C++简易版Tensor实现方法详解
目录
- 基础知识铺垫
- 内存管理 allocate
- 实现Tensor需要准备shape和storage
- Tensor的设计方法(基础)
- Tensor的设计方法(更进一步)
基础知识铺垫
- 缺省参数
- 异常处理
- 如果有模板元编程经验更好
- std::memset、std::fill、std::fill_n、std::memcpy
std::memset 的内存填充单位固定为字节(char),所以不能应用与double,非char类型只适合置0。
std::fill 和 std::fill_n 则可以对指定类型进行内存填充,更加通用。
std::memcpy 则可以讲内存中排列好的数据拷贝过去,不同位置可填充不同值。
double dp[505]; std::memset(dp, -1.0, 505 * sizeof(double));//错误的 ★★★,memset的单位是字节(char),我们需要的是fill
double dp[505]; std::fill(dp, dp + 505, -1.0); std::fill(std::begin(dp), std::end(dp), -1.0); std::fill_n(dp, 505, -1.0);
double dp[505];
double data[5] = {11,22,33,44,55};
std::memcpy(dp, data, 5 * sizeof(double))
内存管理 allocate
在c++11中引入了智能指针这个概念,这个非常好,但是有一个问题显然被忘记了,如何动态创建智能指针数组,在c++11中没有提供直接的函数。换句话说,创建智能指针的make_shared,不支持创建数组。那在c++11中如何创建一个智能指针数组呢?只能自己封装或者变通实现,在c++14后可以支持构造函数创建智能指针数组,可这仍然不太符合技术规范发展的一致性,可继承性。
共享指针share_ptr 和 唯一指针unique_ptr 可能并不是一个很完整的方式,因为默认情况下需要开发人员手动的指定 delete handler。 但是只需要简单的封装一下就可以是更智能的方式,就是自动生成 delete handler。并且不必使用new(或者其他的指针形式)作为构造参数,而是直接通过 allocate 和 construct 两种形式,最抽象简单直观的方式得到想要的。
shared_ptr<T> pt0(new T());// 将会自动采用 std::default_delete
shared_ptr<int> p1 = make_shared<int>();
//指定 default_delete 作为释放规则
std::shared_ptr<int> p6(new int[10], std::default_delete<int[]>());
//自定义释放规则
void deleteInt(int*p) { delete []p; }
std::shared_ptr<int> p3(new int[10], deleteInt);
我们期待的规范后是这样使用的:不用考虑 释放规则,而且分为 allocate 和 construct 两种形式。
auto uptr = Alloc::unique_allocate<Foo>(sizeof(Foo));
auto sptr = Alloc::shared_allocate<Foo>(sizeof(Foo));
auto uptr = Alloc::unique_construct<Foo>();
auto sptr = Alloc::shared_construct<Foo>('6', '7');
allocator.h
#ifndef UTILS_ALLOCATOR_H
#define UTILS_ALLOCATOR_H
#include <cstdlib>
#include <map>
#include <memory>
#include <utility>
#include "base_config.h"
namespace st {
// 工具类(单例)
class Alloc {
public:
// allocate 删除器
class trivial_delete_handler {
public:
trivial_delete_handler(index_t size_) : size(size_) {}
void operator()(void* ptr) { deallocate(ptr, size); }
private:
index_t size;
};
// construct 删除器
template<typename T>
class nontrivial_delete_handler {
public:
void operator()(void* ptr) {
static_cast<T*>(ptr)->~T();
deallocate(ptr, sizeof(T));
}
};
// unique_ptr :对应 allocate
template<typename T>
using TrivialUniquePtr = std::unique_ptr<T, trivial_delete_handler>;
// unique_ptr :对应 construct
template<typename T>
using NontrivialUniquePtr = std::unique_ptr<T, nontrivial_delete_handler<T>>;
// I know it's weird here. The type has been already passed in as T, but the
// function parameter still need the number of bytes, instead of objects.
// And their relationship is
// nbytes = nobjects * sizeof(T).
