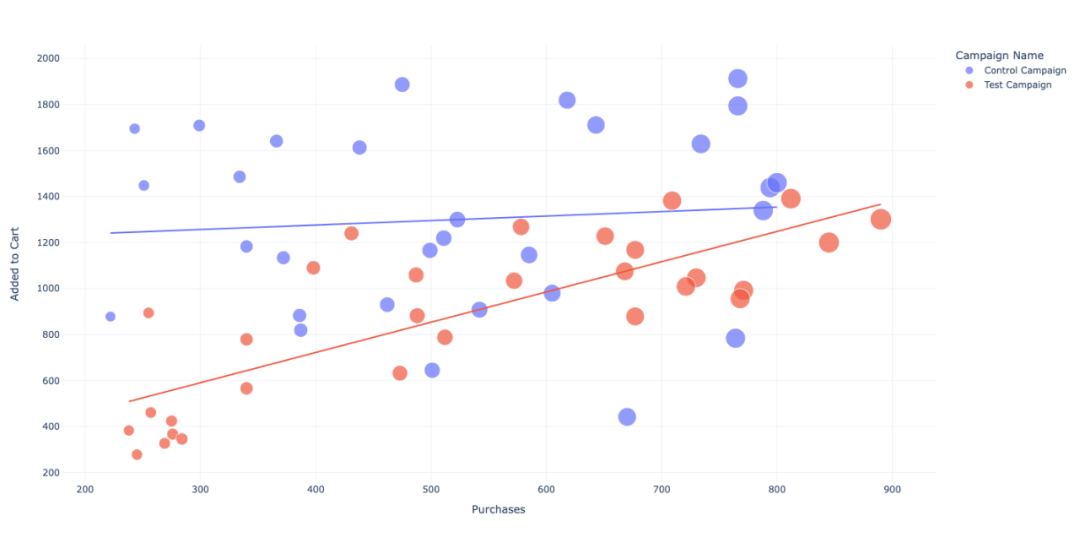
虽然对照活动带来了更多的加购物车行为,但「测试活动」的结算率会更高。
/ 05 / 结论
通过A/B测试,我们发现对照活动带来了更多的销售行为和访问者的参与。
用户会从对照活动中查看了更多的产品,使得购物车中有更多的产品和更多的销售额。
但在测试活动中,用户购物车产品的结算率会更高。
测试活动是根据内容查看和添加到购物车会有更多的销售。而对照活动则是整体销量的增加。
因此,测试活动可以用来向特定的受众推销特定的产品,而对照活动可以用来向更广泛的客户推销多种产品。
到此这篇关于通过Python实现一个A/B测试详解的文章就介绍到这了,更多相关Python A/B测试内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 测试实现方法
1)doctest 使用doctest是一种类似于命令行尝试的方式,用法很简单,如下 复制代码 代码如下: def f(n): """ >>> f(1) 1 >>> f(2) 2 """ print(n) if __name__ == '__main__': import doctest doctest.testmod() 应该来说是足够简单了,另外还有一种方式doctest.testfile(filenam
-

Python实现DBSCAN聚类算法并样例测试
什么是聚类算法?聚类是一种机器学习技术,它涉及到数据点的分组.给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组.理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征.聚类是一种无监督学习的方法,是许多领域中常用的统计数据分析技术. 常用的算法包括K-MEANS.高斯混合模型(Gaussian Mixed Model,GMM).自组织映射神经网络(Self-Organizing Map,SOM) 重点给大家介绍Python实现D
-
利用Python实现网络测试的示例代码
Speedtest CLI 专为软件开发人员.系统管理员和计算机爱好者等打造,是 Ookla® 提供技术支持的首款正式 Linux 本机 Speedtest 应用程序. Speedtest CLI是使用python语言开发的,不仅可以直接在命令行运行.也可以作为python模块在python IDE中直接调用. 首先,看一下如何在python应用中进行调用,使用pip直接安装. pip install speedtest-cli 将该模块直接导入到我们当前的代码块中. import speedt
-
通过Python实现一个A/B测试详解
目录 / 01 / AB测试 / 02 / 使用Python进行AB测试 / 03 / 数据准备 / 04 / AB测试找到最佳营销策略 / 05 / 结论 A/B测试,通过分析两种不同的营销策略,以此来选择最佳的营销策略,可以高效地将流量转化为销售额(或转化为你的预期目标). 有助于找到更好的方法来寻找客户.营销产品.扩大影响范围或将目标客户转化为实际客户. A/B测试是每个学习数据分析同学,都应该知道且去学习的概念. / 01 / AB测试 举个例子,我在短视频App上购买流量推广我的视频(
-
Python之Selenium自动化浏览器测试详解
目录 Python之Selenium(自动化浏览器测试) 1.安装selenium 2.下载对应版本的浏览器驱动 3.测试code,打开一个网页,并获取网页的标题 4.一个小样例 总结 Python之Selenium(自动化浏览器测试) 1.安装selenium pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple 2.下载对应版本的浏览器驱动 http://npm.taobao.org/mirrors/chromedr
-
python+adb+monkey实现Rom稳定性测试详解
