MySql中sql语句执行过程详细讲解
目录
- 前言:
- sql语句的执行过程:
- 查询缓存:
- 分析器:
- 优化器:
- 执行器:
- 总结
前言:
很多人都在使用mysql数据库,但是很少有人能够说出来整个sql语句的执行过程是怎样的,如果不了解执行过程的话,就很难进行sql语句的优化处理,也很难设计出来优良的数据库表结构。这篇文章主要是讲解一下sql语句的执行过程。
sql语句的执行过程:
客户端、连接器、分析器、优化器、执行器、存储引擎几个阶段。
连接器的作用:管理链接、权限验证的处理。
分析器的作用:词法分析、语法分析。
优化器的作用:执行计划的生成、索引选择。
执行器的作用:操作引擎、返回结果。
存储引擎的作用:存储数据、提供读写接口。
另外的一个分支是,会进行查询缓存的操作,如果命中了缓存则直接返回的操作。
mysql可以分为server层和存储引擎层两个部分:
server层:
包括链接器、查询缓存、分析器、优化器、执行器等,涵盖Mysql的大多数核心服务功能,以及所有的内置函数(日期、时间、数学、和加密函数等),所有的存储引擎的功能都在这一部分实现的,比如说存储过程、触发器、视图。
存储引擎:
主要负责数据的存储和提取,其架构模式是插件式的,支持InnoDB、Memory等多个存储引擎。最常用的是InnoDB,这个主要在Mysql5.5版本开始成为了默认存储引擎。
当在执行sql查询的时候,如果不指定引擎类型、默认使用的innoDB。当然也可以指定存储引擎类型进行处理,比如说创建表的时候,可以把存储引擎修改为memory,进行表的创建出合理。当然了,不同的存储引擎的表数据存储方式也是不一样的。
连接器:
执行sql语句的时候,第一步需要进行数据库的连接处理,连接器负责客户端建立连接、获取权限、维持和管理连接。

根据命令可以看出来,主要进行几个参数的输入,IP地址、端口号、以及用户名、密码的处理。连接mysql是客户端工具,用户服务器建立连接,进行tcp握手之后,连接器需要进行身份的验证,然后输入用户名、密码。
密码不对的时候,会收到一个“Access denied for user”的错误提示,然后客户端结束执行。
用户名、密码验证通过之后,连接器就会开始进行权限表查询权限,然后进行权限的操作处理。
连接完成之后,没有进行其他的操作,这个时候连接就处于空闲状态,show processlist。
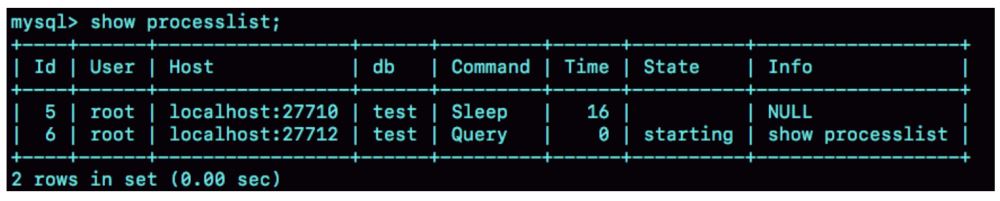
客户端如果长时间不操作的话,默认的等待时间(wait_timeout)是八个小时。
数据库建立连接是比较复杂的,建议在项目中尽量少的建立连接的操作,也就是说尽量使用长连接的处理。
在项目中经常会遇到一种情况就是数据库的长连接,很长时间不关闭的操作,这个时候会导致内存的占用太大,被系统杀掉导致的Mysql的异常。
解决方案有下面两种方案:
- 定期断开长连接,使用一段时间之后,比如说执行一个占用内存的大查询之后,这个时候断开连接,之后要查询的话再重新连接。
- 通过使用命令进行重新初始化连接资源,这个时候需要重连,但是会把连接恢复到初始化的状态。
查询缓存:
连接建立完毕之后,进行查询缓存的处理,执行sql语句会先到缓存中看看是不是刚刚执行了这条语句,之前执行过的语句及其结果就会以key-value对的形式直接存储在内存中的,key是查询的语句,value是查询的结果,如果查询能够直接在这个缓存中找到key,那么这个value可以直接返回给客户端。
如果语句不在查询缓存中的话,就会继续后面的执行阶段,执行完成后,执行结果会被存入查询缓存中。如果可以查询到缓存的话,就不会进行后面的复杂操作了,效率会高很多。
查询缓存的弊端:
查询缓存失败一般情况下会比较频繁,只要对一个表的进行了更新的话,这个表上面所有的缓存就会被清空。因此一般情况下查询缓存的命中率很低。一般情况下,一个系统的配置表或者静态的表才会使用到查询缓存的方式进行处理。
分析器:
分析器首先会进行词法分析,输入的是由多个字符串和空格组成的一条sql语句,mysql需要识别出来里面的字符串分别是什么,代表什么意思。
首先:mysql从输入的select这个关键词识别出来,这个是一个查询的语句,需要把from关键字后面的,字符串t识别出来表名称等等的操作。