// Check what I do in "tensor/storage.cpp", and you'll understand.
// Or maybe changing the parameter here and doing some extra work in
// "tensor/storage.cpp" is better.
// 共享指针 allocate
// 目的:自动生成 delete handler
template<typename T>
static std::shared_ptr<T> shared_allocate(index_t nbytes) {
void* raw_ptr = allocate(nbytes);
return std::shared_ptr<T>(
static_cast<T*>(raw_ptr),
trivial_delete_handler(nbytes)
);
}
// 唯一指针 allocate
// 目的:自动生成 delete handler
template<typename T>
static TrivialUniquePtr<T> unique_allocate(index_t nbytes) {
//开辟 内存
void* raw_ptr = allocate(nbytes);
//返回 unique_ptr(自动生成了删除器)
return TrivialUniquePtr<T>(
static_cast<T*>(raw_ptr),
trivial_delete_handler(nbytes)
);
}
// 共享指针 construct
// 目的:自动生成 delete handler
template<typename T, typename... Args>
static std::shared_ptr<T> shared_construct(Args&&... args) {
void* raw_ptr = allocate(sizeof(T));
new(raw_ptr) T(std::forward<Args>(args)...);
return std::shared_ptr<T>(
static_cast<T*>(raw_ptr),
nontrivial_delete_handler<T>()
);
}
// 唯一指针 construct
// 目的:自动生成 delete handler
template<typename T, typename... Args>
static NontrivialUniquePtr<T> unique_construct(Args&&... args) {
void* raw_ptr = allocate(sizeof(T));
new(raw_ptr) T(std::forward<Args>(args)...);
return NontrivialUniquePtr<T>(
static_cast<T*>(raw_ptr),
nontrivial_delete_handler<T>()
);
}
static bool all_clear(void);
private:
Alloc() = default;
~Alloc(){
/* release unique ptr, the map will not do destruction!!! */
for (auto iter = cache_.begin(); iter != cache_.end(); ++iter) { iter->second.release(); }
}
static Alloc& self(); // 单例
static void* allocate(index_t size);
static void deallocate(void* ptr, index_t size);
static index_t allocate_memory_size;
static index_t deallocate_memory_size;
struct free_deletor {
void operator()(void* ptr) { std::free(ptr); }
};
// multimap 允许容器有重复的 key 值
// 保留开辟过又释放掉的堆内存,再次使用的时候可重复使用(省略了查找可用堆内存的操作)
std::multimap<index_t, std::unique_ptr<void, free_deletor>> cache_;
};
} // namespace st
#endif
allocator.cpp
#include "allocator.h"
#include "exception.h"
#include <iostream>
namespace st {
index_t Alloc::allocate_memory_size = 0;
index_t Alloc::deallocate_memory_size = 0;
Alloc& Alloc::self() {
static Alloc alloc;
return alloc;
}
void* Alloc::allocate(index_t size) {
auto iter = self().cache_.find(size);
void* res;
if(iter != self().cache_.end()) {
// 临时:为什么要这么做?找到了为社么要删除
res = iter->second.release();//释放指针指向内存
self().cache_.erase(iter);//擦除
} else {
res = std::malloc(size);
CHECK_NOT_NULL(res, "failed to allocate %d memory.", size);
}
allocate_memory_size += size;
return res;
}
void Alloc::deallocate(void* ptr, index_t size) {
deallocate_memory_size += size;
// 本质上是保留保留 堆内存中的位置,下一次可直接使用,而不是重新开辟
self().cache_.emplace(size, ptr); // 插入
}
bool Alloc::all_clear() {
return allocate_memory_size == deallocate_memory_size;
}
} // namespace st
使用:封装成 unique_allocate、unique_construct、share_allocate、share_construct 的目的就是对 share_ptr 和 unique_ptr 的生成自动赋予其对应的 delete handler。
struct Foo {
static int ctr_call_counter;
static int dectr_call_counter;
char x_;
char y_;
Foo() { ++ctr_call_counter; }
Foo(char x, char y) : x_(x), y_(y) { ++ctr_call_counter; }
~Foo() { ++dectr_call_counter; }
};
int Foo::ctr_call_counter = 0;
int Foo::dectr_call_counter = 0;
void test_Alloc() {
using namespace st;
// allocate 开辟空间
// construct 开辟空间 + 赋值
void* ptr;
{//
auto uptr = Alloc::unique_allocate<Foo>(sizeof(Foo));
CHECK_EQUAL(Foo::ctr_call_counter, 0, "check 1");
ptr = uptr.get();
}
CHECK_EQUAL(Foo::dectr_call_counter, 0, "check 1");
{
auto sptr = Alloc::shared_allocate<Foo>(sizeof(Foo));
// The strategy of allocator.
