Pandas数据分析-pandas数据框的多层索引
目录
- 前言
- 创建多层索引
- 多层索引操作
- 索引名称的查看
- 索引的层级
- 索引内容的查看
- 数据查询
- 数据分组
前言
pandas数据框针对高维数据,也有多层索引的办法去应对。多层数据一般长这个样子
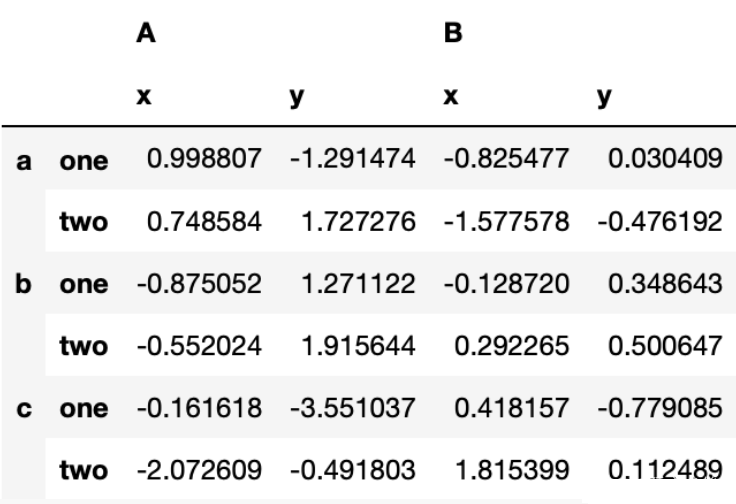
可以看到AB两大列,下面又有xy两小列。 行有abc三行,又分为onetwo两小行。
在分组聚合的时候也会产生多层索引,下面演示一下。
导入包和数据:
import numpy as np
import pandas as pd
df=pd.read_excel('team.xlsx')
分组聚合:
df.groupby(['team',df.mean(1)>60]).count() #每组平均分大于60的人的个数
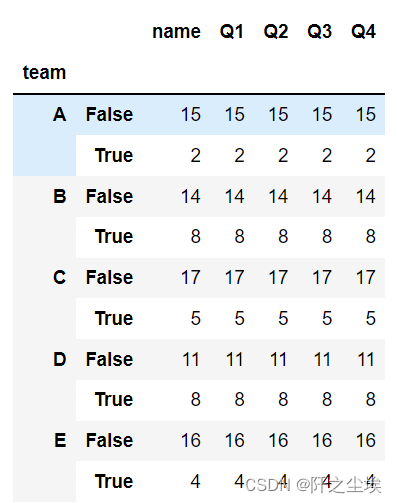
可以看到分为abcde五组,平均分大于60 的组员两小行。
创建多层索引
#序列中创建
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
index=pd.MultiIndex.from_arrays(arrays, names=('number', 'color'))
index

pd.DataFrame([{'a':1, 'b':2}], index=index)

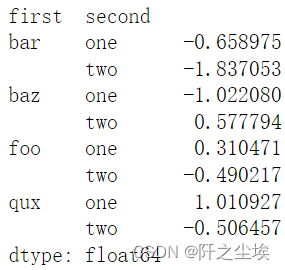
#来自元组创建
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
pd.Series(np.random.randn(8), index=index)
#可迭代对象的笛卡尔积,排列组合各种情况 numbers = [0, 1, 2] colors = ['green', 'purple'] index = pd.MultiIndex.from_product([numbers, colors],names=['number', 'color']) pd.Series(np.random.randn(6), index=index)

#来自 DataFrame
df = pd.DataFrame([['bar', 'one'], ['bar', 'two'],
['foo', 'one'], ['foo', 'two']],
columns=['first', 'second'])
'''
first second
0 bar one
1 bar two
2 foo one
3 foo two
'''
index = pd.MultiIndex.from_frame(df)
pd.Series(np.random.randn(4), index=index)

多层索引操作
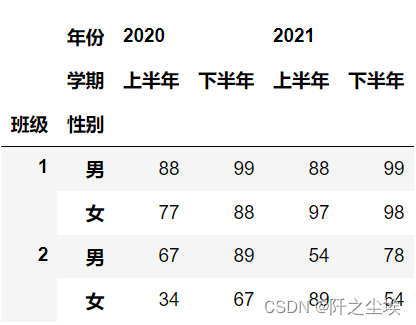
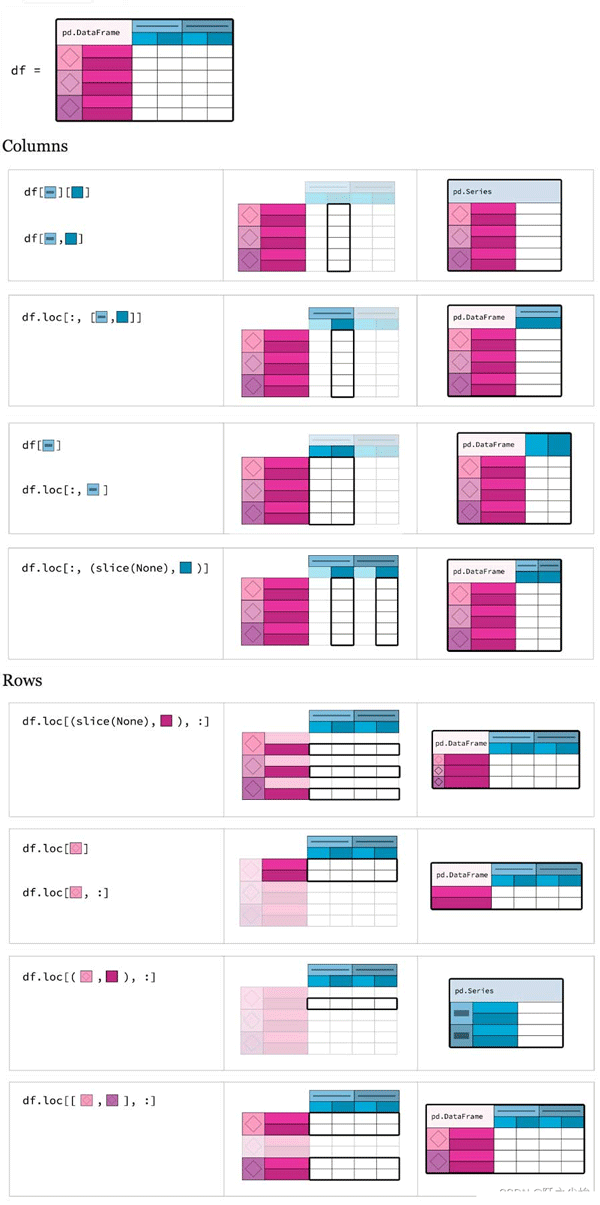
index_arrays = [[1, 1, 2, 2], ['男', '女', '男', '女']]
columns_arrays = [['2020', '2020', '2021', '2021'],
['上半年', '下半年', '上半年', '下半年',]]
index = pd.MultiIndex.from_arrays(index_arrays,names=('班级', '性别'))
columns = pd.MultiIndex.from_arrays(columns_arrays,names=('年份', '学期'))
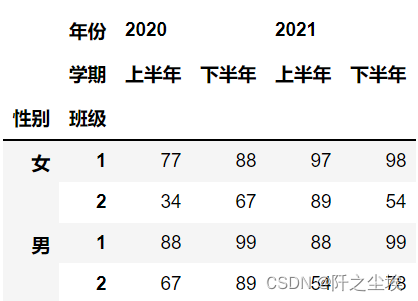
df = pd.DataFrame([(88,99,88,99),(77,88,97,98),
(67,89,54,78),(34,67,89,54)],columns=columns, index=index)
df
索引名称的查看