然后进行语法分析的处理,根据词法分析,根据词法分析的结果,语句分析器就会根据语法规则判断输入的这个sql语句是否满足mysql的语法。
检查出来错误提示如下图:

一般提示错误的信息只会进行第一个错误的位置。
优化器:
经过了分析器的处理,mysql就知道了该如何进行优化器的处理了,优化器的处理逻辑是在表里面进行多个索引的时候,决定使用那个索引,或者说在一个语句有多个关联的时候,决定各个表的连接顺序的情况,如下图所示:

第一种执行的结果是处理t1.c=10是否走索引,然后可以先判断 一下逻辑的结果是否一样,如果执行的结果是一样的话,可以任意选择一种方案进行处理。
执行器:
- 调用InNoDB引擎接口取这个表的第一行,判断值是否10,如果是10进行集中处理,否则的话就跳过。
- 执行器将遍历过程中所有满足条件的行组成的记录集合返回给客户端。
总结
到此这篇关于MySql中sql语句执行过程详细讲解的文章就介绍到这了,更多相关MySql sql语句执行过程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
简单了解mysql语句书写和执行顺序
mysql语句的书写顺序和执行顺序有很大差异. 书写顺序,mysql的一般书写顺写为: select <要返回的数据列> from <表名> <join, left join, right join...> join <join表> on <join条件> where <where条件> group by <分组条件> having <分组后的筛选条件> order by <排序条件> limit
-
MySQL语句执行顺序和编写顺序实例解析
select语句完整语法: SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_
-

详解一条sql语句在mysql中是如何执行的
概览 最近开始在学习mysql相关知识,自己根据学到的知识点,根据自己的理解整理分享出来,本篇文章会分析下一个sql语句在mysql中的执行流程,包括sql的查询在mysql内部会怎么流转,sql语句的更新是怎么完成的. 一.mysql架构分析 下面是mysql的一个简要架构图: mysql主要分为Server层和存储引擎层 Server层:主要包括连接器.查询缓存.分析器.优化器.执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程.触发器.视图,函数等,还有一个通用的日志模块 bing
-
一条SQL语句在MySQL中是如何执行的
目录 一.mysql架构分析 1.1 连接器 1.2 查询缓存 1.3 分析器 1.4 优化器 1.5 执行器 二.语句分析 2.1 查询语句 2.2 更新语句 三.总结 一.mysql架构分析 下面是mysql的一个简要架构图: mysql主要分为Server层和存储引擎层 Server层:主要包括连接器.查询缓存.分析器.优化器.执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程.触发器.视图,函数等,还有一个通用的日志模块 binglog日志模块. 存储引擎: 主要负责数据的存储和
-
MySql中sql语句执行过程详细讲解
目录 前言: sql语句的执行过程: 查询缓存: 分析器: 优化器: 执行器: 总结 前言: 很多人都在使用mysql数据库,但是很少有人能够说出来整个sql语句的执行过程是怎样的,如果不了解执行过程的话,就很难进行sql语句的优化处理,也很难设计出来优良的数据库表结构.这篇文章主要是讲解一下sql语句的执行过程. sql语句的执行过程: 客户端.连接器.分析器.优化器.执行器.存储引擎几个阶段. 连接器的作用:管理链接.权限验证的处理. 分析器的作用:词法分析.语法分析. 优化器的作用:执行计
-
一条 SQL 语句执行过程