CHECK_EQUAL(ptr, static_cast<void*>(sptr.get()), "check 2");
}
{
auto uptr = Alloc::unique_construct<Foo>();
CHECK_EQUAL(Foo::ctr_call_counter, 1, "check 3");
CHECK_EQUAL(ptr, static_cast<void*>(uptr.get()), "check 3");
}
CHECK_EQUAL(Foo::dectr_call_counter, 1, "check 3");
{
auto sptr = Alloc::shared_construct<Foo>('6', '7');
CHECK_EQUAL(Foo::ctr_call_counter, 2, "check 4");
CHECK_TRUE(sptr->x_ == '6' && sptr->y_ == '7', "check 4");
CHECK_EQUAL(ptr, static_cast<void*>(sptr.get()), "check 4");
}
CHECK_EQUAL(Foo::dectr_call_counter, 2, "check 4");
}
实现Tensor需要准备shape和storage
shape 管理形状,每一个Tensor的形状都是唯一的(采用 unique_ptr管理数据),见array.h 个 shape.h。
storage:管理数据,不同的Tensor的数据可能是同一份数据(share_ptr管理数据),见stroage.h。
array.h
#ifndef UTILS_ARRAY_H
#define UTILS_ARRAY_H
#include <initializer_list>
#include <memory>
#include <cstring>
#include <iostream>
// utils
#include "base_config.h"
#include "allocator.h"
namespace st {
// 应用是 tensor 的 shape, shape 是唯一的, 所以用 unique_ptr
// 临时:实际上并不是很完善,目前的样子有点对不起这个 Dynamic 单词
template<typename Dtype>
class DynamicArray {
public:
explicit DynamicArray(index_t size)
: size_(size),
dptr_(Alloc::unique_allocate<Dtype>(size_ * sizeof(Dtype))) {
}
DynamicArray(std::initializer_list<Dtype> data)
: DynamicArray(data.size()) {
auto ptr = dptr_.get();
for(auto d: data) {
*ptr = d;
++ptr;
}
}
DynamicArray(const DynamicArray<Dtype>& other)
: DynamicArray(other.size()) {
std::memcpy(dptr_.get(), other.dptr_.get(), size_ * sizeof(Dtype));
}
DynamicArray(const Dtype* data, index_t size)
: DynamicArray(size) {
std::memcpy(dptr_.get(), data, size_ * sizeof(Dtype));
}
explicit DynamicArray(DynamicArray<Dtype>&& other) = default;
~DynamicArray() = default;
Dtype& operator[](index_t idx) { return dptr_.get()[idx]; }
Dtype operator[](index_t idx) const { return dptr_.get()[idx]; }
index_t size() const { return size_; }
// 注意 std::memset 的单位是字节(char),若不是char类型,只用来置0,否则结果错误
// 临时:std::memset 对非char类型只适合内存置0,如果想要更加通用,不妨考虑一下 std::fill 和 std::fill_n
void memset(int value) const { std::memset(dptr_.get(), value, size_ * sizeof(Dtype)); } //原
void fill(int value) const (std::fill_n, size_, value); //改:见名知意
private:
index_t size_;
Alloc::TrivialUniquePtr<Dtype> dptr_;
};
} // namespace st
#endif
stroage.h
#ifndef TENSOR_STORAGE_H
#define TENSOR_STORAGE_H
#include <memory>
#include "base_config.h"
#include "allocator.h"
namespace st {
namespace nn {
class InitializerBase;
class OptimizerBase;
}
class Storage {
public:
explicit Storage(index_t size);
Storage(const Storage& other, index_t offset); //观察:offset 具体应用?bptr_数据依然是同一份,只是dptr_指向位置不同,这是关于pytorch的clip,切片等操作的设计方法
Storage(index_t size, data_t value);
Storage(const data_t* data, index_t size);
explicit Storage(const Storage& other) = default;//复制构造(因为数据都是指针形式,所以直接默认就行)
explicit Storage(Storage&& other) = default;//移动构造(因为数据都是指针形式,所以直接默认就行)
~Storage() = default;
Storage& operator=(const Storage& other) = delete;
// inline function
data_t operator[](index_t idx) const { return dptr_[idx]; }
data_t& operator[](index_t idx) { return dptr_[idx]; }
index_t offset(void) const { return dptr_ - bptr_->data_; }//
index_t version(void) const { return bptr_->version_; }//
void increment_version(void) const { ++bptr_->version_; }//???