我为什么做这项工作? 其实这项工作是另一位同事在做,过程中发下了一些问题,但是种种原因log和数据都没有收集到,无法进行分析.然后我就接手了,负责复现她发现的问题并提供log和数据给开发分析. 需要测试的是一个什么样的功能? 需求是这样的:开发在Framework层增加了app应用权限管控(Android11中基本权限.自动以权限.AIDL),服务端可以通过下发指令到手机,控制app可以访问及不能访问的权限.同时安装app也需要对签名做校验. 该如何开始这项工作呢? 不用多言,自动化是必须的,但
-
Python+Pytest实现压力测试详解
目录 1.程序说明 1.1 设置测试参数 1.2 初始化测试结果 1.3 定义测试函数 1.4 创建线程.执行线程.等待 1.5 计算测试结果 1.6 将测试结果写入文件 2.程序执行 2.1 直接执行 2.2 加个装饰器然后出报告 3.案例缺陷 4 完整源码 在现代Web应用程序中,性能是至关重要的.为了确保应用程序能够在高负载下正常运行,我们需要进行性能测试. 今天,应小伙伴的提问, 田辛老师来写一个Pytest进行压力测试的简单案例. 这个案例的测试网站我们就隐藏了,不过网站的基本情况是:
-
一个Python优雅的数据分块方法详解
目录 1.背景 2.islice 2.1示例 2.2只指定步长 3.iter 3.1常规使用 3.2进阶使用 4.islice 和 iter 组合使用 5.总结 1.背景 看到这个标题你可能想一个分块能有什么难度?还值得细说吗,最近确实遇到一个有意思的分块函数,写法比较巧妙优雅,所以写一个分享. 日前在做需求过程中有一个对大量数据分块处理的场景,具体来说就是几十万量级的数据,分批处理,每次处理100个.这时就需要一个分块功能的代码,刚好项目的工具库中就有一个分块的函数.拿过函数来用,发现还挺好用
-
python算法演练_One Rule 算法(详解)
这样某一个特征只有0和1两种取值,数据集有三个类别.当取0的时候,假如类别A有20个这样的个体,类别B有60个这样的个体,类别C有20个这样的个体.所以,这个特征为0时,最有可能的是类别B,但是,还是有40个个体不在B类别中,所以,将这个特征为0分到类别B中的错误率是40%.然后,将所有的特征统计完,计算所有的特征错误率,再选择错误率最低的特征作为唯一的分类准则--这就是OneR. 现在用代码来实现算法. # OneR算法实现 import numpy as np from sklearn.da
-
Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
Python探索之URL Dispatcher实例详解
URL dispatcher简单点理解就是根据URL,将请求分发到相应的方法中去处理,它是对URL和View的一个映射,它的实现其实也很简单,就是一个正则匹配的过程,事先定义好正则表达式和该正则表达式对应的view方法,如果请求的URL符合这个正则表达式,那么就分发这个请求到这个view方法中. 有了这个base,我们先抛出几个问题,提前思考一下: 这个映射定义在哪里?当映射很多时,如果有效的组织? URL中的参数怎么获取,怎么传给view方法? 如何在view或者是template中反解出UR
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python+requests+unittest API接口测试实例(详解)
我在网上查找了下接口测试相关的资料,大都重点是以数据驱动的形式,将用例维护在文本或表格中,而没有说明怎么样去生成想要的用例, 问题: 测试接口时,比如参数a,b,c,我要先测a参数,有(不传,为空,整形,浮点,字符串,object,过短,超长,sql注入)这些情况,其中一种情况就是一条用例,同时要保证b,c的正确,确保a的测试不受b,c参数的错误影响 解决思路: 符合接口规范的参数可以手动去填写,或者准备在代码库中.那些不符合规范的参数(不传,为空,整形,浮点,字符串,object,过短,超长,