#索引名称的查看: df.index # 索引, 是一个 MultiIndex df.columns # 引索引,也是一个 MultiIndex # 查看行索引的名称 df.index.names # FrozenList(['班级', '性别']) # 查看列索引的名称 df.columns.names # FrozenList(['年份', '学期'])
索引的层级
#索引的层级: df.index.nlevels # 层级数 2 df.index.levels # 行的层级 # FrozenList([[1, 2], ['女', '男']]) df.columns.levels # 列的层级 # FrozenList([['2020', '2021'], ['上半年', '下半年']]) df[['2020','2021']].index.levels # 筛选后的层级 # FrozenList([[1, 2], ['女', '男']])
索引内容的查看
#索引内容的查看:
# 获取索引第2层内容
df.index.get_level_values(1)
# Index(['男', '女', '男', '女'], dtype='object', name='性别')
# 获取列索引第1层内容
df.columns.get_level_values(0)
# Index(['2020', '2020', '2021', '2021'], dtype='object', name='年份')
# 按索引名称取索引内容
df.index.get_level_values('班级')
# Int64Index([1, 1, 2, 2], dtype='int64', name='班级')
df.columns.get_level_values('年份')
# Index(['2020', '2020', '2021', '2021'], dtype='object', name='年份')
# 多层索引的数据类型,1.3.0+
df.index.dtypes
#排序
# 使用索引名可进行排序,可以指定具体的列
df.sort_values(by=['性别', ('2020','下半年')])
df.index.reorder_levels([1,0]) # 等级顺序,互换
df.index.set_codes([1, 1, 0, 0], level='班级') # 设置顺序
df.index.sortlevel(level=0, ascending=True) # 按指定级别排序
df.index.reindex(df.index[::-1]) # 更换顺序,或者指定一个顺序
相关操作转换:
df.index.to_numpy() # 生成一个笛卡尔积的元组对列表 # array([(1, '男'), (1, '女'), (2, '男'), (2, '女')], dtype=object) df.index.remove_unused_levels() # 返回没有使用的层级 df.swaplevel(0, 2) # 交换索引 df.to_frame() # 转为 DataFrame idx.set_levels(['a', 'b'], level='bar') # 设置新的索引内容 idx.set_levels([['a', 'b', 'c'], [1, 2, 3, 4]], level=[0, 1]) idx.to_flat_index() # 转为元组对列表 df.index.droplevel(0) # 删除指定等级 df.index.get_locs((2, '女')) # 返回索引的位置
数据查询
#查询指定行 df.loc[1] #一班的 df.loc[(1, '男')] # 一年级男 df.loc[1:2] # 一二两年级数据
#查询指定列
df['2020'] # 整个一级索引下
df[('2020','上半年')] # 指定二级索引
df['2020']['上半年'] # 同上
#行列综合 slice(None)表示本层所有内容
df.loc[(1, '男'), '2020'] # 只显示2020年一年级男
df.loc[:, (slice(None), '下半年')] # 只看下半年的
df.loc[(slice(None), '女'),:] # 只看女生