// friend function
friend class nn::InitializerBase;
friend class nn::OptimizerBase;
public:
index_t size_;
private:
struct Vdata {
index_t version_; //???
data_t data_[1]; //永远指向数据头
};
std::shared_ptr<Vdata> bptr_; // base pointer, share_ptr 的原因是不同的tensor可能指向的是storage数据
data_t* dptr_; // data pointer, 指向 Vdata 中的 data_, 他是移动的(游标)
};
} // namespace st
#endif
storage.cpp
#include <iostream>
#include <cstring>
#include <algorithm>
#include "storage.h"
namespace st {
Storage::Storage(index_t size)
: bptr_(Alloc::shared_allocate<Vdata>(size * sizeof(data_t) + sizeof(index_t))),
dptr_(bptr_->data_)
{
bptr_->version_ = 0;
this->size_ = size;
}
Storage::Storage(const Storage& other, index_t offset)
: bptr_(other.bptr_),
dptr_(other.dptr_ + offset)
{
this->size_ = other.size_;
}
Storage::Storage(index_t size, data_t value)
: Storage(size) {
//std::memset(dptr_, value, size * sizeof(data_t)); // 临时
std::fill_n(dptr_, size, value);
}
Storage::Storage(const data_t* data, index_t size)
: Storage(size) {
std::memcpy(dptr_, data, size * sizeof(data_t));
}
} // namespace st
shape.h
#ifndef TENSOR_SHAPE_H
#define TENSOR_SHAPE_H
#include <initializer_list>
#include <ostream>
#include "base_config.h"
#include "allocator.h"
#include "array.h"
namespace st {
class Shape {
public:
// constructor
Shape(std::initializer_list<index_t> dims);
Shape(const Shape& other, index_t skip);
Shape(index_t* dims, index_t dim);
Shape(IndexArray&& shape);
Shape(const Shape& other) = default;
Shape(Shape&& other) = default;
~Shape() = default;
// method
index_t dsize() const;
index_t subsize(index_t start_dim, index_t end_dim) const;
index_t subsize(index_t start_dim) const;
bool operator==(const Shape& other) const;
// inline function
index_t ndim(void) const { return dims_.size(); }
index_t operator[](index_t idx) const { return dims_[idx]; }
index_t& operator[](index_t idx) { return dims_[idx]; }
operator const IndexArray() const { return dims_; }