目录 一.MySQL体系架构 -连接池组件 -缓存组件 -分析器 -优化器 -执行器 二.写操作执行过程 三.读操作执行过程 四.SQL执行顺序 一.MySQL 体系架构 - 连接池组件 1.负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向服务器请求或者服务器向客户端发送数据,而不能同时进行. 2.验证用户名和密码是否正确(数据库 MySQL 的 user 表中进行验证),如果错误返回错误通知Access denied for user 'root'@'localhost'
-
SpringMVC执行过程详细讲解
目录 SpringMVC常用组件 DispatcherServlet初始化过程 SpringMVC的执行流程 SpringMVC常用组件 DispatcherServlet:前端控制器,不需要工程师开发,由框架提供 作用:统一处理请求和响应,整个流程控制的中心,由它调用其它组件处理用户的请求 HandlerMapping:处理器映射器,不需要工程师开发,由框架提供 作用:根据请求的url.method等信息查找Handler,即控制器方法 Handler:处理器,需要工程师开发 作用:在Disp
-
细数MySQL中SQL语句的分类
1:数据定义语言(DDL) 用于创建.修改.和删除数据库内的数据结构,如:1:创建和删除数据库(CREATE DATABASE || DROP DATABASE):2:创建.修改.重命名.删除表(CREATE TABLE || ALTER TABLE|| RENAME TABLE||DROP TABLE):3:创建和删除索引(CREATEINDEX || DROP INDEX) 2:数据查询语言(DQL) 从数据库中的一个或多个表中查询数据(SELECT) 3:数据操作语
-
MyBatis核心源码深度剖析SQL语句执行过程
目录 1 SQL语句的执行过程介绍 2 SQL执行的入口分析 2.1 为Mapper接口创建代理对象 2.2 执行代理逻辑 3 查询语句的执行过程分析 3.1 selectOne方法分析 3.2 sql获取 3.3 参数设置 3.4 SQL执行和结果集的封装 4 更新语句的执行过程分析 4.1 sqlsession增删改方法分析 4.2 sql获取 4.3 参数设置 4.4 SQL执行 5 小结 1 SQL语句的执行过程介绍 MyBatis核心执行组件: 2 SQL执行的入口分析 2.1 为Ma
-
有关mysql中sql的执行顺序的小问题
今天工作中碰到一个sql问题,关于left join的,后面虽然解决了,但是通过此问题了解了一下sql的执行顺序 场景还原 为避免安全纠纷,把场景模拟. 有一个学生表-S,一个成绩表G CREATE TABLE `test_student` ( `id` bigint(20) NOT NULL COMMENT '学号', `sex` TINYINT DEFAULT '0' COMMENT '性别 0-男 1-女', `name` varchar(255) DEFAULT NULL COMMENT
-
Mysql中SQL语句不使用索引的情况
MySQL查询不使用索引汇总 众所周知,增加索引是提高查询速度的有效途径,但是很多时候,即使增加了索引,查询仍然不使用索引,这种情况严重影响性能,这里就简单总结几条MySQL不使用索引的情况 如果MySQL估计使用索引比全表扫描更慢,则不使用索引.例如,如果列key均匀分布在1和100之间,下面的查询使用索引就不是很好:select * from table_name where key>1 and key<90; 如果使用MEMORY/HEAP表,并且where条件中不使用"=&q
-
了解MySQL查询语句执行过程(5大组件)
目录 开篇 查询请求的执行流程 MySQL组件定义 连接器 查询缓存 分析器 优化器 逻辑变换 代价优化 执行器 总结 开篇 相信广大程序员朋友经常使用MySQL数据库作为书籍持久化的工具,我们最常使用的就是MySQL中的SQL语句,从客户端向MySQL发出一条条指令,然后获取返回的数据结果进行后面的逻辑处理.尽管大家经常使用SQL语句完成工作,你是否关注过其执行的阶段,利用了哪些技术完成?今天,就带大家一起看看MySQL数据库处理SQL请求的全过程.下面将会讲述如下内容: 查询请求在MySQL