df.loc[1, (slice(None)),:] # 只看1班
df.loc[:, ('2020', slice(None))] # 只看 2020 年的

#查询指定条件
#和单层索引的数据查询一样,不过在选择列上要按多层的规则。
df[df[('2020','上半年')] > 80]
#pd.IndexSlice切片使用:
idx = pd.IndexSlice
idx[0] # 0
idx[:] # slice(None, None, None)
idx[0,'x'] # (0, 'x')
idx[0:3] # slice(0, 3, None)
idx[0.1:1.5] # slice(0.1, 1.5, None)
idx[0:5,'x':'y'] # (slice(0, 5, None), slice('x', 'y', None))
#查询应用:
idx = pd.IndexSlice
df.loc[idx[:,['男']],:] # 只显示男
df.loc[:,idx[:,['上半年']]] # 只显示上半年
#df.xs()
df.xs((1, '男')) # 一年级男生
df.xs('2020', axis=1) # 2020 年
df.xs('男', level=1) # 所有男生
数据分组
df.groupby(level=0).sum() df.groupby(level='性别').sum() df.sum(level='班级') # 也可以直接统计
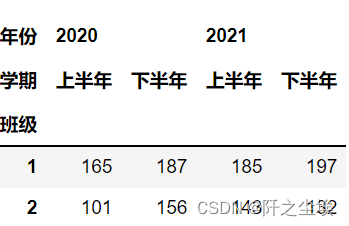
df.groupby(level=['性别', '班级']).sum()
到此这篇关于Pandas数据分析-andas数据框的多层索引的文章就介绍到这了,更多相关pandas多层索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pandas的MultiIndex多层索引使用说明
目录 MultiIndex多层索引 1.创建方式 1.1.第一种:多维数组 1.2.第二种:MultiIndex 2.多层索引操作 2.1.Series多层索引 2.2.DataFrame多层索引 2.3.交换索引 2.4.索引排序 2.5.索引堆叠 2.6.取消堆叠 2.7.设置索引 2.8.重置索引 MultiIndex多层索引 MultiIndex,即具有多个层次的索引,有些类似于根据索引进行分组的形式.通过多层次索引,我们就可以使用高层次的索引,来操作整个索引组的数据.通过给索引分类分组
-
python pandas创建多层索引MultiIndex的6种方式
目录 引言 pd.MultiIndex.from_arrays() pd.MultiIndex.from_tuples() 列表和元组是可以混合使用的 pd.MultiIndex.from_product() pd.MultiIndex.from_frame() groupby() pivot_table() 引言 在上一篇文章中介绍了如何创建Pandas中的单层索引,今天给大家带来的是如何创建Pandas中的多层索引. pd.MultiIndex,即具有多个层次的索引.通过多层次索引,我们就可
-
Pandas 数据框增、删、改、查、去重、抽样基本操作方法
总括 pandas的索引函数主要有三种: loc 标签索引,行和列的名称 iloc 整型索引(绝对位置索引),绝对意义上的几行几列,起始索引为0 ix 是 iloc 和 loc的合体 at是loc的快捷方式 iat是iloc的快捷方式 建立测试数据集: import pandas as pd df = pd.DataFrame({'a': [1, 2, 3], 'b': ['a', 'b', 'c'],'c': ["A","B","C"]}) p
-
Pandas将列表(List)转换为数据框(Dataframe)