// friend function
friend std::ostream& operator<<(std::ostream& out, const Shape& s);
private:
IndexArray dims_; // IndexArray 就是(DynamicArray)
};
} // namespace st
#endif
shape.cpp
#include "shape.h"
namespace st {
Shape::Shape(std::initializer_list<index_t> dims) : dims_(dims) {}
Shape::Shape(const Shape& other, index_t skip) : dims_(other.ndim() - 1) {
int i = 0;
for (; i < skip; ++i)
dims_[i] = other.dims_[i];
for (; i < dims_.size(); ++i)
dims_[i] = other.dims_[i + 1];
}
Shape::Shape(index_t* dims, index_t dim_) : dims_(dims, dim_) {}
Shape::Shape(IndexArray&& shape) : dims_(std::move(shape)) {}
index_t Shape::dsize() const {
int res = 1;
for (int i = 0; i < dims_.size(); ++i)
res *= dims_[i];
return res;
}
index_t Shape::subsize(index_t start_dim, index_t end_dim) const {
int res = 1;
for (; start_dim < end_dim; ++start_dim)
res *= dims_[start_dim];
return res;
}
index_t Shape::subsize(index_t start_dim) const {
return subsize(start_dim, dims_.size());
}
bool Shape::operator==(const Shape& other) const {
if (this->ndim() != other.ndim()) return false;
index_t i = 0;
for (; i < dims_.size() && dims_[i] == other.dims_[i]; ++i)
;
return i == dims_.size();
}
std::ostream& operator<<(std::ostream& out, const Shape& s) {
out << '(' << s[0];
for (int i = 1; i < s.ndim(); ++i)
out << ", " << s[i];
out << ")";
return out;
}
} // namespace st
Tensor的设计方法(基础)
知识准备:继承、指针类、奇异递归模板(静态多态)、表达式模板、Impl设计模式(声明实现分离)、友元类、模板特化。
tensor的设计采用的 impl 方法(声明和实现分离), 采用了奇异递归模板(静态多态),Tensor本身管理Tensor的张量运算,Exp则管理引用计数、梯度计数(反向求导,梯度更新时需要用到)的运算。
一共5个类:Tensor,TensorImpl,Exp,ExpImpl,ExpImplPtr,他们之间的关系由下图体现。
先上图:
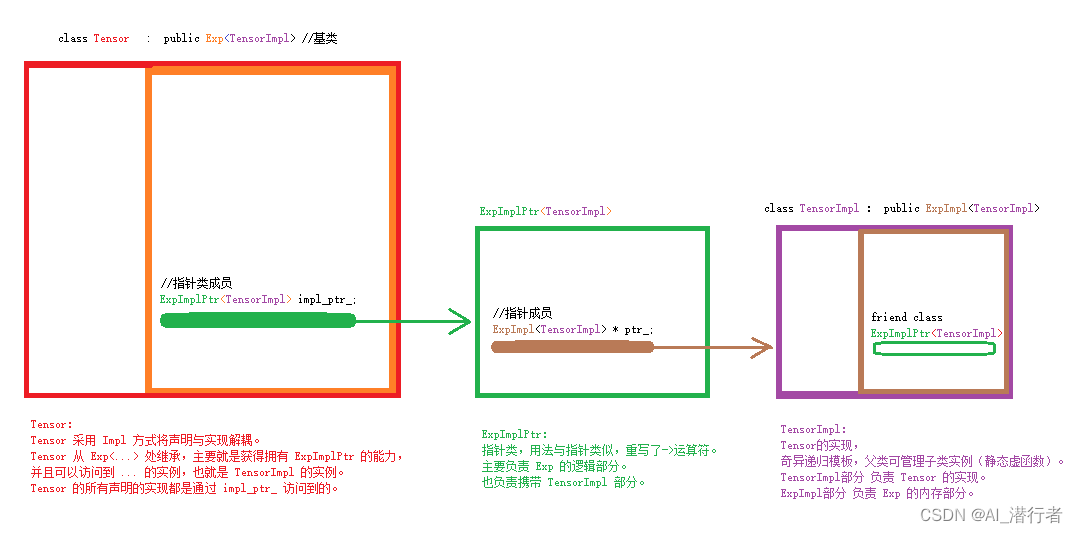
代码:
// 代码比较多,就不放在这了,参看源码结合注释理解
Tensor的设计方法(更进一步)
Tensor 数据内存分布管理
Tensor的数据只有独一份,那么Tensor的各种操作 transpose,purmute,slice,等等,难道都要生出一个新的 tensor 和对应新的数据吗?当然不可能,能用一份数据的绝不用两份!tensor 数据的描述主要有 size(总数数据量),offset(此 tensor 相对于原始base数据的一个偏移量) ndim(几个维度),shape(每个维度映射的个数),stride(每个维度中数据的索引步长),stride 和 shape是 一 一 对应的,通过这个stride的索引公式,我们就可以用一份数据幻化出不同的tensor表象了。解析如下图

permute(轴换位置):shape 和 stride 调换序列一致即可。
transpose(指定两个轴换位置,转置):同上,与permute一致。
slice(切片):在原始数据上增加了一个偏移量。Tensor中的数据部分Storage中有一个bptr_(管理原始数据)和dptr_(管理当前tensor的数据指向)。
unsqueese(升维):指定dim加一个维度,且shape值为1,stride值则根据shape的subsize(dim)算出即可。
squeese(降维):dim为1的将自动消失并降维,shape 和 stride 对应位子都会去掉。
view(变形):目前是只支持连续数据分布且数据的size总和不变的情况,比如permute、transpose就会破坏这种连续。slice就会破坏数据size不一致。
到此这篇关于C++简易版Tensor实现方法详解的文章就介绍到这了,更多相关C++简易版Tensor内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++调用tensorflow教程
目前深度学习越来越火,学习.使用tensorflow的相关工作者也越来越多.但是目前绝大部分的python都是拥有着丰富的python的API,而c++的API不够完善.这就导致绝大多是使用tensorflow的项目都是基于python. 如果项目是由c++编写,想调用python下的tensorflow?可参考本教程(tensorflow模型是CNN卷积神经网络) 具体步骤: 1.python环境 首先安装python,可以在Anaconda官网直接下载.记住python一定选择64bit,目
-
C++ TensorflowLite模型验证的过程详解
故事是这样的: 有一个手撑检测的tflite模型,需要在开发板上跑起来.手机版本的已成熟,要移植到开发板上.现在要验证tflite模型文件在板子上的运行结果要和手机上一致. 前提:为了多次重复测试,在Android端使用了同一帧数据(从一个录制的mp4中固定取一张图)测试代码如下图 下面是测试过程 记录下Android版API运行推理前的图片数据文件(经过了规一化处理,所以都是-1~1之间的float数据) 这一步卡在了写float数据到二进制文件中,C++读出来有问题换了个方案,直接存储flo
-
C++简易版Tensor实现方法详解
目录 基础知识铺垫 内存管理 allocate 实现Tensor需要准备shape和storage Tensor的设计方法(基础) Tensor的设计方法(更进一步) 基础知识铺垫 缺省参数 异常处理 如果有模板元编程经验更好 std::memset.std::fill.std::fill_n.std::memcpy std::memset 的内存填充单位固定为字节(char),所以不能应用与double,非char类型只适合置0. std::fill 和 std::fill_n 则可以对指定类
-
Java实现简易拼图游戏的方法详解
目录 效果展示 游戏结构 实现代码 效果展示 介绍:游戏共有五张图片可以选择,分成了4 X 4 十六个方格,点击开始就可以开始游戏.游戏运行的截图如下: 游戏结构 实现代码 代码如下:MedleyGame.java类 package game.medleyPicture; import java.awt.BorderLayout; import java.awt.GridLayout; import java.awt.event.ActionEvent; import java.awt.even
-
mysql 5.6.13 免安装版配置方法详解
本文给大家记录在上个项目中涉及到免安装版的mysql的配置问题,今天小编把配置方法分享到我们平台供大家学习. 1. 下载mysql Community Server 5.6.13 2. 解压MySQL压缩包 将以下载的MySQL压缩包解压到自定义目录下,我的解压目录是: "D:\Program Files\MySQL\mysql-5.6.13-win32" 将解压目录下默认文件 my-default.ini 拷贝一份,改名 my.ini 复制下面的配置信息到 my.ini 保存 #如果