Python中将列表转换成为数据框有两种情况:第一种是两个不同列表转换成一个数据框,第二种是一个包含不同子列表的列表转换成为数据框. 第一种:两个不同列表转换成为数据框 from pandas.core.frame import DataFrame a=[1,2,3,4]#列表a b=[5,6,7,8]#列表b c={"a" : a, "b" : b}#将列表a,b转换成字典 data=DataFrame(c)#将字典转换成为数据框 print(data) 输出的结
-
pandas数据框,统计某列数据对应的个数方法
现在要解决的问题如下: 我们有一个数据的表 第7列有许多数字,并且是用逗号分隔的,数字又有一个对应的关系: 我们要得到第7列对应关系的统计,就是每一行的第7列a有多少个,b有多少个 好了,我给的解决方法如下: #!/bin/python #-*-coding:UTF-8-*- import pandas as pd import numpy as np dfidspec = pd.read_table("one.txt")#这个是对应关系的文件 dfmgs = pd.read_tabl
-
在Pandas中给多层索引降级的方法
# 背景介绍 通常我们不会在Pandas中主动设置多层索引,但是如果一个字段做多个不同的聚合运算, 比如sum, max这样形成的Column Level是有层次的,这样阅读非常方便,但是对编程定位比较麻烦. # 数据准备 import pandas as pd import numpy as np df = pd.DataFrame(np.arange(0, 14).reshape(7,2),columns =['a','b'] ) df.a = df.a %3 df['who'] = 'Bo
-
pandas多层索引的创建和取值以及排序的实现
多层索引的创建 普通-多个index创建 在创建数据的时候加入一个index列表,这个index列表里面是多个索引列表 Series多层索引的创建方法 import pandas as pd s = pd.Series([1,2,3,4,5,6],index=[['张三','张三','李四','李四','王五','王五'], ['期中','期末','期中','期末','期中','期末']]) # print(s) s 张三 期中 1 期末 2 李四 期中 3
-
Pandas数据分析-pandas数据框的多层索引
目录 前言 创建多层索引 多层索引操作 索引名称的查看 索引的层级 索引内容的查看 数据查询 数据分组 前言 pandas数据框针对高维数据,也有多层索引的办法去应对.多层数据一般长这个样子 可以看到AB两大列,下面又有xy两小列. 行有abc三行,又分为onetwo两小行. 在分组聚合的时候也会产生多层索引,下面演示一下. 导入包和数据: import numpy as np import pandas as pd df=pd.read_excel('team.xlsx') 分组聚合: df.
-
pandas删除部分数据后重新生成索引的实现
目录 pandas删除部分数据后重新索引 原数据 删除部分数据后 附件:网上查到的格式化用的编码 pandas常用的index索引设置 1.读取时指定索引列 2. 使用现有的 DataFrame 设置索引 3. 一些操作后重置索引 4. 将索引从 groupby 操作转换为列 5.排序后重置索引 6.删除重复后重置索引 7. 索引的直接赋值 8.写入CSV文件时忽略索引 pandas删除部分数据后重新索引 在使用pandas时,由于隔行读取删除了部分数据,导致删除数据后的索引不连续: 原数据 删
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Pandas数据分析之pandas数据透视表和交叉表
目录 前言 整理透视 pivot 聚合透视 Pivot Table 聚合透视高级操作 交叉表crosstab() 数据融合melt() 数据堆叠 stack 前言 pandas对数据框也可以像excel一样进行数据透视表整合之类的操作.主要是针对分类数据进行操作,还可以计算数值型数据,去满足复杂的分类数据整理的逻辑. 首先还是导入包: import numpy as np import pandas as pd 整理透视 pivot 首先介绍的是最简单的整理透视函数pivot,其原理如图: pi