-
2020版IDEA整合GitHub的方法详解
1.前提电脑安装好Git需要有个已经注册的GitHub帐号2.在IDEA中设置Git2.1 确保IDEA安装Git GitHub插件 2.2 在IDEA中设置Git,在File–>Setting->Version Control–>Git–>Path to Git executable选择你的git安装后的git.exe文件,然后点击Test,测试是否设置成功 2.3 在IDEA中设置GitHub,File–>Setting->Version Control–>G
-
Python使用Asyncio进行web编程方法详解
目录 前言 什么是同步编程 什么是异步编程 ayncio 版 Hello 程序 如何使用 asyncio 总结 前言 许多 Web 应用依赖大量的 I/O (输入/输出) 操作,比如从网站上下载图片.视频等内容:进行网络聊天或者针对后台数据库进行多次查询.数据库查询可能会耗费大量时间,尤其是在该数据库处于高负载或查询很复杂的情况下. Web 服务器可能需要同时处理数百或数千个请求. I/O 是指计算机的输入和输出设备,例如键盘.硬盘驱动器,以及最常见的网卡.这些操作等待用户输入或从基于 Web
-
C++实现defer声明方法详解
目录 一.前言 二.实现 2.1 相关技术 2.2 实现 2.3 对外接口 三.测试 本文代码地址:https://github.com/pengguoqing/samples_code 一.前言 在Go 语言里面有一个 defer 声明, 它的作用是将函数调用保存在列表中, 函数返回时依次调用列表中的函数. 之前实现简易版的智能指针文章中指出, 智能指针内部就是利用的 RAII特点, 将对象的声明周期使用栈来管理. 因此可以借鉴 Go语言中的 defer逻辑, 然后结合RAII的特点来实
-
优化Tomcat配置(内存、并发、缓存等方面)方法详解
Tomcat有很多方面,我从内存.并发.缓存等方面介绍优化方法. 一.Tomcat内存优化 Tomcat内存优化主要是对 tomcat 启动参数优化,我们可以在 tomcat 的启动脚本 catalina.sh 中设置 java_OPTS 参数. JAVA_OPTS参数说明 server 启用jdk 的 server 版: -Xms java虚拟机初始化时的最小内存: -Xmx java虚拟机可使用的最大内存: -XX: PermSize 内存永久保留区域 -XX:MaxPermSize 内存最
-
Mysql的基础使用之MariaDB安装方法详解
我首次用mysql是在ubuntu上,现在用的是linux 中的Red Hat 分支的centOS 7 ,安装时发现通常用的都是MariaDB 来代替mysql,通过资料查询发现Mariadb是mysql的其中的一种分支,由mysql的创始人带领的团队所开发的mysql分支的一种版本,因为mysql受到被Oracle收购后的日渐封闭与缓慢的更新,众多Linux发行版逐渐抛弃了这个人气开源数据库,使MySQL在各大Linux发行版中的失势由于不满MySQL被Oracle收购后的日渐封闭与缓慢的更新
-
CentOS 7.0下使用yum安装mysql的方法详解
CentOS7默认数据库是mariadb,配置等用着不习惯,因此决定改成mysql,但是CentOS7的yum源中默认好像是没有mysql的.为了解决这个问题,我们要先下载mysql的repo源. 1.下载mysql的repo源 $ wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 2.安装mysql-community-release-el7-5.noarch.rpm包 $ sudo rpm -ivh mys
-
YUM解决RPM包安装依赖关系及yum工具介绍本地源配置方法详解
1.背景概述 在实际生产环境下,对于在linux系统上安装rpm包,主要面临两个实际的问题 1)安装rpm包过程中,不断涌现的依赖关系问题,导致需要按照提示或者查询资料,手工安装更多的包 2)由于内外网的隔离,无法连接外网的yum源 鉴于上述因此,本文将详细介绍,yum工具以及配置本地yum源的方法 2.yum工具简介 •yum工具作为rpm包的软件管理器,可以进行rpm包的安装.升级以及删除等日常管理工作,而且对于rpm包之间的依赖关系可以自动分析,大大简化了rpm包的维护成本. •yum工具